はじめに
スマートスピーカー隆盛の候、皆様いかがお過ごしでしょうか(1か月ぶり3回目)。
昨年12月以来、Raspberry Pi3上でのAssistant並行動作ばかりやり込んでいて、もう『スマートスピーカー並行動作芸人』とでも名乗ろうかと思ったりしている昨今でございます。
昨日発表されたところによると、とうとうAmazon Echoが日本国内で一般販売されることになり、この一連の記事を書く原動力となったAmazon Echoへの渇望を味わうことなく、普通の人も手に入れられるようになりました。何よりでございます。
とはいえ、両Assistantが並行動作するフットプリントの小さい製品は当面あまり見当たらず、表題のようなことも考えていたので、またしても標準のSDKから少し足を伸ばしてモノを作ってみることにしました。
お約束
ここで提供されるコードや情報については一切無保証で、特にサポートもしませんので、ご自身の責任においてのみご利用ください。
転んでも自分の力で立ち上がる覚悟のある方だけ、この先の情報をご利用ください。
成果物
実はもうGitHubに上げていましてですね。
作り方は(ヘッタクソな英語で恐縮ですが)GitHub上に書いてあるので、ここではモチベーションとメカニズムメインで触れようかと思っています。
今回はリポジトリフォークではなく、古式ゆかしくパッチ方式+sedによるコード書き換えで作ってみました。
アイディア先行でリリースしたので、完成度は期待しないでください。お気づきの点があれば適宜どうぞ。
モチベーション
前回の記事でそこそこ見栄えのするスマートスピーカーを作ってしまったので、ここで終わりにしても良かったのですが。
こんなことを考えてしまったのです。
- ReSpeaer公式のLED表示パターンより見劣りする
アニメーションしないのでちょっと寂しい。前回の成果物はCベースだったので、Pythonの公式配布物と比較して触りづらいという点もありました。
また、どうせアニメーションさせるなら、公式のパターンそのまま使えないかなぁ、と。
- googlesamples-assistant-hotword(hotword)の録音範囲
Google Assistantを使っていると、Assistantに話しかけた音声をAssistantアプリから確認することができるんですが、hotwordだと、『Hey Google!』の前から録音されていたんですよね。ずーっと録音されている、というのが多少気になりまして1。wake wordに対応させつつ、wake upした時だけ録音するようなメカニズムにできないかなぁと思っていました。
- Raspberry Pi Zeroでwake word付き並行動作できたら面白い
実は、今年の1月の段階でRaspberry Pi Zeroでwake word付きAlexaを試してはいたのです2。
当時はReSpeaker 2-Micを持っていなかったので、Raspberry Pi3をメインに自分の需要を満たすことを優先していましたが、前回の記事でRaspberry Pi3+ReSpeaker 4-Micで見栄えのするものができてしまったので、せっかくだから余った2-MicとZeroで並行動作させてみるかな、と。
Pi Zeroで動かすだけなら従来の方法でそのまま並行動作させてもよかったんですが、前2者の問題を見ながら、ちょっと思いついたアイディアがあったので、試してみることにしました。
Wakeword Engineの独立
前2者の問題には、実はこんな特徴があって。
- ReSpeaker公式のLEDパターンはPythonコード
- HotWordではなくPushToTalkを使うとwake word前後ではなく、Enterキーを押してからの音声しか録音されてない
であれば、
- Assistantの状態をPythonコードで受け取れば、ReSpeaker公式コードの呼び出しは容易
- wake wordを別モジュールで受けてPushToTalkを呼び出せば録音範囲を制限できる
ってことになります。
また、hotwordは公式ページの記述通り、Raspberry Pi Zeroでは動作しません。動くのはgrpcベースで動いているPushToTalkだけです。
となると、Raspberry Pi Zeroで動作するWakeword Engineを持ってきて、そこからPushToTalkを叩けば、Raspberry Pi ZeroでもGoogle Assistantをwake word付きで動かせる、ってことになります。
Google Assistant単体については、GassistPi等、海外では実現済みの構成だったんですが、Alexaとの並行動作やReSpeakerの駆動を考えると、以下のような構成にした方が何かと都合がいいのでは、と思ったのです。
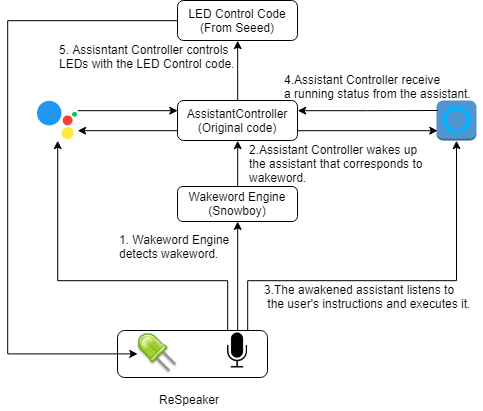
- 両Assistantから独立したWakeword Engine(Snowboy)を使ってwake wordを捕まえつつ
- wake wordに対応したAssisantを識別し、対応するAssistantを起動し
- 以降はマイクからの音声を各Assistantが個別に聴取し動作
- Assistantは動作状態(Listening, Thinking, Speaking, Finished)を都度伝達し
- 伝達された動作状態に応じてLEDの動作を変える
という仕組みです。
Snowboyは複数のwake wordを同時に待ち受けることができ、かつRaspberry Pi Zeroでも動作可能です。
あとはSnowboyとLED制御用コードをコントロールするためのコードを自分で書けば、この構成で行けそうだなぁと思いました。
Assistantの状態通知手段
この構成で考えないといけないのは、『どうやってAssistantと自作のコード間で状態通知を行うか』ということでした。
パイプとかいろいろ考えたんですが、今回はこんなものを見つけたので使ってみることにしました。
POSIXメッセージキューです。Linuxのプロセス間通信にはあまり詳しくないんですが、なかなかよさそうだなと。
各Assistantへの授受処理組み込み
Alexa
最初はユーザからの入力の代わりにメッセージキュー処理を実装しようかと思ったんですが(UserInputManager.cpp)、Device SDKのクラス構成上、DialogUXStateObserverInterfaceクラスを継承することで、Alexaの状態を通知してもらえることが分かったので、独立したクラス(PosixQueue)として組み込むことにしました。
AlexaはGoogle Assistantと違って、設定変更がUserInputManagerで提供されるキー入力経由なので、UserInputManagerを変更してしまうと設定変更できなくなってしまいますが、別クラスで実装したので設定変更機能をつぶさずに実現しています。
class PosixQueueManager : public avsCommon::sdkInterfaces::DialogUXStateObserverInterface {
public:
void onDialogUXStateChanged(DialogUXState newState) override;
m_posixQueueManager = alexaClientSDK::sampleApp::PosixQueueManager::create(interactionManager);
client->addAlexaDialogStateObserver(m_posixQueueManager);
これで、Alexaの状態が変わるタイミングでonDialogUXStateChangedが呼び出されるようになるので、
void PosixQueueManager::onDialogUXStateChanged(DialogUXState newState){
switch (newState) {
case DialogUXState::IDLE:
if(m_previousState != DialogUXState::IDLE){
send(finish,strlen(finish));
}
m_previousState = newState;
break;
case DialogUXState::LISTENING:
m_previousState = newState;
break;
case DialogUXState::THINKING:
send(think,strlen(think));
m_previousState = newState;
break;
…
のように書いておくと、状態変化が起こるたびにこのロジックが実行されます。
Sendメソッドは指定したqueueに指定した文字列を送信する処理になっていて、
void PosixQueueManager::send(const char *buff,ssize_t len){
mq_send(m_AssistantControlQueue,buff,len,0);
return;
}
送信先となるキューはコンストラクタで定義しています。このキューを使ってAlexaはAssistantControllerに状態を通知します(ちなみに後述するGoogle Assistantも同じキューを使っています)。
PosixQueueManager::PosixQueueManager(std::shared_ptr<InteractionManager> interactionManager) : m_interactionManager{interactionManager} {
m_AssistantControlQueue = mq_open("/AssistantsControlQueue",O_RDWR | O_CREAT , S_IRUSR | S_IWUSR ,NULL);
一方、Alexaもwake word検出時に通知を受けられないといけないので、受信するためのキューを別途作っていて、
m_AlexaQueue = mq_open("/AlexaQueue",O_RDWR| O_CREAT ,S_IRUSR | S_IWUSR , NULL);
別途定義したRunメソッドに待ち受け処理を書きつつ、Runメソッドだけ別スレッドで実行するようにSampleApplication.cppを書き換えています。
void PosixQueueManager::run() {
char buff[256] = {0};
while (true) {
receive(buff);
if(!strcmp(buff,"wakeup")){
m_interactionManager->tap();
}
}
}
void SampleApplication::run() {
…
executor.submit([this]() { m_posixQueueManager->run(); });
}
あとはSampleAppのビルド時にWakeword Engineを組み込まないようにビルドすればOK。こうしないと勝手に起きてしまいますからね。
Google Assistant
こっちはPushToTalkを基本として、キーボード入力待ちをQueue待ちにしつつ、レスポンスを受け取る箇所にQueue送信処理を追加しています。
Google Assistantの設定はコマンドラインオプションかスマホアプリ経由なので、キー入力を置き換えても特に問題ありません。
while True:
msg = google_mq.receive()
continue_conversation = assistant.assist()
asssitantControl_mq.send('finish')
for resp in self.assistant.Assist(iter_assist_requests(),
self.deadline):
assistant_helpers.log_assist_response_without_audio(resp)
if resp.event_type == END_OF_UTTERANCE:
logging.info('End of audio request detected')
self.conversation_stream.stop_recording()
asssitantControl_mq.send('think')
…
elif resp.dialog_state_out.microphone_mode == CLOSE_MICROPHONE:
continue_conversation = False
logging.info('close microphone')
asssitantControl_mq.send('speak')
送受信のキュー定義は冒頭で。
google_mq = posix_ipc.MessageQueue("/GoogleAssistantQueue", posix_ipc.O_CREAT)
asssitantControl_mq = posix_ipc.MessageQueue("/AssistantsControlQueue", posix_ipc.O_CREAT)
あと、Google Assistant側のサウンド処理(audio_helpers)が若干手抜きになっていて、sourceとsinkのインスタンスを区別していないらしく(SoundDeviceStream)、Snowboyと並行動作させると"読み込みバッファに書き込むな"的なエラーが出るので、sourceとsinkを区別できるよう、audio_helpers.pyにも手を入れました。
AssistantControl
コマンドラインからはこう呼び出しています。
python AssistantControl.py resources/alexa.umdl resources/snowboy.umdl
第1引数がAlexa用wake wordのmodel、第2引数がGoogle Assistant用wake wordのmodelです。
Wakeword複数待ちの処理はSnowboyのサンプルコードから取ってきています。
models = sys.argv[1:]
sensitivity = [0.6,0.6]
detector = snowboydecoder.HotwordDetector(models, sensitivity=sensitivity)
callbacks = [alexa_callback, google_callback]
print('Listening... Press Ctrl+C to exit')
…
# main loop
detector.start(detected_callback=callbacks,
interrupt_check=interrupt_callback,
sleep_time=0.03)
detector.terminate()
引数で指定された各modelに対応したsensitivity、callbacksを設定。
あとはHotwordDetector.startを実行すると複数wake wordを待ち受けてくれます。
上記の場合、"Alexa"を検知するとalexa_callbackが、”Snowboy"を検知するとgoogle_callbackが呼び出されることになります。
並行して各Assistantと通信するためのQueueを作っておきます。
google_mq = posix_ipc.MessageQueue("/GoogleAssistantQueue", posix_ipc.O_CREAT)
alexa_mq = posix_ipc.MessageQueue("/AlexaQueue", posix_ipc.O_CREAT)
assistantsControl_mq = posix_ipc.MessageQueue("/AssistantsControlQueue",posix_ipc.O_CREAT,read=True)
Snowboyから呼び出されたコールバックメソッドで、これらのキューを使ってAssistantとやり取りする、というからくりです。
def alexa_callback():
pixels.pixels.pattern = alexa_led_pattern.AlexaLedPattern(show=pixels.pixels.show)
print('alexa detected!')
communicateAssistant(led = pixels.pixels,messageQueue = alexa_mq)
print('alexa finished')
def google_callback():
pixels.pixels.pattern = google_home_led_pattern.GoogleHomeLedPattern(show=pixels.pixels.show)
print('google detected!')
communicateAssistant(led = pixels.pixels,messageQueue = google_mq)
print('google finished')
def communicateAssistant(led,messageQueue):
led.wakeup()
print('wakeup')
messageQueue.send('wakeup')
while True:
msg = assistantsControl_mq.receive()
if msg[0] == b'finish':
break
elif msg[0] == b'speak':
led.speak()
elif msg[0] == b'think':
led.think()
sleep(0.5)
led.off()
コールバック関数先頭でReSpeakerのLED制御クラスのインスタンスを受け取り、communicateAssistantの中で当該インスタンスのメソッドを呼び出すことで、LEDの光り方を都度変えています。
ただ、4-Micと2-Micでクラス構成が違っていて、公式コードをそのまま使うだけだと4-Micと2-Micを統一的に扱えないので、インストールスクリプトの中で公式コードを書き換えつつ、2-Micでも同じように振舞えるよう、小細工するためのファイルを入れていたりします。
首尾よく動くとどうなるか
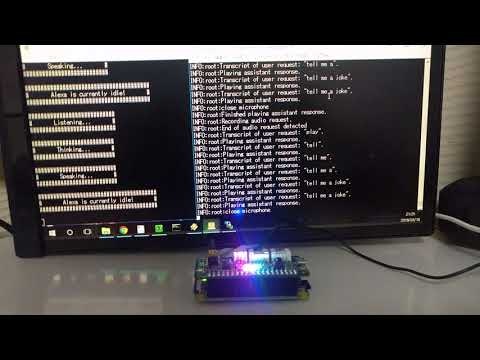
GitHubのスクリプトでそのまま作ると、Google Assistantのwake wordは"Snowboy"ですが、以下の動画では"Hey Google!"のmodelを別途作成の上、起動時に指定して動かしています。
Raspberry Pi Zero + 2-Mic(動画)
Raspberry Pi 3 + 4-mic(動画)
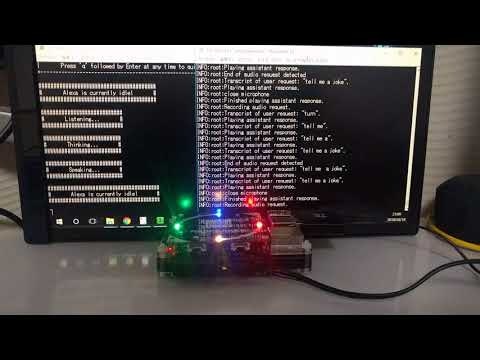
大分見栄えが良くなっているかと思います。
この実装だと、『Assistant起動中、一方のwake wordに他方のAssistantが反応しない』という副次的な効果があったりします。これは単なる並行動作では得られないメリットです。
ついでに言うと、(GitHubにも書いていますが)AlexaもGoogle AssistantもSnowboyのwake word modelを参照しているので、どんなwake wordでも設定し放題です。
満足
ここまで来ればフットプリント、見栄え共に十分追及できたかなと。
あとは適当に描いたコードの汚さや不具合、下手な英語を直すとか、手順を整備するとか、という辺りをやるかどうか、ってところです。
おわりに
昨年のAlexa動作以来、自分でも不思議なぐらいの創作意欲を持って取り組むことができました。現時点のようにEchoがだれでも手に入る状況だったら、果たしてこれだけやる気になったかどうか…。
Raspberry Piの環境構築と検証を繰り返すのは結構時間を取られる作業で、割と時間は食ったのですが、(些細ながら)誰も作ったことがなくて、見栄えが良くて役に立つモノができたかなぁと。
並行動作ネタは多分大体できたかなぁと思うので3、次は違う方面を追求することになる気がしますが、今後のプライベートプロジェクトでも、同じような創作意欲を持って取り組んでいきたいものです。
それでは、皆様もRaspberry Piと、スマートスピーカーを引き続きお楽しみください。