AI エージェントが数百〜数千のツールを扱う時代が近づいている。IDE アシスタントが git、ファイル操作、パッケージマネージャ、テストフレームワーク、デプロイパイプラインを統合し、運用コーディネーターが Slack、GitHub、Google Drive、Jira、社内 DB、複数の MCP サーバーを同時に接続する世界になりつつある。
しかし従来の tool use には3つのボトルネックがある。
- ツール定義によるコンテキスト圧迫 - 全定義を事前に読み込むと、会話前にトークンが枯渇する
- 中間結果によるコンテキスト汚染 - 各ツール呼び出しの結果がすべて蓄積される
- スキーマだけでは正しい使い方がわからない - JSON Schema は構造を定義するが、使用パターンは表現できない
Anthropic は 2025年11月、これらを解決する3つの beta 機能をリリースした。本記事ではそれぞれの設計と実装を見ていく。
https://www.anthropic.com/engineering/advanced-tool-use
Tool Search Tool
問題の実態
MCP サーバーを複数接続すると、ツール定義だけで大量のトークンを消費する。
| サーバー | ツール数 | トークン数 |
|---|---|---|
| GitHub | 35 | ~26K |
| Slack | 11 | ~21K |
| Sentry | 5 | ~3K |
| Grafana | 5 | ~3K |
| Splunk | 2 | ~2K |
| 合計 | 58 | ~55K |
5サーバーで約55Kトークン。Jira(~17K)を追加すれば100K超になってしまう。Anthropic 社内では最適化前に134Kトークンを消費していた事例もあるらしい。
トークンコストだけでなく、類似名のツール(notification-send-user vs notification-send-channel など)による選択ミスも頻発する。
解決策:オンデマンド検索
Tool Search Tool は、全ツール定義を事前に読み込むのではなく、Claude が必要としたときに検索して該当ツールだけを取得する仕組みだ。初期状態では検索ツール自体(約500 tokens)だけがコンテキストに存在し、残りは遅延読み込みされる。
{
"tools": [
{"type": "tool_search_tool_regex_20251119", "name": "tool_search_tool_regex"},
{
"name": "github.createPullRequest",
"description": "Create a pull request",
"input_schema": {"...": "..."},
"defer_loading": true
}
]
}
defer_loading: true を指定したツールは初期コンテキストに含まれない。Claude が GitHub 操作を必要としたとき、検索して該当ツールだけを読み込む。
MCP サーバー単位での設定も可能。
{
"type": "mcp_toolset",
"mcp_server_name": "google-drive",
"default_config": {"defer_loading": true},
"configs": {
"search_files": {"defer_loading": false}
}
}
効果
従来方式と Tool Search Tool のコンテキスト使用量を比較すると、その差は歴然としている。
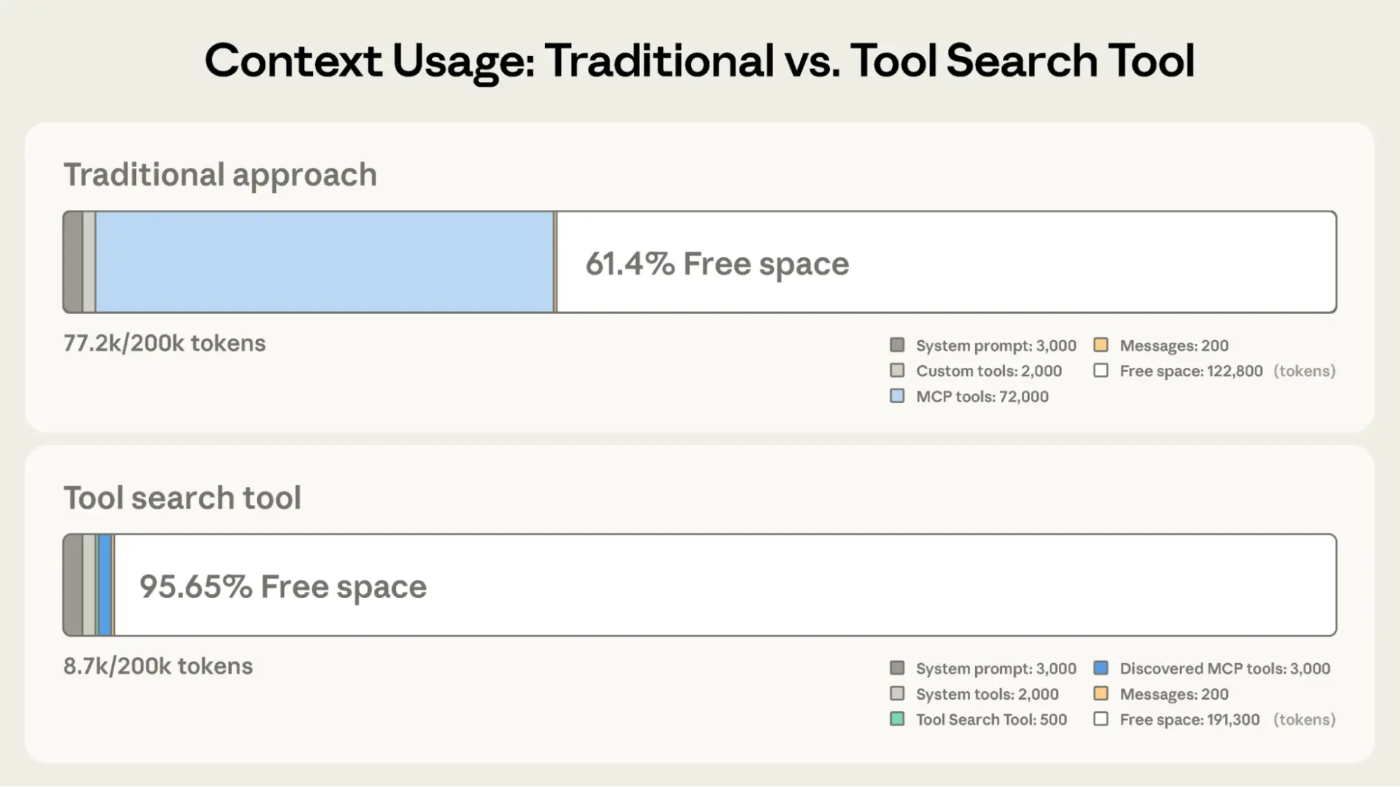
従来は MCP ツール定義だけで 72,000 tokens を消費し、200K のコンテキストのうち 61.4% しか空きがない。Tool Search Tool では初期消費が 8.7K tokens に抑えられ、95.65% が自由に使える。
| 指標 | 従来 | Tool Search Tool |
|---|---|---|
| 初期トークン消費 | ~77K | ~8.7K |
| 削減率 | - | 85% |
| Opus 4 精度 | 49% | 74% |
| Opus 4.5 精度 | 79.5% | 88.1% |
Programmatic Tool Calling
問題の実態
10MB のログファイルを解析してエラーパターンを抽出する場合、従来はファイル全体がコンテキストに入ってしまう。必要なのはエラー頻度のサマリーだけなのに。
また、各ツール呼び出しごとに推論パスが発生し、中間結果を自然言語で解釈・合成する必要がある。5回のツール呼び出しなら5回の推論パス。
解決策:コードによるオーケストレーション
Programmatic Tool Calling(PTC)は、Claude がツールを1つずつ呼び出すのではなく、Python スクリプトを生成してまとめて実行する仕組みだ。
従来方式では、各ツール呼び出しのたびに結果が Claude のコンテキストに返される。PTC では、スクリプトがサンドボックス内で実行され、ツール結果はスクリプト内で処理される。Claude のコンテキストに入るのは print() した最終出力だけ。
以下のシーケンス図が全体の流れを示している。
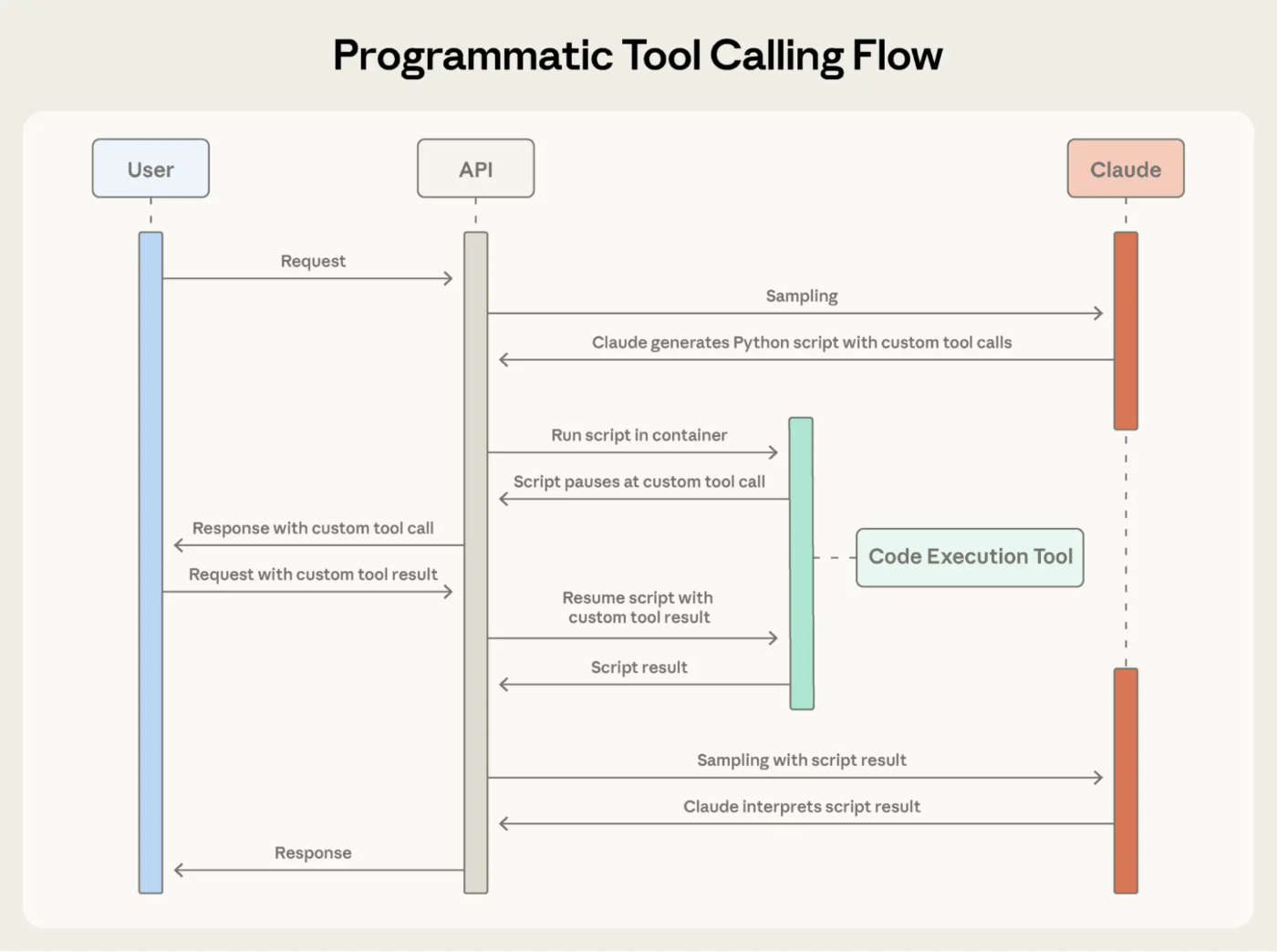
Claude が Python スクリプトを生成し、Code Execution Tool 内で実行される。スクリプトがカスタムツールを呼び出すと一時停止し、API 経由でユーザー側にリクエストが送られる。結果が返ると実行が再開され、最終的なスクリプト結果のみが Claude に返される。
具体例として「Q3 の出張予算を超過したチームメンバーを特定する」タスクを考えてみる。
従来方式:
リクエスト → 推論 → get_team_members → 結果がコンテキストへ
→ 推論 → get_expenses(社員1) → 結果がコンテキストへ
→ 推論 → get_expenses(社員2) → 結果がコンテキストへ
→ ...(20回繰り返し)
→ 推論 → get_budget_by_level → 結果がコンテキストへ
→ Claude が全データを見て計算・回答
20回のツール呼び出しで2000件以上の経費レコードがコンテキストに蓄積し、それを自然言語で解釈して計算する。
PTC:
リクエスト → 推論(1回)→ Python スクリプト生成
↓
スクリプトが get_team_members 呼び出し → 結果はスクリプトへ
スクリプトが get_expenses x20(並列)→ 結果はスクリプトへ
スクリプトが get_budget_by_level 呼び出し → 結果はスクリプトへ
スクリプト内で計算・フィルタ
↓
print() した最終結果だけがコンテキストへ
Claude が見るのは「超過者:Alice, Bob」だけ。中間データは一切コンテキストに入らない。
実装
ツールに allowed_callers を指定して PTC を有効化する。
{
"tools": [
{"type": "code_execution_20250825", "name": "code_execution"},
{
"name": "get_expenses",
"description": "Get expense records for a user",
"input_schema": {"...": "..."},
"allowed_callers": ["code_execution_20250825"]
}
]
}
Claude が生成するオーケストレーションコード例:
team = await get_team_members("engineering")
levels = list(set(m["level"] for m in team))
budget_results = await asyncio.gather(*[
get_budget_by_level(level) for level in levels
])
budgets = {level: budget for level, budget in zip(levels, budget_results)}
expenses = await asyncio.gather(*[
get_expenses(m["id"], "Q3") for m in team
])
exceeded = []
for member, exp in zip(team, expenses):
total = sum(e["amount"] for e in exp)
if total > budgets[member["level"]]["travel_limit"]:
exceeded.append({
"name": member["name"],
"spent": total,
"limit": budgets[member["level"]]["travel_limit"]
})
print(json.dumps(exceeded))
コード内のツール呼び出しには caller フィールドが付与され、結果はコード実行環境で処理される。Claude のコンテキストには最終出力のみが返る。
効果
- トークン消費:43,588 → 27,297(37%削減)
- 並列実行による推論パス削減
- 知識検索精度:25.6% → 28.5%
- GIA ベンチマーク:46.5% → 51.2%
Tool Use Examples
問題の実態
JSON Schema は構造的な妥当性を定義するが、以下の疑問には答えられない。
-
due_dateは"2024-11-06"か"Nov 6, 2024"か"2024-11-06T00:00:00Z"か? -
reporter.idは UUID か"USR-12345"か? -
escalationパラメータはいつ使うべきか?
解決策:具体例で使い方を示す
JSON Schema だけでは「構造的に正しい」ことしか保証できない。input_examples を使えば、実際の呼び出しパターンを Claude に見せることができる。日付形式、ID の命名規則、どのパラメータをいつ含めるかなど、暗黙の規約を具体例から学習させる。
{
"name": "create_ticket",
"input_schema": {"...": "..."},
"input_examples": [
{
"title": "Login page returns 500 error",
"priority": "critical",
"labels": ["bug", "authentication", "production"],
"reporter": {"id": "USR-12345", "name": "Jane Smith"},
"due_date": "2024-11-06",
"escalation": {"level": 2, "notify_manager": true, "sla_hours": 4}
},
{
"title": "Add dark mode support",
"labels": ["feature-request", "ui"],
"reporter": {"id": "USR-67890", "name": "Alex Chen"}
},
{
"title": "Update API documentation"
}
]
}
3つの例から Claude は以下を学習する:
- 日付は YYYY-MM-DD 形式
- ユーザー ID は USR-XXXXX 形式
- critical バグはフル情報 + escalation、feature request は reporter のみ、内部タスクは title のみ
効果
複雑なパラメータ処理の精度:72% → 90%
各機能は異なるボトルネックを解決する。
| 機能 | 解決するボトルネック | 導入の目安 |
|---|---|---|
| Tool Search Tool | ツール定義の肥大化 | 定義が10K+ tokens、10+ツール |
| Programmatic Tool Calling | 中間結果の蓄積 | 大量データ処理、3+回の依存呼び出し |
| Tool Use Examples | パラメータの曖昧さ | 複雑なネスト構造、ドメイン固有規約 |
最大のボトルネックから着手し、必要に応じて組み合わせていくのが実践的だろう。
API 使用例
client.beta.messages.create(
betas=["advanced-tool-use-2025-11-20"],
model="claude-sonnet-4-5-20250929",
max_tokens=4096,
tools=[
{"type": "tool_search_tool_regex_20251119", "name": "tool_search_tool_regex"},
{"type": "code_execution_20250825", "name": "code_execution"},
{
"name": "your_tool",
"description": "...",
"input_schema": {"...": "..."},
"defer_loading": True,
"allowed_callers": ["code_execution_20250825"],
"input_examples": [{"...": "..."}]
}
]
)
所感
これら3機能に共通するのは「コンテキスト効率」という設計思想。ツール定義、中間結果、使用パターンのそれぞれでコンテキストの無駄を削減し、エージェントが本来の推論に集中できる環境を整えている。
エージェント開発において、単にツールを増やすだけでなく、いかに効率的にアクセスさせるかが重要になってきているのではないかと思う。