予測結果に対する局所的説明。利用者が理解できる説明指標の重要性について。
はじめに
- モデルの評価とPoCを作成し説明していく為に必要な情報のまとめはこちら。理解されるPOC作成のために、機械学習したモデルをどう評価し説明するかのまとめ。
- 使用したDataサンプルは以前にジニ係数・AUCで利用したものです。
- MLがブームとなっているのは多くの人が知っている状況となりましたが、MLが何をしているのか、事業にどう利用するのか、そもそもモデルをどう評価して理解すればいいのかなど、作る側の技術の発展の速度に対して、利用する側の理解は進んでいません。
その為、局所的説明の重要性が高まってきています。 - 銀行など規制が厳しい事業では、容易にAIによるCredit Scoreを利用することができません。
モデルの説明や、個別に算出したスコアを監督官庁や顧客に対して説明する義務がある国もあります。
SHAPとは
-
SHAP(SHapley Additive exPlanations)はゲーム理論のShapleyを利用したものです。Shapleyは
ゲーム理論において協力によって得られた利得を各プレイヤーへ公正に[1] 分配する方法の一案である。 wikiより
つまり、予測結果に対する各特徴量の寄与度を数値化しています。
-
とくに予測結果に対して、各特徴量がプラス方向に働いたのか、マイナス方向に働いたのかがわかります。
理論と計算方法について
-
概要としては、下図のようにDataとModelを利用して説明できる形になります。
何らかのモデルを作成し、その後モデルのベース値と予測値の元になるデータを利用し、SHAP値を算出します。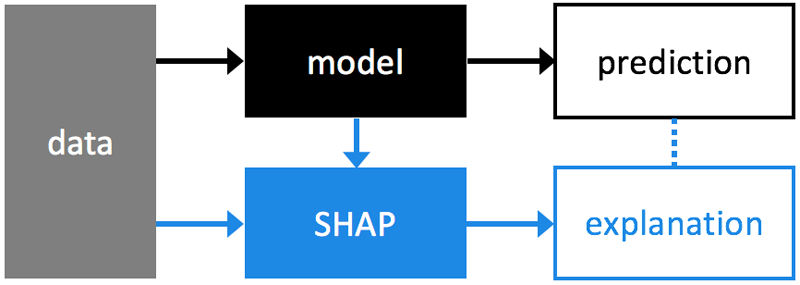
-
理論と計算方法については、主にこちらを参照してください。
-
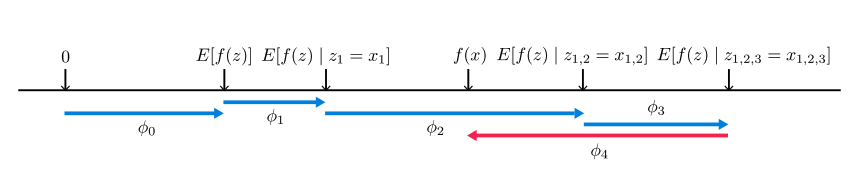
モデルのベース値から各特徴量のlocal accuracy:$\phi_i$が下記の図のようにプラス方向・マイナス方向に働いているかがわかります。
実際に利用してみる
-
Installが必要です。
pip install shap -
各種LibraryのImportと適当なモデルを作成してみます。
前回のGini係数で利用したDataなどをそのまま利用します。# Import Library import numpy as np import pandas as pd import matplotlib.pyplot as plt import shap from sklearn.ensemble import RandomForestClassifier X_train = pd.read_csv('X_train.csv') y_train = pd.read_csv('y_train.csv') clf= RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini', max_depth=25, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=15, min_weight_fraction_leaf=0.0, n_estimators=50, n_jobs=4, oob_score=False, random_state=0, verbose=0, warm_start=False) clf.fit(X_train, y_train)
SHAP値の取得(個別編)
-
早速SHAPを利用してみましょう。
# load JS visualization code to notebook shap.initjs() # Create object that can calculate shap values explainer = shap.TreeExplainer(clf) # Calculate SHAP values shap_values = explainer.shap_values(X_train) # visualize the first prediction's explanation (use matplotlib=True to avoid Javascript) shap.force_plot(explainer.expected_value[0], shap_values[0,0],X_train.iloc[0,:]) -
下図のような結果が出たと思います。

-
表示されている情報を確認していきましょう。
赤く表示されている特徴量がプラス方向に向かって影響している部分、青色がマイナス方向に向かってに影響している部分です。
たとえば、特徴量BやHがプラス方向に大きく作用しており、特徴量MやDマイナス方向に少しだけ作用しています。
Base valueはモデルに対してのベース値になり、赤のプラス方向への数値分が+に、青のマイナス方向への数値分がーに変動して、最終的なOut put valueが0.89となりベース値よりプラスな結果となっています。 -
上記で求めたSHAP Valuesを確認してみましょう。
print(shap_values[0,1])
array([[ 0.02977548, 0.1035129 , 0.01178285, -0.01269318, -0.00032813,
0.01911404, 0.00921835, 0.07468714, 0.02068959, 0.01665524,
0.02328084, -0.00728858, -0.01271569]])
```
上記の各数値が各特徴量のlocal accuracy:$\phi_i$となり、各数値を合計すると
(0.02977548+ -0.1035129.. + ....) = 0.2756...
となります。そしてベース値の[ 0.6158...] を足すとOut putの[ 0.891448.. ]となります。
-
ちなみに
clf.predict_proba(X_train)[0,0]
array([0.8914484303704249])
```
という結果を見ることができ、Out putと同じ値になっています。
つまりOut putの値はProbability Predictionの値で、SHAP valuesとは、なぜこの人の場合のProbability Predictionが0.89144..になったかを説明できる数値となります。
-
下記のように対象者を変えてみると
shap.force_plot(explainer.expected_value[0], shap_values[0,2],X_train.iloc[0,:])
```

このように違う結果が当然得られます。そしてBase valueでは同じことを確認できます。
-
Base valueはトレーニング用データ・セットでの平均値で、下記の値となります。
explainer.expected_value[0]
0.6157575789839029
```
Out putがProbabilityではない時
-
上記のRandom forestモデルではOut putの値はProbabilityとなっていますが、モデルによってはシグモイド関数で確率となる前の値の場合があります。すべて確認していませんが、XGboostなどの勾配ブースティングはそちらの値になると思います。
-
下記のXGboostのモデルを作成してみましょう。
# XGboost import xgboost as xgb clf_xg = xgb.XGBClassifier() clf_xg.fit(X_train, y_train) shap.initjs() explainer_xg = shap.TreeExplainer(clf_xg) shap_values_xg = np.array(explainer_xg.shap_values(X_train)) shap.force_plot(explainer_xg.expected_value, shap_values_xg[0,:],X_train.iloc[0,:])
-
Out putを確率にしたい場合、いくつか制約がありますが下記の方法で行うことは可能です。
-
Out put値やBase valueをProbabilityに変換したい場合は、シグモイド関数を利用します。
**Base valueを確率に変換しても正確ではありません。下記(2)の値とずれるため注意が必要です。# シグモイド関数 import numpy as np import math def sigmoid(a): s = 1 / (1 + e**-a) return s# Base value e = math.e print(explainer_xg.expected_value,sigmoid(explainer_xg.expected_value)) -0.5747993 0.3601301507295089# Out put value shap_sum = np.sum(shap_values_xg[0,:]) + explainer_xg.expected_value print(np.sum(shap_values_xg[0,:]) + explainer_xg.expected_value,sigmoid(shap_sum)) -2.4900246 0.07656046049720014 -
Out put全体を変換したい場合は、xplnainerの部分で下記のようなパラメーターを利用します。
ただし、この方法は計算コストが非常にかかります。RandomForestの場合は、SHAP値を求める時は対象になる1件だけのデータを渡せばいいのですが、この場合はモデル作成に利用したすべてのデータを渡す必要があるためです。
ニーズはあるようなのですがSHAPの理論上なかなか他の解決策がないのか、私が知らないだけかもしれません。
** 上記(1)でBase valueを確率に変換した値は0.360で、ここで表示されているのは0.3838となり、上記(1)の値は確率に変換できないのです。ただし、Out put valueの値は(1)と(2)は同じ結果となります。explainer_xg = shap.TreeExplainer(reg, feature_dependence='independent',model_output='probability',data=X_train)
SHAP値(モデル全体編)
-
上記では個別のSHAP値について可視化しましたが、モデル全体を把握するためのツールもあります。
-
下記の図は、Sample order by similarity, out put valueなどで見ることができます。
shap.force_plot(explainer.expected_value[0], shap_values[0])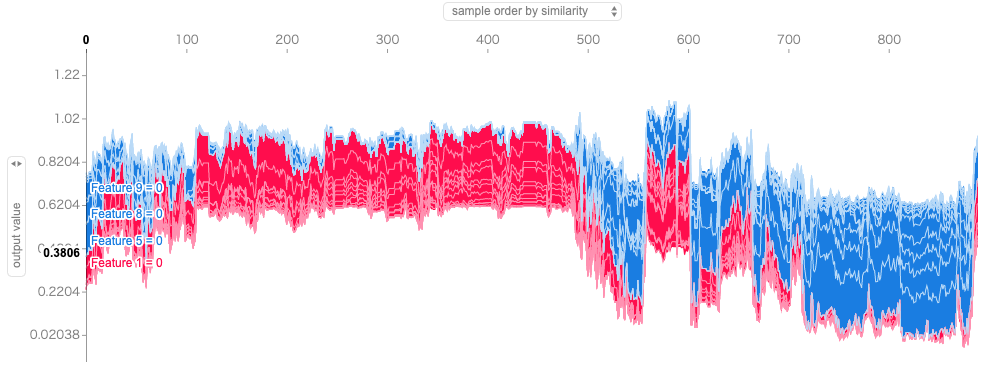
- 下記の図は、1つの特徴量がモデルにどのように影響するかを確認するためのサンプルです。特徴量Aの値がX軸、特徴量AのSHAP valueがY軸の左、特徴量Bの値は色分けでプロットされており、ラベルが右側に表示されています。特徴量Bの値は、0から0.5は青、0.5から1は赤と言う色分けになっています。もし、Bの値が複数ある場合は、さらに色分けがされます。 X軸のAの値が1または2の時は、特徴量Bの値が0(青い部分)か1(赤い部分)でY軸の値が分布しています。この場合、X軸のAの値が1か2の時ではあまり違いはなく、Bの値が0では高めに、1では低めになる傾向があります。また、X軸のAの値が3の場合は、Bの値にかかわらず1と2の時よりY軸の値が高くなります。さらにAの値が1と2とは逆に、Bが0の時がY軸の値が低めになっています。
-
相互作用の対象となる特徴量は自動的に選択され、値を色分けしてくれるようです。
shap.dependence_plot('A', shap_values[0], X_train)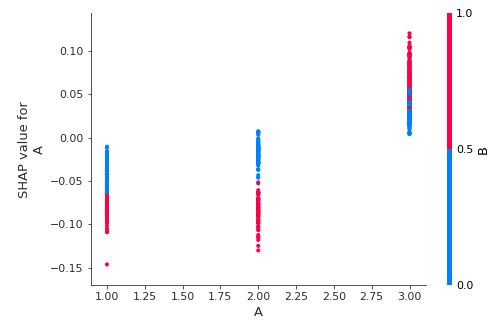
-
下記の図では、複数の特徴量の値に対してSHAP値がどのように影響しているかを見ることができます。
-
たとえば、Bの値が青(Bの値は0か1であり、青はLowなので0)の時、SHAP値が大きくプラスに、逆に値が1の時はマイナスにはっきり分かれています。
shap.summary_plot(shap_values[0], X_train)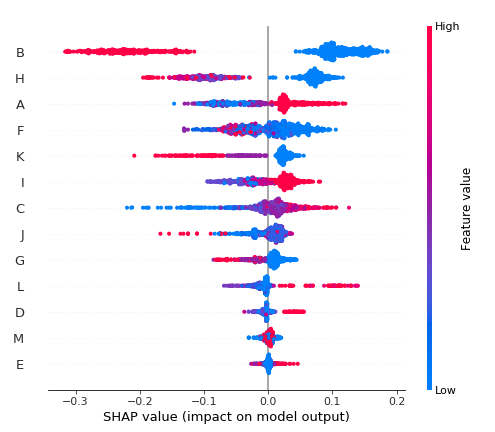
-
下記の図では、各特徴量の重要度が確認できます。
shap.summary_plot(shap_values[0],X_train, plot_type="bar")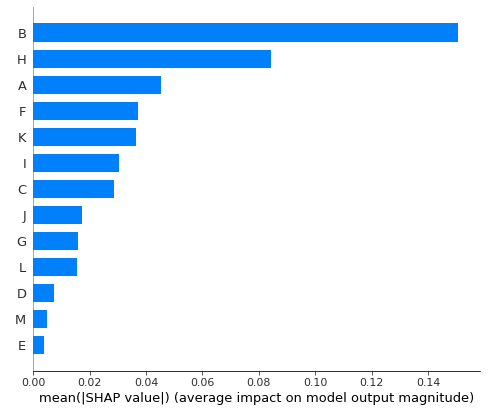
まとめ
- SHAPとは、ゲーム理論のSHapleyを基にモデル全体と個別のユーザー(クレジットスコアの場合は債務者)に対し、各特徴量の重要度を数値化し説明可能にしている。
- 各債務者のProbabilityに対して、モデル全体のベース値から各特徴量の値がプラス・マイナスに影響した値を可視化している。
- モデルを利用する側(クレジットスコアの場合は与信者)にとって、どの要素がポイント(数値)的にどのくらい影響を与えているかが明確である。そのため、昔からあるスコアカード的な要素もあって馴染み安い。
** スコアカードとは、たとえば年齢が30−50歳だとポイント10のような、要素と値によってポイント化し、合計値をスコアとして利用している方法。 - モデル全体だけでなく、個々の予測値に対して説明ができる局所的説明可能性のニーズがある。たとえば今までは目に見えていたものが見えなくなるというのは、使用する側からするととても理解しがたいものだったりする。
MLの結果を人の目を通さずに利用する状況であればあまり問題にならないかもしれないが、そうでない場合はやはりその人が安心できる何かを提供することが必要だと思う。
パラメーター概要
Explainers
-
class
shap.TreeExplainer(model, data=None, model_output='margin', feature_dependence='tree_path_dependent') -
shap_values(X, y=None, tree_limit=None, approximate=False)
Plots
-
shap.summary_plot(
shap_values, features=None, feature_names=None, max_display=None, plot_type='dot', color=None, axis_color='#333333', title=None, alpha=1, show=True, sort=True, color_bar=True, auto_size_plot=True, layered_violin_max_num_bins=20, class_names=None) -
shap.dependence_plot(
ind, shap_values, features, feature_names=None, display_features=None, interaction_index='auto', color='#1E88E5', axis_color='#333333', cmap=, dot_size=16, x_jitter=0, alpha=1, title=None, xmin=None, xmax=None, show=True) -
shap.force_plot(
base_value, shap_values, features=None, feature_names=None, out_names=None, link='identity', plot_cmap='RdBu', matplotlib=False, show=True, figsize=(20, 3), ordering_keys=None, ordering_keys_time_format=None, text_rotation=0) -
shap.image_plot(
shap_values, x, labels=None, show=True, width=20, aspect=0.2, hspace=0.2, labelpad=None)