著者:Evan Chen(プロダクトマネージャー) & Jing Yan(テクニカルライター)
Difyを使って、ループ変数、構造化出力、およびエージェントノード、その三つの主要な要素を活用し、深層研究ワークフローを構築する方法を学びましょう。
標準の検索クエリでは、複雑な問題に対して十分な効果を発揮できません。学術論文、市場分析、またはコードのデバッグにおいて、完全な回答を見つけるためには通常、数十回の別々の検索を組み合わせる必要があります。そこで、日常的な課題を直接解決する 深層研究 が登場します。主要な人工知能プラットフォーム(Google Gemini、ChatGPT、DeepSeek-R1など)は、この強力な機能を提供しています。
深層研究は、効率を向上させるスマートなフィードバックループを通じて際立っています。このフィードバックメカニズムにより、システムは知識のギャップを特定し、特定の質問に対して注目して探求します。情報を断片化する従来の検索とは異なり、深層研究は広範囲の情報を探索し、深く掘り下げた回答やレポートを提供します。
このガイドでは、Difyを使用して深層研究ワークフローを構築する方法を具体的に説明します。
ワークフローの概観
Difyの深層研究ワークフローは、次の三つのフェーズで構成されています。
- 意図認識:ワークフローはリサーチトピックを捉え、初期のコンテキストを収集し、目標を分析して明確な方向性を確立します。
- 反復探求:ワークフローはループ変数を使って知識を評価し、ギャップを見つけ、ターゲットを絞った検索を行い、研究内容を段階的に構築します。
- 統合:収集した情報をもとに、適切な引用が含まれた構造化レポートが作成されます。
専門家の研究者の思考プロセスを模倣しています。「私は何を既に知っているのか?何が欠けているのか?次はどこを調べるべきか?」
フェーズ1:研究の基盤
スタートノード
重要な入力パラメータで「スタートノード」を設定する必要があります:
- 研究トピック(research_topic):探求すべき中心的な質問
- 最大ループ数(max_loop):この研究セッションのイテレーション予算
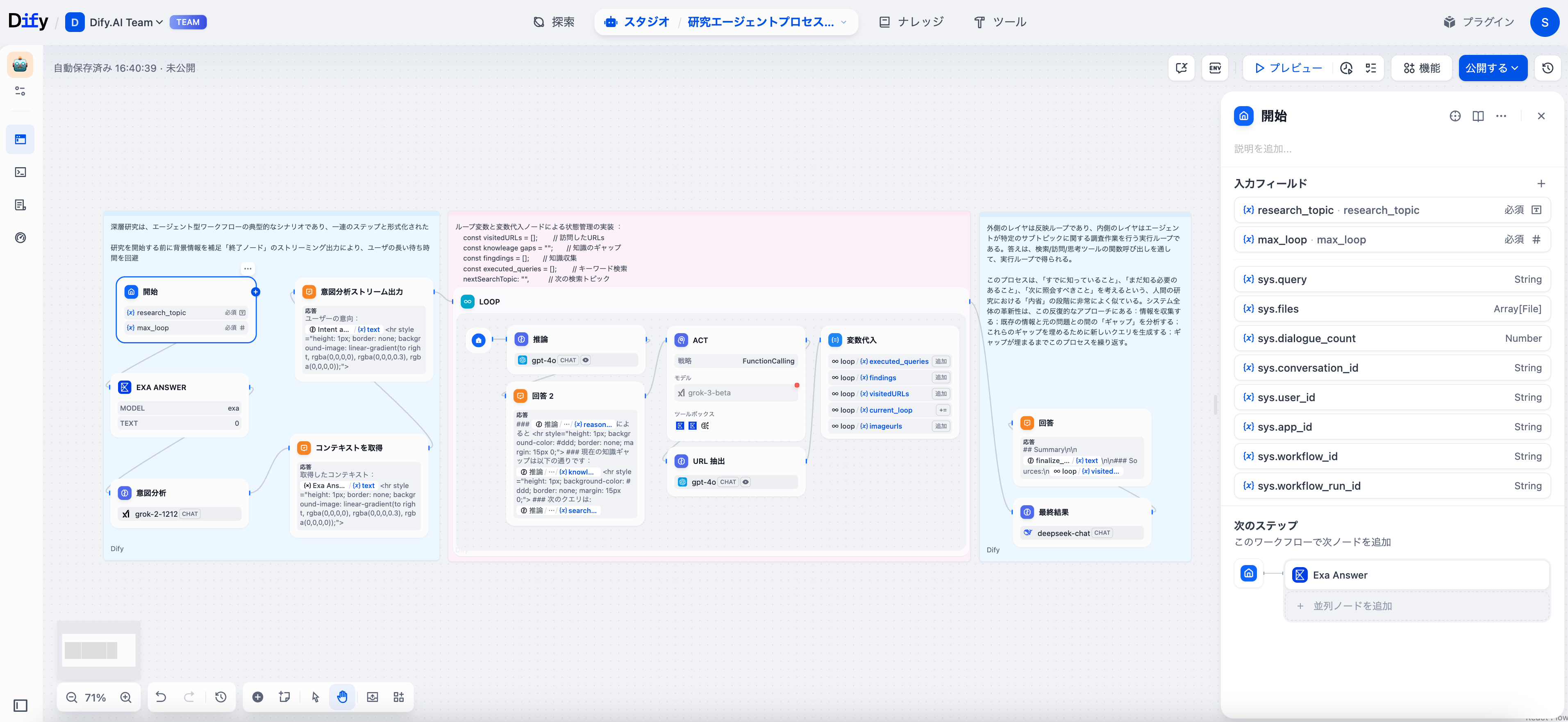
基礎知識の取得
Exa Answer ツールを使用して初期情報を収集することを推奨します。これにより、モデルが用語を理解した上でさらに深掘りできます。
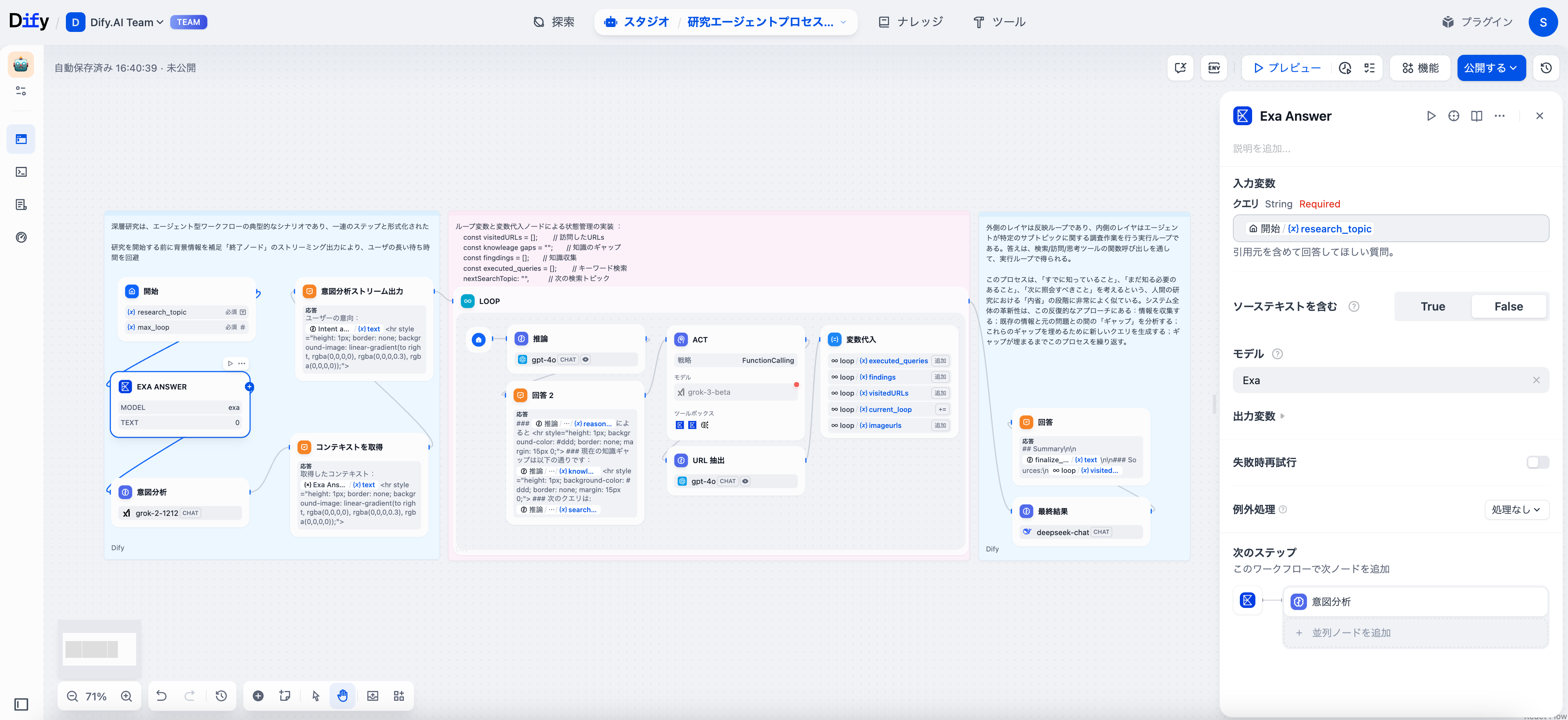
意図分析
ユーザーの真の意図を掘り起こすためにLLMノードを活用して、表面的な質問とさらなる情報のニーズを区別する必要があります。
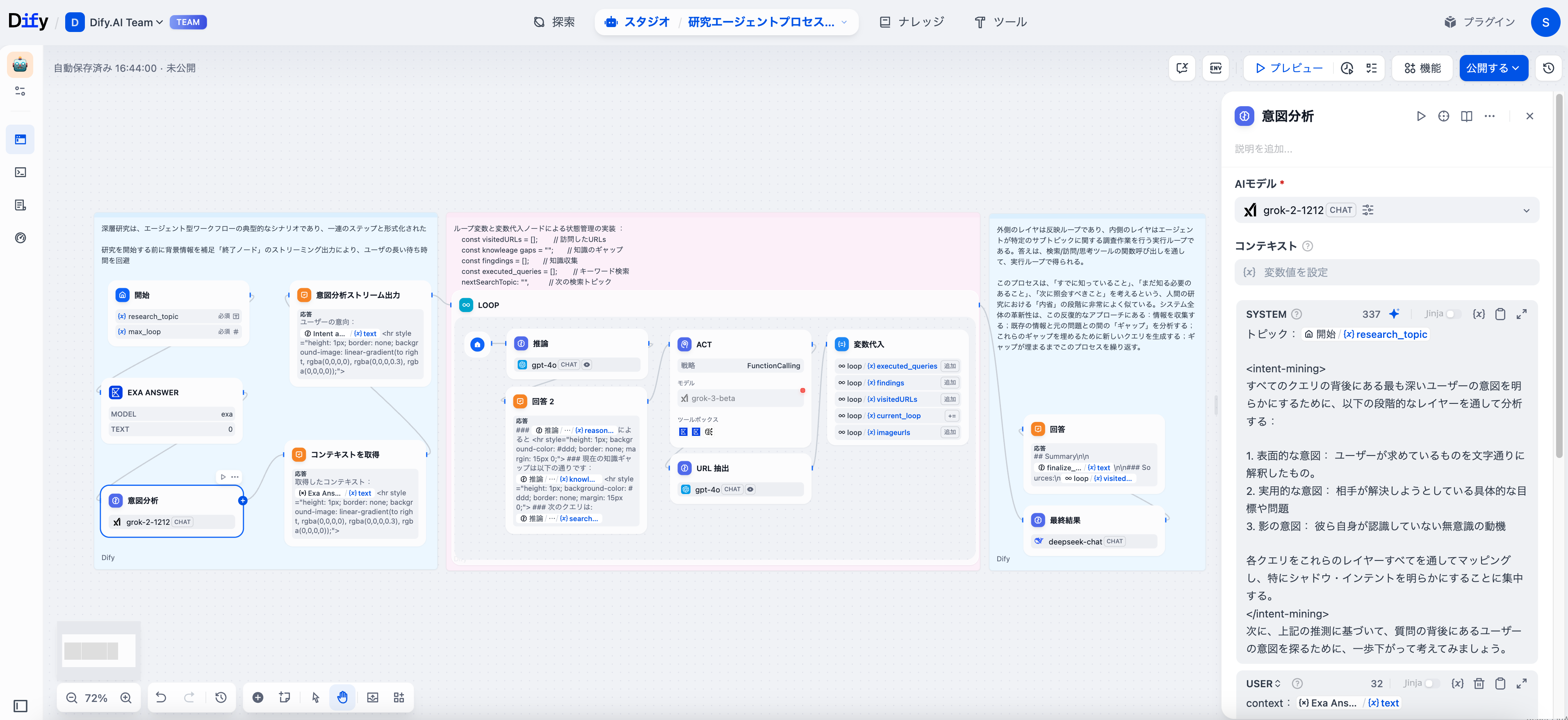
フェーズ2:ダイナミックな研究サイクル
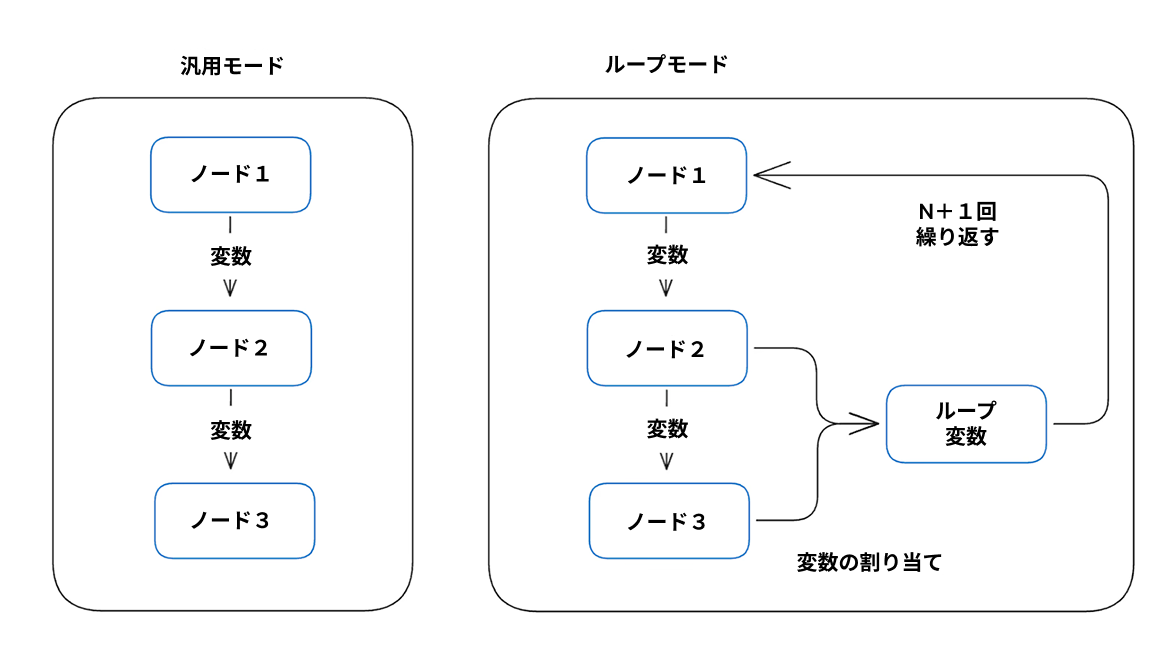
ループノード:研究エンジン
ループノードは、研究全体を支える重要な要素として機能します。Difyでは、各サイクルが前回の発見に基づいて情報を継承し、調整します。
この深層研究ワークフローは、六つの重要な変数を追跡しています:
- findings:各サイクルで新たに得られた知識
- executed_querys:以前に使用した検索クエリ(重複を防ぐため)
- current_loop:イテレーションカウンター
- visited_urls:出典管理用のURL追跡
- image_urls:視覚資料のメタデータ
- knowledge_gaps:追加調査が必要な情報ギャップ
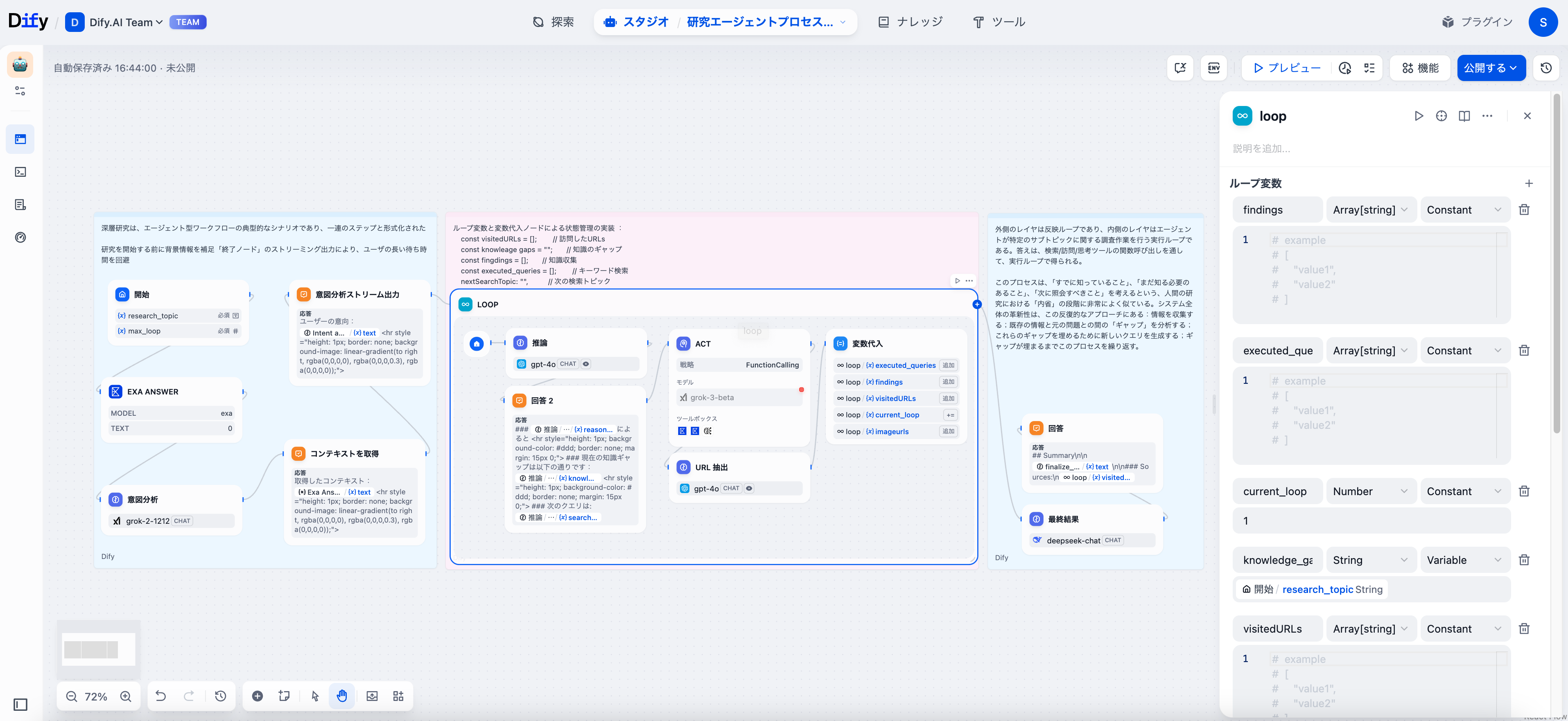
ループ変数は、通常の変数と根本的に異なるデザインを持っています。ノードは現在のイテレーションと前のイテレーションの出力にアクセスできるため、知識が蓄積され、無駄な作業が避けられ、各サイクルで焦点が明確になります。
推論ノード:より良い質問の発見
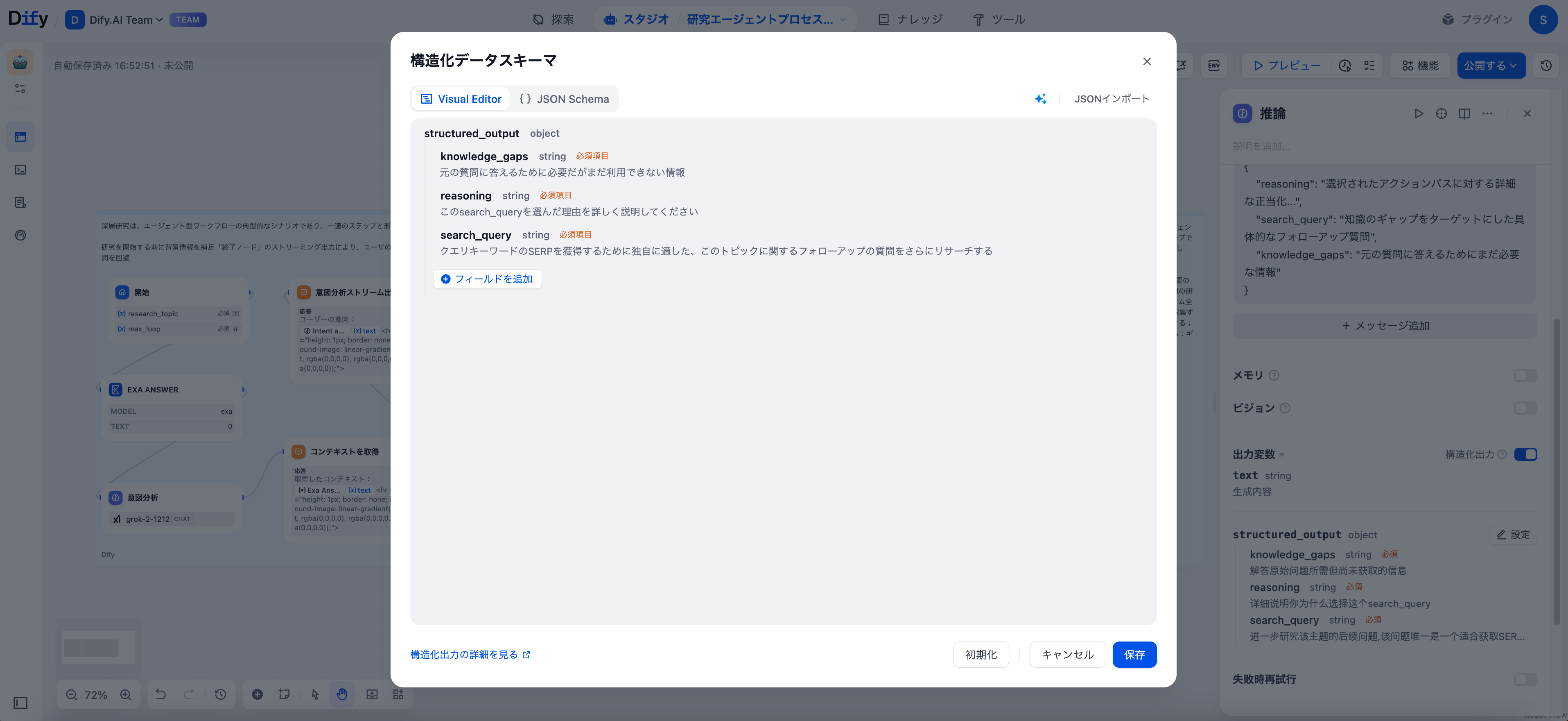
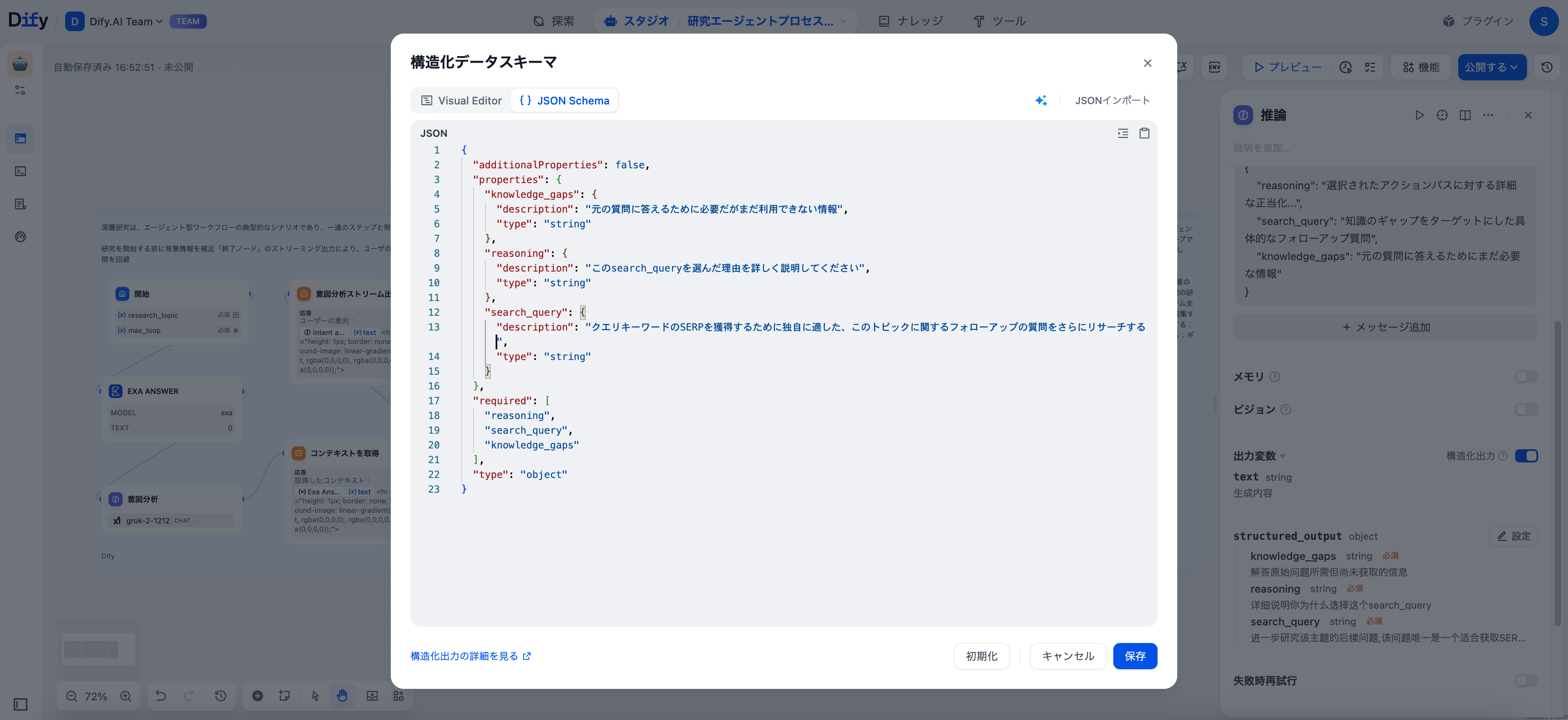
推論ノードは、情報の組織化のための構造化出力形式で機能します:
{
"reasoning": "選択されたアクションパスに対する詳細な正当化...",
"search_query": "知識のギャップをターゲットにした具体的なフォローアップ質問",
"knowledge_gaps": "元の質問に答えるためにまだ必要な情報"
}
Difyの構造化出力エディタをLLMノードで有効にすることで、信頼性のあるJSONを受け取ることができ、次のノードが確実に処理できます。これにより、推論パス、検索ターゲット、知識のギャップをクリーンに抽出できるようになります。
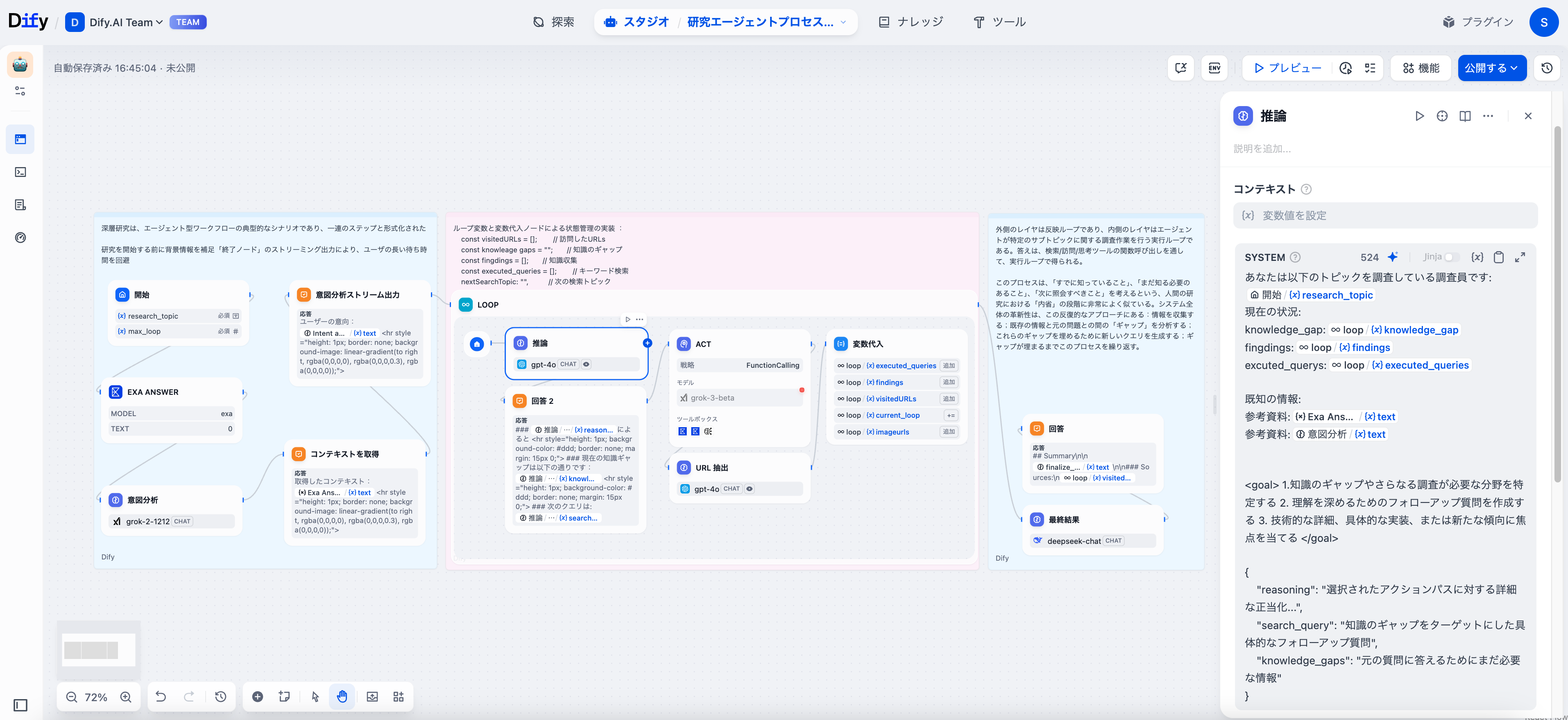
エージェントノード:リサーチの実行
良い質問は始まりに過ぎません。効果的な研究には決断力が必要で、エージェントノードがその役割を果たします。
これらのノードは、各コンテキストに最も適したツールを選択する自律的な研究者として機能します。私たちのワークフローは、エージェントに以下の機能を提供します。
発見ツール
- exa_search:ウェブ検索を行い、結果を収集
- exa_content:特定のソースから完全なコンテンツを取得
分析ツール
- think:ClaudeのThink Toolに触発されたシステムの反射エンジンです。これにより、エージェントは発見内容を評価し、パターンを特定し、次のステップを決定できます。
エージェントに必要なものだけを提供することでパフォーマンスを最適化できます。非常に特定の情報(前のLLMノードからのsearch_query)のみを提供するのです。この集中したアプローチは、ツールの選択精度を向上させます。
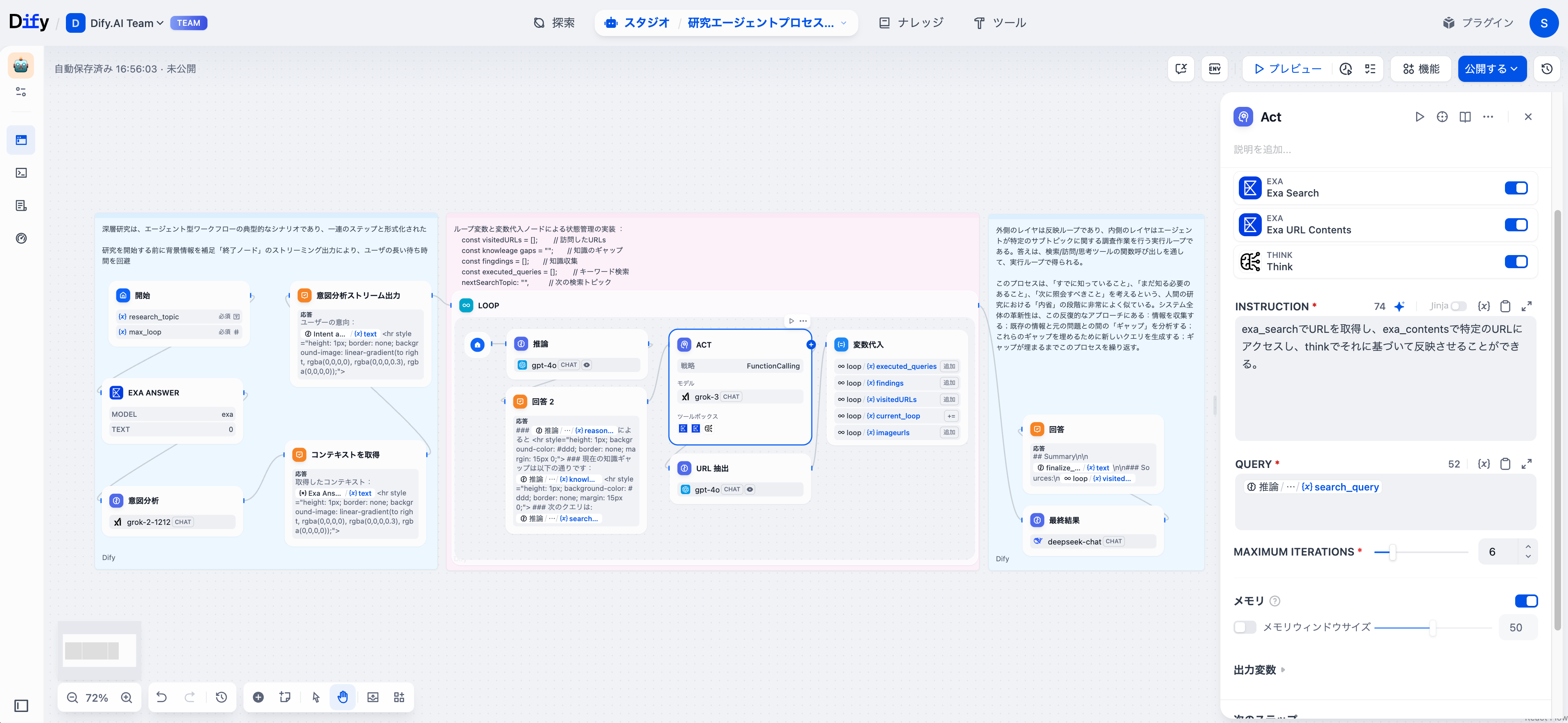
URLの抽出
ワークフローは、エージェントの応答から自動的にURLと視覚的参照を特定し、すべての情報源を適切に追跡します。
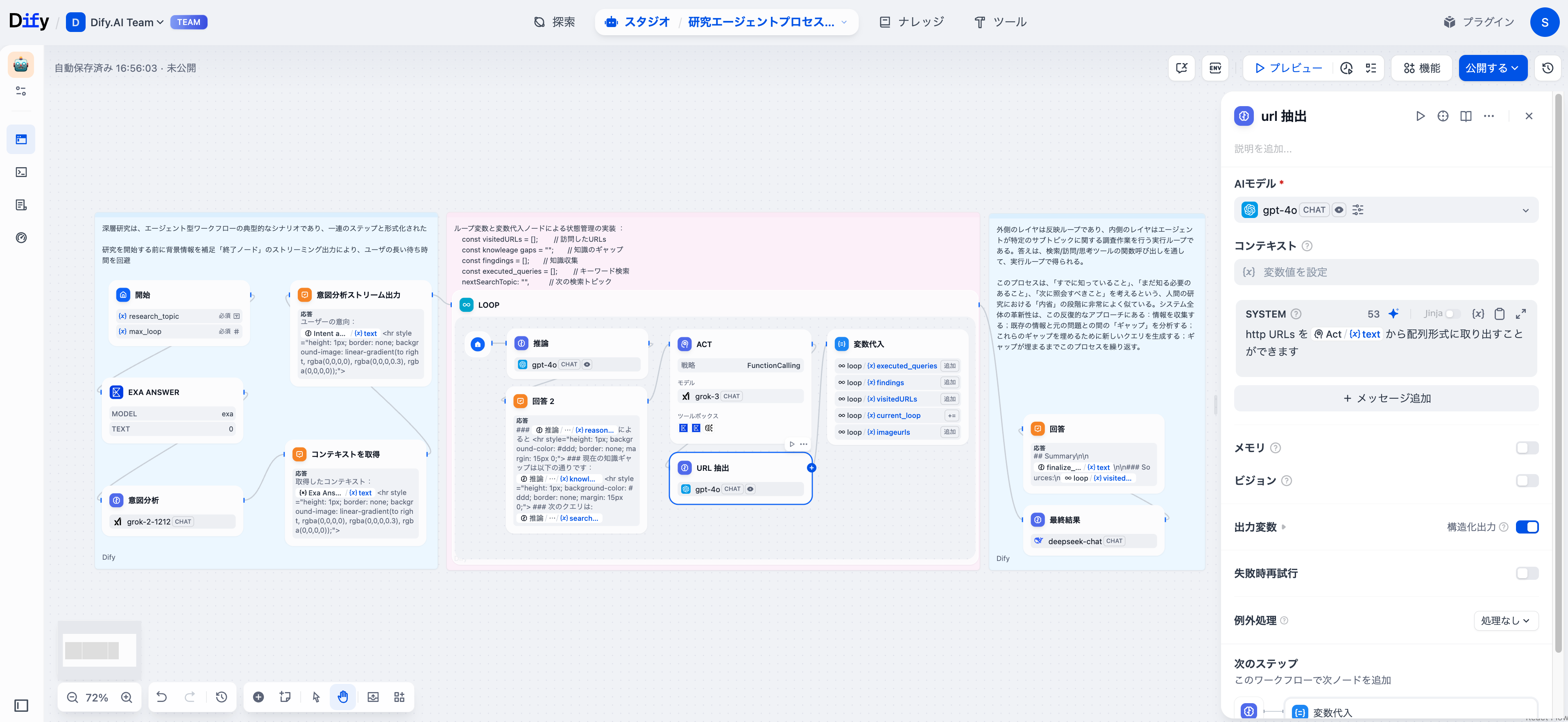
各イテレーションで、エージェントは情報を収集し、コンテンツを処理し、発見を統合することで、完全な研究サイクルを完了します。
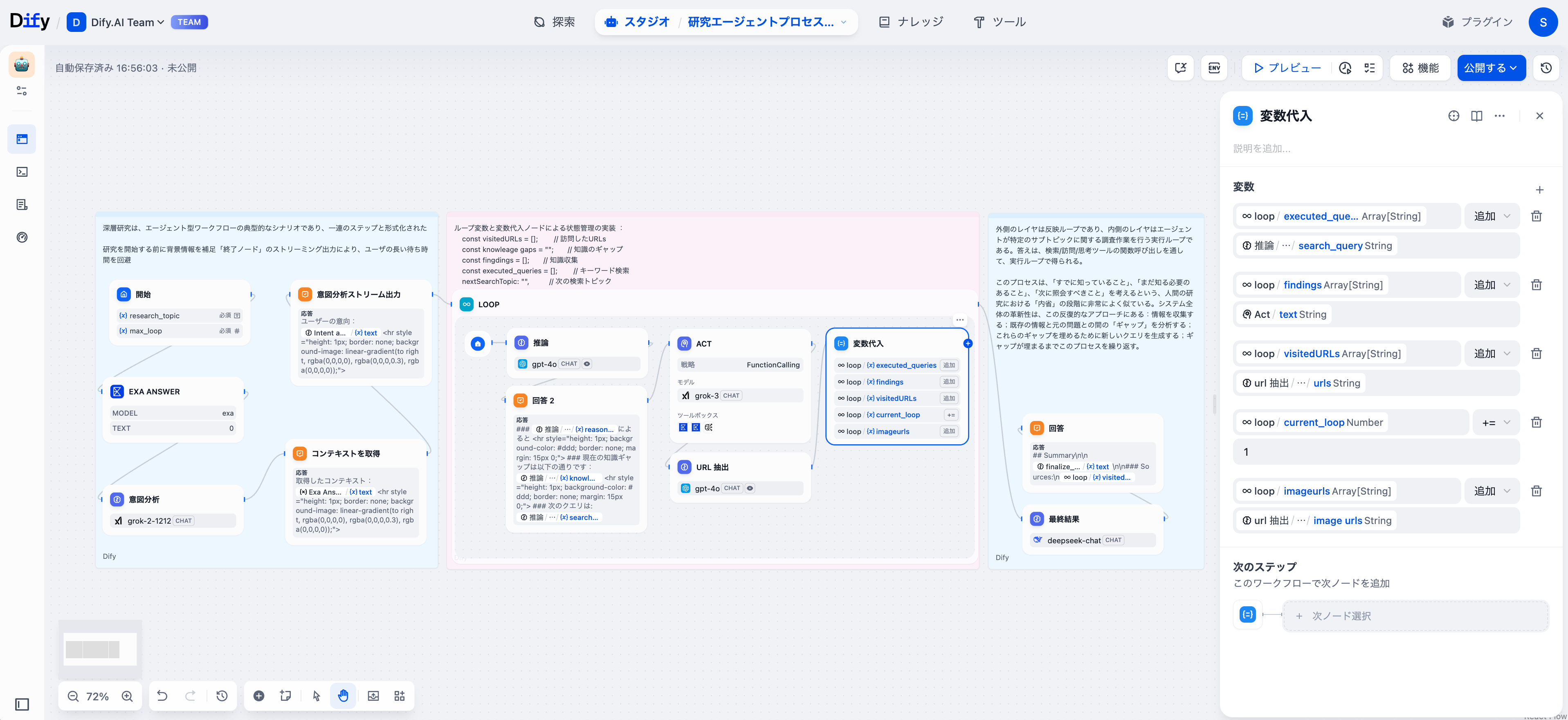
変数の割り当て
各サイクルの後、変数代入ノードが研究の進捗状態を更新します。これにより、各イテレーションは前回の作業に基づいて構築され、無駄な労力を回避します。
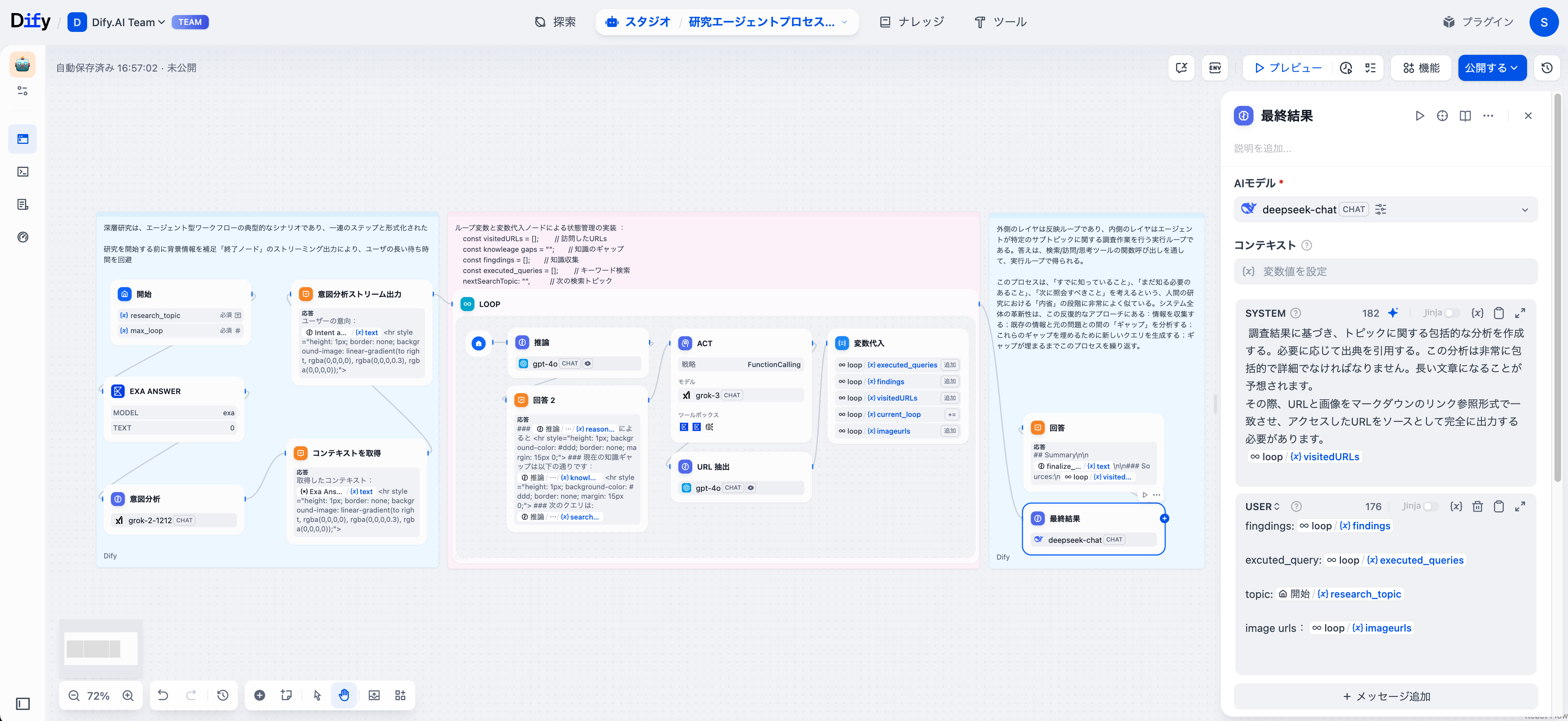
フェーズ3:研究の統合
複数の探求サイクルが終了した後、最終結果が収集した変数(発見内容、ソース、支持データ)をもとに、包括的なレポートを生成します。
このノードは適切なMarkdown引用を維持し、完全な参考リストをまとめます。また、ワークフローは研究全体を通じて適時更新を提供するために、戦略的なポイントで回答ノードを設けています。これらの更新は、精度のある分析を伴う最終レポートの構築に寄与します。
結論
この深層研究ガイドでは、Difyのエージェントワークフローが何を達成できるかを示しています。私たちは専門家の研究方法をデジタル化し、自動化を通じて加速させました。
研究の未来は、単にデータを増やすことではありません。それは、よりスマートにそれを探求する方法を意味します。今すぐこれらのパターンを取り入れ、あなた自身の研究エンジンを構築してください。