背景
任意のサイトのWeb記事全部欲しい.
けどそのリンクをいちいち用意するのは面倒.
なのでサイトの木構造を辿るスクレイピングボットを作ったという話.
もともとは知り合いからこれを作って欲しいと頼まれたことが作ったきっかけ.
多分,自然言語処理分析か何かに利用したいのだと思う.(word2vecとか頻度計算,クラスタリングとか?)
機能
ユーザログインの必要なウェブサイトからサクッとページ情報を取得できます

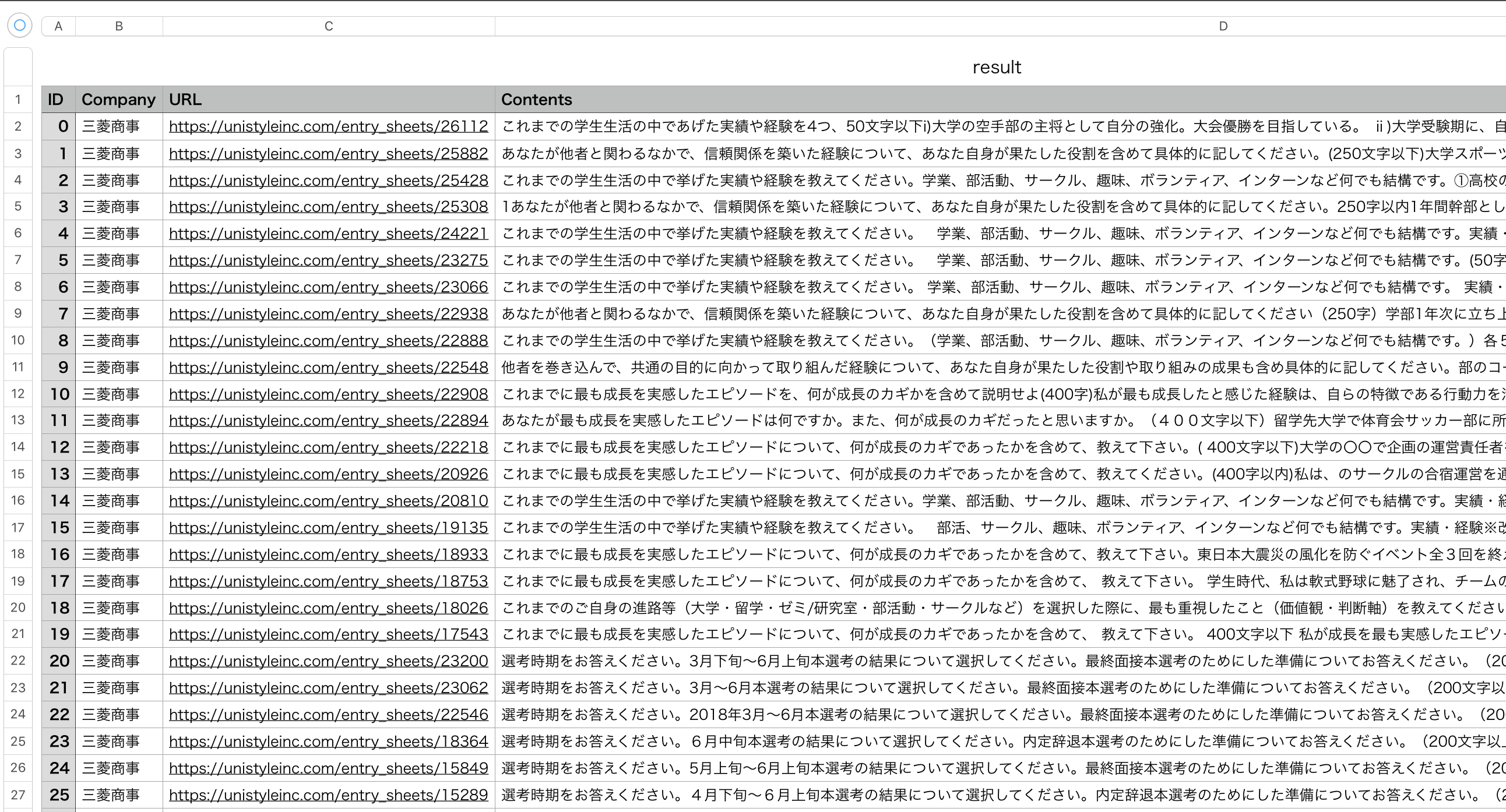
この例では,各企業ごとに用意された就活のESやOB訪問といったページ情報を取得して以下のようにCSVで保存しました.(すごい数あったので,time.sleep(1)入れて6時間程かかりました.)
アルゴリズム
主に木構造を辿ってっただけです
| 1 | Chromedriver起動 |
| 2 | ユーザログイン |
| 3 | 業界カテゴリ一覧から業界ごとのURLを取得 |
| 4 | 取得した業界ごとのURLから各企業ごとのURLを取得 |
| 5 | 各企業ごとのURLかから各ページURLを取得 |
| 6 | 取得したページURL集合から中身をスクレイピング |
コード
# coding:utf-8
PURPLE = '\033[35m'
RED = '\033[31m'
CYAN = '\033[36m'
OKBLUE = '\033[94m'
OKGREEN = '\033[92m'
WARNING = '\033[93m'
FAIL = '\033[91m'
ENDC = '\033[0m'
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
from bs4 import BeautifulSoup
from extractcontent3 import ExtractContent
##### ExtractContent(only fetch contents)########
def extractor(html):
extractor = ExtractContent()
opt = {"threshold":50}
extractor.analyse(html)
text, title = extractor.as_text()
return text
email = 'Please input your E-mail address'
password = 'Please input your password'
LOGIN_URL= 'https://unistyleinc.com/'
# Log in
b = webdriver.Chrome('./chromedriver')
b.get(LOGIN_URL)
b.find_element_by_id('LoginLink').click()
b.find_element_by_name('user[email]').send_keys(email)
b.find_element_by_name('user[password]').send_keys(password)
b.find_element_by_class_name('login_submit').click()
# Move to categories
time.sleep(1)
b.get('https://unistyleinc.com/categories')
category = b.find_element_by_class_name('es_category_list')
a = category.find_elements_by_css_selector("a")
dict_category = {}
for i in a:
name = str(i.text.replace('>',''))
URL = str(i.get_attribute("href"))
print (name+'--->'+OKBLUE+URL+ENDC)
dict_category[name]=URL
# Move to company from the category
dict_company = {}
for name in dict_category:
URL = dict_category[name]
b.get(URL)
time.sleep(1)
companies = b.find_element_by_class_name('essearch_common_wrap')
a = companies.find_elements_by_css_selector("a")
for i in a:
company = str(i.text.split(' ')[0])
URL = str(i.get_attribute("href"))
if URL != 'https://unistyleinc.com/categories':
dict_company[company] = URL
print (company+'--->'+OKGREEN+URL+ENDC)
# Move to (ES/interview/OB visit etc...)page from company URL
W = open('result.csv','w')
W.write('ID,Company,URL,Contents\n')
dict_com_url = {}
for company in dict_company:
URL = dict_company[company]
b.get(URL)
time.sleep(1)
list_ES = b.find_elements_by_class_name('es_container')
for i in list_ES:
a = i.find_element_by_css_selector("a")
url = str(a.get_attribute("href"))
print (company+'--->'+PURPLE+url+ENDC)
dict_com_url.setdefault(company, []).append(url)
# Save contents
num=0
for key in dict_com_url:
list_URL = dict_com_url[key]
for URL in list_URL:
try:
b.get(URL)
time.sleep(1)
html = b.page_source
text = extractor(html)
text = text.replace(',',' ').replace('\n',' ').replace('\t','').replace('\r','')
print (key+'--->'+PURPLE+URL+ENDC)
print (text[:100]+'...')
W.write(str(num)+','+key+','+URL+','+text+'\n')
except:
print ('request error')
num+=1
W.close()
使ったモジュール
・Selenium
・ExtractContent3
Github