本書は画像分類のための最新表現学習モデル(2020年10月現在)であるSimCLRについて説明します。(CNNの基礎を理解している前提で記載しています。まだ理解していない方は別冊のCNNの基礎を先に読んでください。
【参考文献、サイト】
1.はじめに
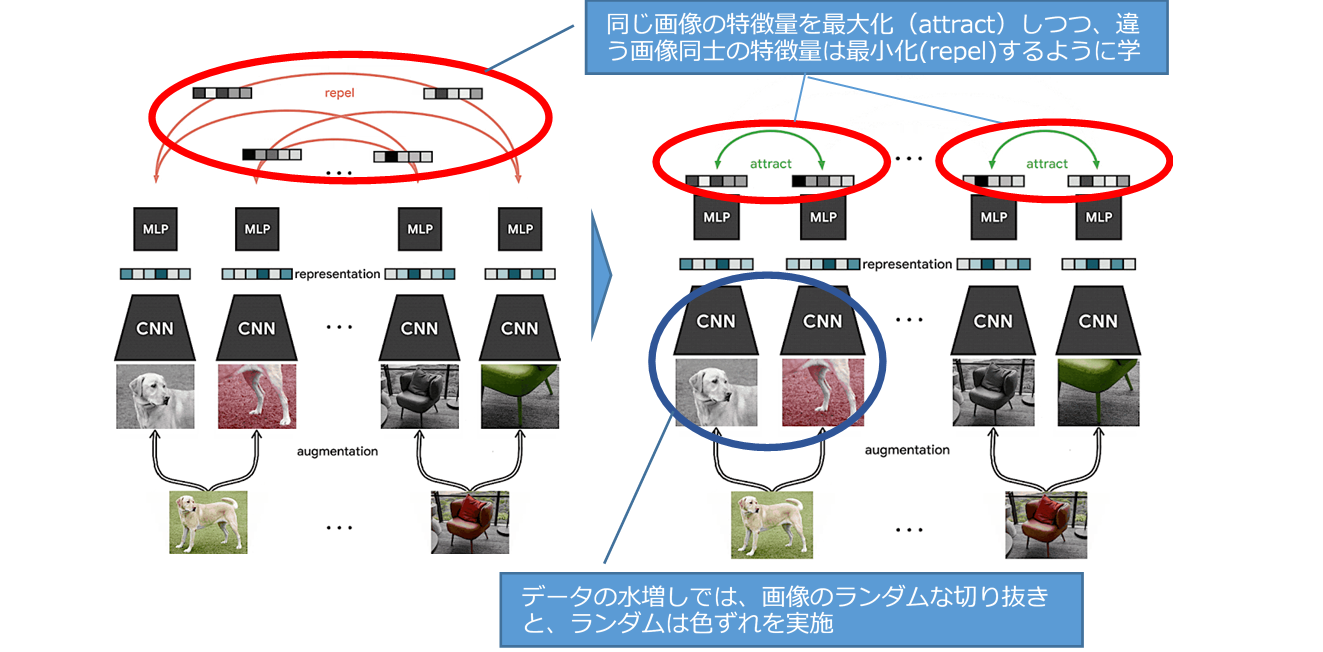
SimCLRは、ディープラーニングの生みの親の一人であるGeoffrey Hinton等のGoogle Research, Brain Teamが発表した、対照学習(同じ画像同士の特徴量を最大化しつつ違う画像同士の特徴量を最小化する)により自己教師学習の性能を向上させたシンプルなフレームワークです。SimCLRは自己教師及び半教師でありながら教師あり学習に迫るスコアを達成(=大変なラベル付け作業が大幅に軽減)しています。学習でのデータ水増し(Data Augmentation)では、画像の「ラインダムな切り抜き」と「ランダムな色ずれ」が有効とされています。
2.SimCLRモデルの概要
SimCLRは、上図のようにResNetアーキテクチャに基づいたCNN(畳み込みニューラルネットワーク)のバリアントを使用して画像の特徴表現を計算します。その後、MLP(多層パーセプトロン、全結合)を使用して画像の特徴表現の非線形投影を計算します。対照的なオブジェクトの損失関数を最小化するために、確率的勾配降下法(SGD)を用いてCNNとMLPの両方を更新します。ラベル付けされていない画像で事前学習を行った後、CNNの出力を画像の特徴表現として直接利用するか、ラベル付けされた画像を用いて微調整することで、下流のタスクで良好な性能を達成することができます。
(1) SimCLRの特徴
従来の画像データを用いた自己教師学習手法(ex. CPC、AMDIM、CMC、MoCo)は複雑であり、アーキテクチャやトレーニング手順に大幅な変更を加える必要があり広く採用されることはありませんでした。SimCLRは自己学習および半教師付き学習の技術を大幅に進歩させ、「限られた量のクラスラベル付きデータ」で画像分類の新記録を達成しています(ImageNetデータセット上のラベル付き画像の1%を用いた場合、85.8%の精度でトップ5 accuracyを達成)。また、SimCLRのアプローチはシンプルであるため、既存の教師付き学習パイプラインに簡単に組み込むことが可能です。
(2) SimCLRフレームワーク
SimCLRは、最初にラベル付けされていないデータセット上の画像の一般的な表現を学習し、その後与えられた分類タスクに対して良好な性能を達成するために、少量のラベル付けされた画像を用いて微調整することができます。
一般的な特徴表現は、対照学習と呼ばれる手法で、「同じ画像の異なる変換されたビュー間の一致度を最大化」し「異なる画像の変換されたビュー間の一致度を最小化」する、ことによって同時に学習します。この対照的な目標を使用してニューラルネットワークのパラメータを更新すると、対応するビューの表現はお互いに「引き寄せ合う(attract)」ようになり、対応しないビューの表現はお互いに「反発する(repel)」ようになります。
SimCLRは元のデータセットからランダムにサンプルを抽出し、各サンプルを単純な水増し処理(ランダムな切り抜き、ランダム色ずれ、ガウシアンぼかし)の組み合わせを用いて2回変換処理を行い、2つのビューのセットを作成します。
個々の画像のこれらの単純な変換の背後にある理論的根拠は以下です。
ⅰ)変換下で同じ画像では「一貫した」特徴表現を得たい
ⅱ)事前学習データにはラベルがないので、どの画像にどのオブジェクトクラスが含まれているかを事前に知ることができない
ⅲ)ニューラルネットがワーク良い表現を学習するためには、これらの単純な変換で十分であるが、より洗練された変換ポリシーを組み込むことも可能
(3) SimCLRのパフォーマンス
SimCLRの自己教師付き特徴表現の上で訓練された線形分類器は、76.5% / 93.2%のトップ1 / トップ5のaccuracyを達成しています。以前のベストモデルである「CPC v2」の71.5% / 90.1%と比較しても、より小さなモデルであるResNet-50の教師付き学習の性能と一致します。

3.対象学習による特徴表現
SimCLRが従来の手法よりも改善されたのは、単一の設計選択によるものではなく、組み合わせによるものです。3つの重要な知見が述べられている。
知見1「対応するビューを生成するために使用される画像変換の組み合わせが非常に重要」
同じ画像の異なるビューの一致を最大化することで表現を学習するため、カラーヒストグラムの一致のような些細な一致を防ぐために画像変換を構成することが重要です。このことをよりよく理解するために、以下の図に示すように、さまざまなタイプの変換を検討しています。

ランダムな切り取りとランダムな色歪みの組み合わせがなぜ重要なのかを理解するために、同じ画像の2つの切り取りの間の一致度を最大化するプロセスを考えた場合、効果的な表現学習を可能にするには、以下の2つのタイプの予測を考える必要があります。
(a) より大きなグローバルビューからローカルビューを予測する作業
(例えば、下図4のクロップBからクロップAを予測する作業)
(b) 近隣ビューを予測する作業
(例えば、下図4のクロップCとクロップDの関係を予測する作業)

知見2「非線形な投影が重要」
SimCLRでは、対照学習の損失関数が計算される前にMLPベースの非線形投影が適用され、各入力画像の不変な特徴を識別し同じ画像の異なる変換を識別するネットワークの能力を最大化するのに役立ちます。実験では、このような非線形投影を使用することで表現の質を向上させ、SimCLRで学習した特徴表現で訓練した線形分類器の性能を10%以上向上させることが分かっています。
※MLP投影モジュールの入力として使用された特徴表現と投影からの出力を比較すると、線形分類器によって測定した場合、前者の特徴表現の方がより良いパフォーマンスを発揮することが分かっています。対照学習の損失関数は投影の出力に基づいているので、投影の前の表現の方が優れていることはやや驚くべきこととのことのことですが、ネットワークの最終層で、下流のタスクに有用であるかもしれない色などの特徴に対して不変になるように導くのではないかと推測しているとのこと。追加の非線形投影ヘッドにより、投影ヘッドの前の特徴表現層は、画像に関するより有用な情報を保持することができます。
知見3「スケールアップすると、パフォーマンスが大幅に向上」
下記のすべてが有意な改善につながります。
①同じバッチでより多くの例を処理する
②より大きなネットワークを使用する
③より長い時間学習する
これらの改善は教師あり学習よりもSimCLRの方が大きいように思われるとのこと。例えば、教師付きResNetの性能は、(ImageNet上での)90~300エポックの間にピークを迎えるが、SimCLRは800エポックの学習を行った後も改善を続けることができます。また、ネットワークの深さや幅を大きくしても、SimCLRの向上は継続するが、教師あり学習では飽和し始めます。
4. SimCLRモデルの詳細
SimCLRのアーキテクチャ図は、下図5の通りです。
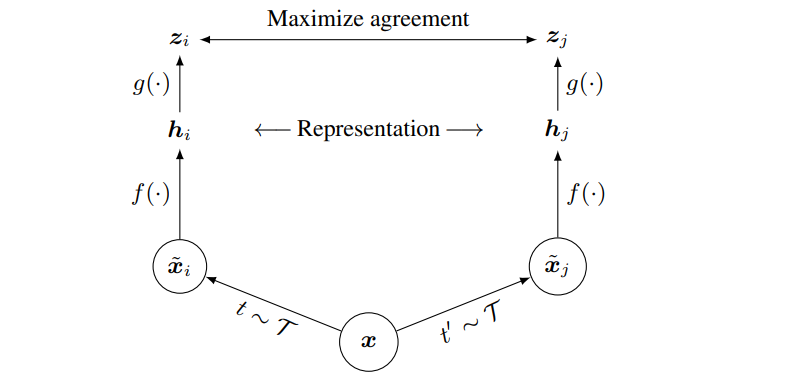
ベースエンコーダネットワークf(-)と投影ヘッドg(-)は、コントラストロスを用いて一致度が最大になるように訓練されます。訓練終了後は、投影ヘッドg(-)を捨て、エンコーダf(-)と特徴表現hを下流のタスクに利用します。
SimCLRは以下の4つの主要なコンポーネントで構成されています。
① 確率的データ水増しモジュール(A stochastic data augmentation module)
与えられたデータサンプルをランダムに変換し、同じデータサンプルを相関のある2つのビュー( xi˜ と xj˜ )を正のペアとみなす。論文ではランダムなクロップと元のサイズに戻すリサイズ、ランダムな色歪み、ランダムなガウスぼかしの3つの単純な増大処理を順次適用していきます。ランダムクロップと色歪みの組み合わせは、良好な性能を達成するために非常に重要です。
② ニューラルネットワークベースのエンコーダf(-)
拡張データサンプルから特徴表現ベクトルを抽出します。SimCLRフレームワークでは、制約なしにネットワークアーキテクチャの様々な選択が可能です。単純化を選択し、 hi = f(xi˜) = ResNet(xi˜) を求めるために、一般的に使用されているResNet(He et al., 2016)を採用し、 hi ∈ Rd が平均プーリング層の後の出力です。
③ 小さなニューラルネットワーク投影ヘッドg(-)
特徴表現を対比損失が適用された空間に写像します.1つの隠れ層を持つMLPを用いて、zi = g(hi) = W(2)σ(W(1)hi) を求めます(σはReLU非線形性)。コントラスト損失は hi の損失ではなく、 zi の損失で定義することが有益です。
④ 照合予測タスクのために定義されたコントラスト損失関数
xi˜ と xj˜ の正の対を含む集合 { xk˜} が与えられた場合、照合予測タスクは、与えられたxi˜ に対して { xk˜}K≠1の中のxj˜ を特定することを目的とします。
N個のサンプルのミニバッチを無作為にサンプリングし、ミニバッチから得られた拡張サンプルのペアで照合予測タスクを定義し、2N個のデータ・ポイントを得ます。
否定的な例は明示的にサンプリングしません。代わりに、(Chen et al., 2017)と同様に、正のペアが与えられた場合、ミニバッチ内の他の2(N - 1)個の拡張例を負の例として扱います。 sim(u, v) = u Tv/||u|| ||v|| は、l2正規化されたuとvの間のドット積(すなわち、余弦類似度)を表し、正の例のペア (i, j) の損失関数は次のように定義されます。

上記をまとめたアルゴリズムは下記のようになります。

5.おわりに
以上でSimCLRの説明は終了です。少ないラベル(正解データ)で認識精度がだせれば大幅にデータ前処理が効率化されるものと思います。