こんにちは!
今回は,現代疫学(原著:Modern Epidemiology 4th edition)の輪読会を去年から始めて約1年経ちましたので,その経過をまとめたいと思います.
現代疫学は,疫学における研究に関わる諸知識(因果推論フレームワーク,研究デザイン,データ解析とその実践)を1冊にまとめた内容となっており,総数1332ページにも及ぶ鈍器成書となっています.
これくらいのボリュームだと1人で読みきることが難しいので,仲間内で輪読会をやって楽に効率的に読み進めましょう!というお話になりました.
輪読会に参加したメンバー
輪読会といっても,身内で行うゆるい読み合わせ会です.
基本的には医療従事者であり,非ITエンジニア,統計学やプログラミングに対する理解はバラバラですが,やる気だけはあるメンバーの会です.
Aさん(仮名)
・理学療法士
・大学院博士課程修了
・統計検定準1級持ち
・英語論文を何本か書いている
・R/Pythonは実務で使用/コーディング自体に抵抗はない
Bさん
・理学療法士
・大学院修士課程修了
・統計検定2級持ち
・論文執筆経験なし
・コーディング経験なし/興味はある
Cさん
・理学療法士
・大学院博士課程修了
・現職は臨床現場ではなく,公衆衛生系の教員で現場に出てデータ収集,データ管理がメイン
・論文執筆経験は英語論文1-2本
・コーディングは生成系AIに下書きしてもらうレベル
こんな感じのメンバーで輪読会を進めています.
使用したツール
1. Slack
みんなだいすきSlack
主に輪読会の日程調整と質問・ディスカッション目的で使用しました.
2. Discord
輪読会のミーティングツールとして使用しました.
無料で長時間通話可能,画面共有しても画質が綺麗なので重宝しています.
3. Google Drive
発表資料ファイルの共有に使用しました.
基本的には,スライド,論文,スクリプトの電子ファイルを共有フォルダに入れて共有しています.
4. R (CRAN) + Rstudio
現代疫学の内容として,実際のデータを提示して統計量を計算したりすることが多かったので,その検算やグラフィック描画などにRとRstudioを用いています.
輪読会の進め方
現代疫学は4部構成で各部に章があり,全部で43章の構成になっています.
基本的に1人1章で担当をまわしていきます.担当となった章を担当者が読み込み,発表資料にまとめて,発表,という形です.
発表形式は,スライドで資料を作成し,スライドの読み合わせを行います.
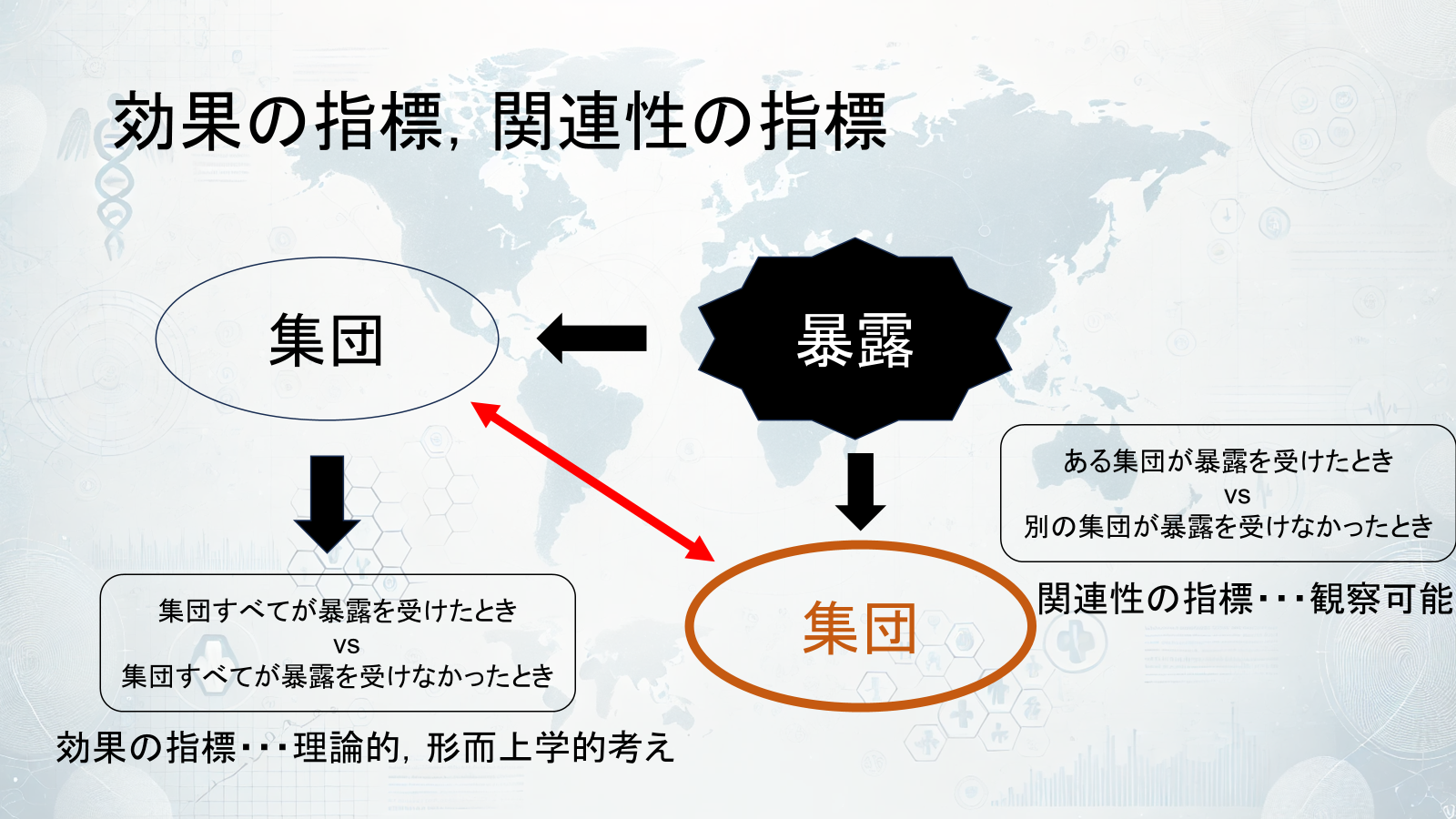
こんな感じでわかりやすく図にまとめたり
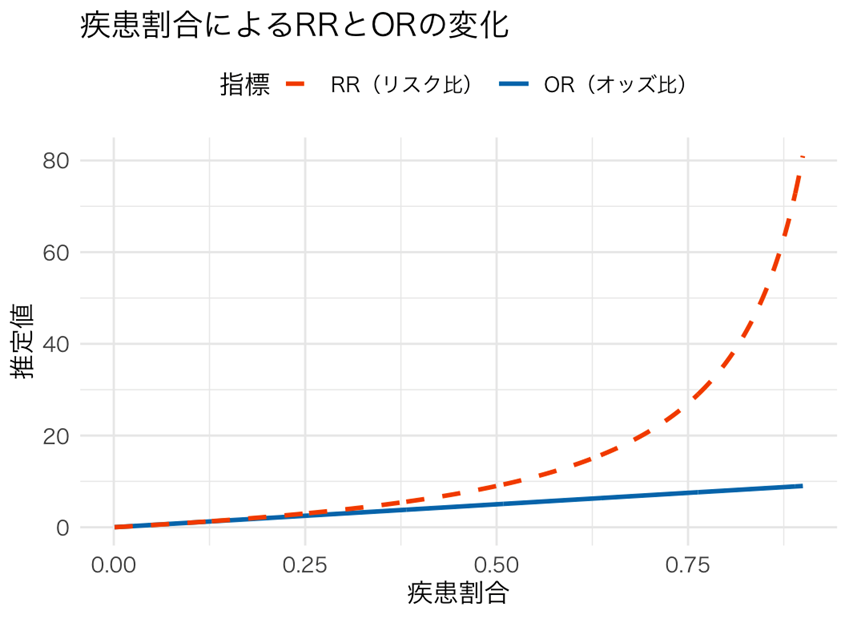
Rを使って,シミュレーションしてみたり(疾患割合が変化するとRRとORが乖離していくよ!)
輪読会を行うにあたって決めたルール
輪読会のメンバーは,疫学や統計学の専門家というわけでもなく,理解にバラつきがあることは前提であったため,自分なりに読み込んで理解した内容を資料にまとめる,というルールにしました.
分からない点やディスカッションしたい点はあとでまとめるか,Slackにあげてお話しするというスタンスにしました.
メンバー全員がフルタイムで働く人たちなので,輪読会は月1-2回を目安に,業務前の朝か夕方夜に1回20-30分程度を目安に行います.
輪読会の進捗
輪読会は2024年6月からスタートしました(現代疫学の発売日が2024年5月なので,スタートは結構はやいですね).
途中で各々のライフイベント(特に大学院修了とか)があったので,小休止を挟むことはありましたが,解散することなく続いています.
2025年9月現在は第III部 データ解析の「第17章 カテゴリーデータに対する統計入門」まで進みました.
えっ,1年も経ってるのにまだ半分いってないやん!!
そうなんです.章構成でいうと,全43章中の17章なので,進捗状況は4割程度です.
理由はいくつかあります.
1. 内容が難しい
疫学といっても章によっては統計学・因果推論のコアをガッツリ扱います.肌感では,統計検定準1級レベルのトピックが多いです.メンバーによっては理解が及ばないところが多数存在し,担当した章の読み込みや資料作成に時間を要することが大きい原因になっています.
そこで,補足して理解するために,勉強会を間に挟んでいます.

例えばこんな感じ.現代疫学にて測定誤差や未測定交絡に対するSensitivity analysisが触れられていましたが,実際はどうやるの?という疑問を解消するべく,研究論文を取り上げて実践例1を見てみましょうという勉強会がありました.
こういった形で,輪読会+補足的勉強会の運用を行っているためスローペースです.
2. 生成系AIの弊害
1の内容と少し重複しますが,本書の読み込みや理解に時間がかかるというところで,資料作成を生成系AI(ChatGptなど)を用いて行うメンバーもいます.
生成系AIの利用自体は特にルール上禁止もしていないため,利用はご自由に,というスタンスなのですが,どうしても発表内容が「薄っぺらく機械的に要約したもの」になりがちです.生成系AIを部分的に利用し,発表資料を作成していけば問題ないです.しかし,どうしても難解な部分を生成系AIに丸投げして,出てきたメッセージをそのままスライドに貼り付け,ということがありました.
例えば,「サンプルサイズの設計」というテーマがあったとします.
サンプルサイズの設計に必要なものは,効果量(Effect size)や有意水準(α),検出力(Power),時間や資金など実現可能性があがりますが,そんなものは本書を見るまでもなくググれば一発で教えてくれます.
輪読会において大事だと思っているのは,正しい知識の取得ではなく,様々なバッググラウンドをもった輪読会メンバーがどのような足跡で担当した章を理解したか,という点であると思います.
もっと砕いてしまえば,サンプルサイズの設計って,効果量などの各要素は知ってるけど,それが数学的にどのように構成されてるか知らなかったから,まとめてみたよ,という未知に対する自身なりにかみ砕いた理解を示す場が輪読会であると考えています.もちろん理解できなくても問題ありません.頑張って読み込んだけど,ここがわからんかった,という単に未知を示す場でもよいと思います.
章が深まるにつれ,未知で難解な内容となりますが,生成系AIに丸投げはせずなるべく自分で咀嚼する,ということを都度メンバー間で認識を共有しています.必要であれば一度立ち止まって,補足的勉強会を行うのも良し,Slackでディスカッションするのも良しです.
これから
そんなわけで,まだ1300ページの山どころか500ページ弱も進んでいない(第17章まで)状況ですが,のんびり面白くやっています.
やっぱりアウトプットって正義ですね.研究となると原著論文の出版に目が向きがちですが,こうした輪読会(身内だけでも)も教育・研究面ではとても大事ですね.
もし,興味ある方いましたら,輪読会のスライド共有できますので,ご連絡ください.
この記事からみなさんへなにか刺激を与えることができたら幸いです.
今回はここまで.またの機会に.
-
理解を深めるために大事なことですが,なるべく数式からは逃げないことです.一時的に粗く理解するのも良いですが,いずれ実践の場になったら数式と向かい合うことになります.時間はいくらかかってもいいので数式を積極的に使いましょう. ↩