やりたいこと
声からその人がどんな感情なのかを認識できるようにしたいです。
方法
感情の情報が付いた音声データセットに対して、機械学習をして感情認識モデルを作成します。今回は発話内容といった言語情報は一切使わず、音声データの音響的な特徴のみを使用して感情を認識します。
音声データ
日本声優統計学会という同人活動を行っているサークルが出している声優統計コーパスを使わせていただきます。
声優統計コーパスは3人の女性声優が
- 通常(normal)
- 喜び(happy)
- 怒り(angry)
の3感情の音声を100発話ずつ収録したデータセットです。つまり、合計900発話が収録されています。
形式はWAVファイルであり、ファイル名は 「[声優名]_[感情]_[番号].wav」 のようになっています。
音響的な特徴の抽出
今回使用する音響的な特徴は13次元のMFCC(メル周波数ケプストラム係数)のみです。MFCCは簡単に説明すると音声で伝わる声道の特徴を人間の聴覚に合わせて表した特徴量です。詳細については省きます。
MFCCの各次元はフレーム(〇ミリ秒)ごとに抽出されます。今回、MFCCは1発話内で次元ごとに平均した値を使用します。つまり、1発話を表す音響的な特徴は各フレームでMFCCが13次元なため、その次元ごとの平均を取った13種類になります。
import numpy as np
import glob
import librosa
def get_label(path): #感情ラベルを数値に変換
label_name = path.split("/")[-1].split("_")[1] #ファイル名から感情を取得
if label_name == "normal":
label = 0
elif label_name == "happy":
label = 1
elif label_name == "angry":
label = 2
else: #想定外の値用
label = -1
return label
paths = glob.glob("[PATH]/声優統計コーパス/*/*.wav") #音声ファイルのパスを取得
feature_list = [] #音響的な特徴を格納するリスト
label_list = [] #正解データを格納するリスト
for path in paths:
y, sr = librosa.load(path, sr=16000) #音声ファイルの読み込み
mfcc = librosa.feature.mfcc(y=y,sr=sr,n_mfcc=13) #MFCCを取得
feature_list.append(np.mean(mfcc, axis=1))#各次元の平均を取得
label = get_label(path)
label_list.append(label)
感情認識モデルの作成
学習データはできましたので、後は前処理して学習するだけです。使用する分類アルゴリズムはSVM(サポートベクターマシン)の線形カーネルです。scikit-learnを使って実装していきます。
まず、学習データとテストデータの分割します。
from sklearn.model_selection import train_test_split
Y_train, Y_test, X_train, X_test = train_test_split(label_list, feature_list, test_size=0.3)
次に前処理として標準化します。
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train_std = sc.fit_transform(X_train)
X_test_std = sc.fit_transform(X_test)
そして、学習です。
from sklearn.svm import LinearSVC
svm = LinearSVC()
svm.fit(X_train_std, Y_train)
感情認識モデルの評価
from sklearn.metrics import accuracy_score
Y_pred_train = svm.predict(X_train_std)
Y_pred_test = svm.predict(X_test_std)
train_accuracy = accuracy_score(Y_train, Y_pred_train)
test_accuracy = accuracy_score(Y_test, Y_pred_test)
print("Train accuracy: {}%, Test accuracy: {}%".format(train_accuracy, test_accuracy))
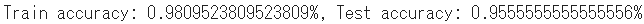
認識モデルの精度はテストセットで 約95.6% でした。適切な分類アルゴリズムの選定やハイパーパラメータのチューニング等をしっかり行えば100%はいけると思います。
混同行列は以下の通りです。
from sklearn.metrics import confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
cm = confusion_matrix(Y_test, Y_pred_test)
cm = pd.DataFrame(data=cm, index=["normal", "happy", "angry"], columns=["normal", "happy", "angry"])
sns.heatmap(cm, square=True, cbar=True, annot=True, cmap='Blues')
plt.xlabel("Predict")
plt.ylabel("True")
plt.title("Emotion Prediction Result")
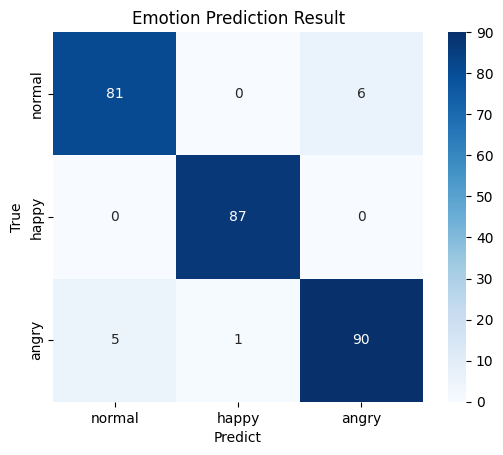
縦軸が正解ラベルで横軸が予測ラベルです。正解ラベルが通常なのに怒りと誤認識している音声が6発話ありますね。普通に話しているのに怒っていると思われるパターンですかね。
まとめ
今回は音声から音響的な特徴を抽出して分類モデルを学習させることで3感情を認識することができました。
音声感情認識のトレンドは本記事のように音響的な特徴を抽出するのではなく、音声波形を直接ニューラルネットワークに渡して学習することのようです。しかし、3感情の強調された感情を表現している音声でしたら、今回の方法でも十分ですね。