本書は筆者たちが勉強した際のメモを、後に学習する方の一助となるようにまとめたものです。誤りや不足、加筆修正すべきところがありましたらぜひご指摘ください。継続してブラッシュアップしていきます。
© 2021 NPO法人AI開発推進協会
本書は物体検出モデルであるFaseter R-CNNについて説明します。(CNNの基礎を理解している前提で記載しています。まだ理解していない方は別冊のCNNの基礎を先に読んでください)
【参考文献、サイト】
- Faseter R-CNN原論文
- Faster R-CNNにおけるRPNの世界一分かりやすい解説
- 物体検出についての歴史のまとめ(1)
- Faster R-CNN: Down the rabbit hole of modern object detection
物体検出の代表的なものにR-CNN、YOLO、SSDなどがあげられます。R-CNNはMicrosoft社によって開発されたアーキテクチャで、R-CNN、Fast R-CNN、Faster R-CNNと発展してきました。説明の際は、R-CNN、Fast R-CNN、Faster R-CNNと順を追って説明していくものが多いですが、R-CNNやFast R-CNNは精度・性能面からもはや使うことはないため、本書ではFaster R-CNNに特化して説明します。過去のモデルの技術を踏襲しているものについては補記して説明します。また物体検出の一般的な説明については、本シリーズ別冊のSSDの説明書を参考にしてください。
1.Faster R-CNN概要
Faster R-CNNは、2015年にMicrosoft社が開発した、Deep LearningによるEnd-to-Endの学習(※1)に初めて成功した物体検出モデルです。(かなりおおまかですが)流れは以下の通りです。
※1:End-to-Endの学習とは、入力(この場合、画像)から目的の結果(出力)を直接単一モデルで学習するる学習方法です。Faster R-CNNでは、物体の境界予測と分類を(事前にRPMを学習したうえで)1つのネットワークとして学習を行います。
※2:Selective Searchとは、候補領域を切り出すためのアルゴリズムの1つです。ピクセルレベルで似た特徴をもつ領域をグルーピングしていくもので、高負荷な処理となります。R-CNNやFast R-CNNは、Selective Searchを使って物体検出を行っていました。
2.Faster R-CNNの構造
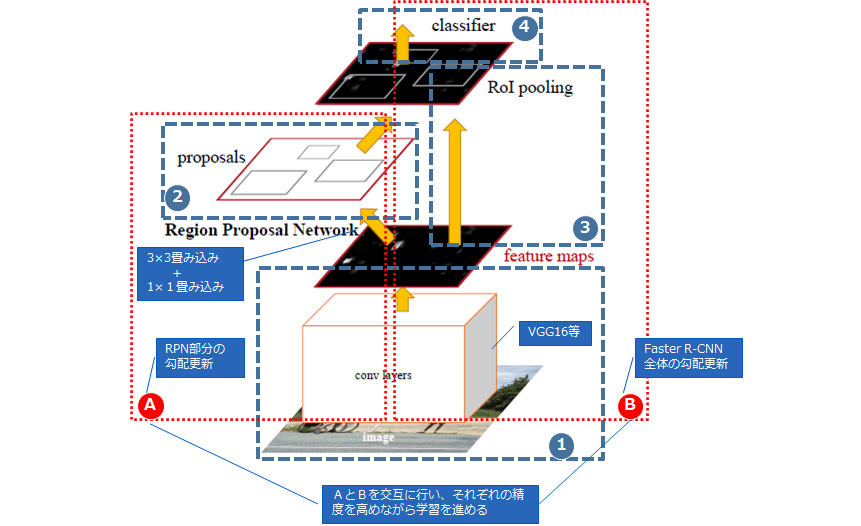
Faster R-CNNは、図1の通り以下の4つの処理から構成されています。
① 入力画像から特徴マップを出力する処理(学習済みVGG16などを流用)
② RPNと呼ばれる物体が写っている場所と、その矩形の形を得る処理
③ ROIと呼ばれる入力を固定長に変換する処理
④ 何が写っているかを判断する分類処理
(1) 特徴マップを出力
最初のステップでは、分類のタスク用に事前トレーニングされたCNN(本書ではVGG16)を使用し、中間層の出力を特徴マップとして使用します。
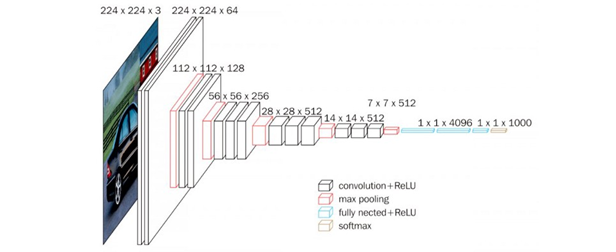
上図2のVGG16で、特徴マップは最後のプーリング層の1つ手前にある14×14×512の層を指します(特徴マップを出力した以降の層、つまり7×7×512以降の層はVGG16の画像分類タスクを行う層のためRPNでは使用しません)。
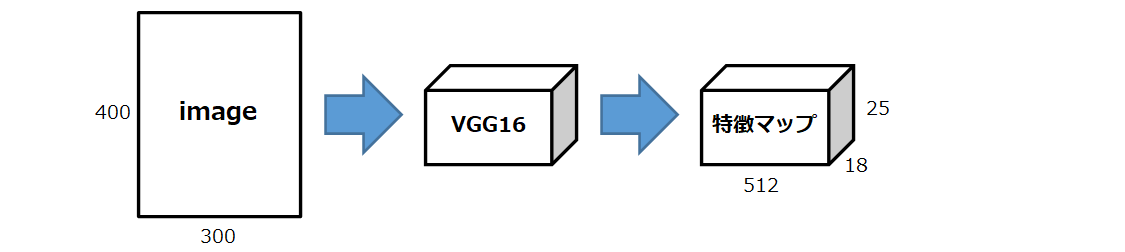
また、特徴マップのサイズは、VGG16の場合、4回プーリングを実施しているため、元の画像の1/16の縦横をもった512次元のデータになります。例えば、元の画像が300×400×3であれば、特徴マップは18×25×512になります。
(2) RPNで物体の位置を検出
RPNはそれ自体が「ある画像のどこに物体が写っているのか(物体が写っている場所と、その矩形の形)」を検出する機械学習モデルです。何が写っているかまではRPNでは判断しません。
ⅰ) AnchorとAnchor boxes
特徴マップを生成したら次にAnchorを設定します。Anchorは特徴マップ上の各点になり、それぞれのAnchorに対して9つ(ハイパーパラメータで指定)のAnchor boxesを作っていきます。各Ancho boxesと正解(Ground Truth)を見比べた情報がRPNを学習させる際の教師データとなります。
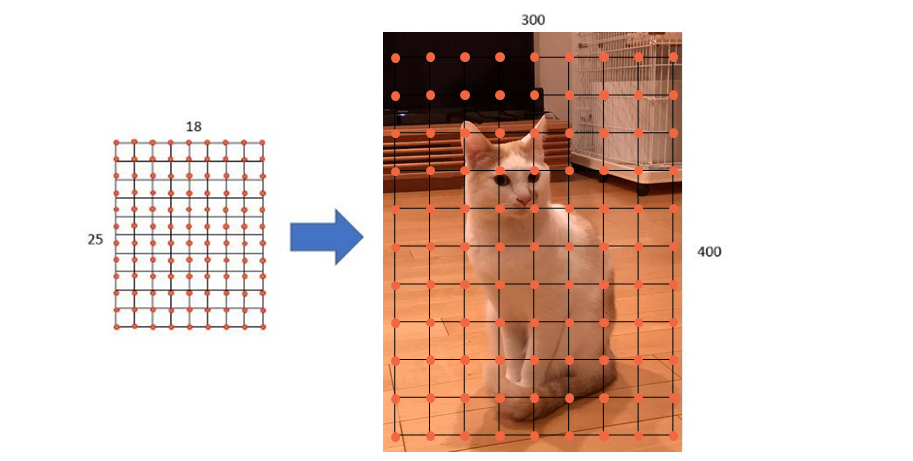
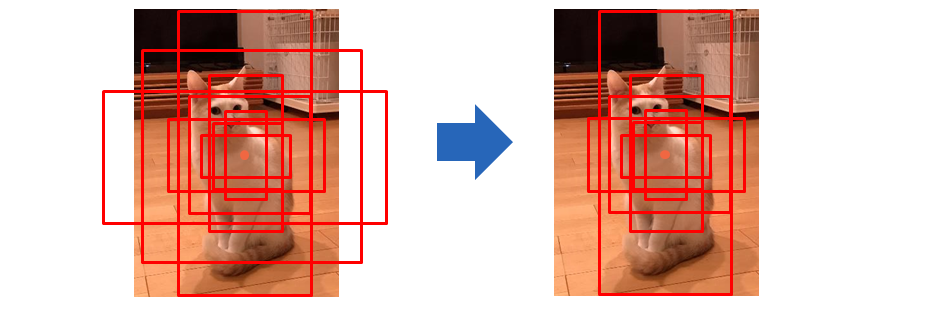
Anchorは矩形を描く際の中心となります。特徴マップが18×25×512の場合、18×25=450個のAnchorが設定され、下図4のように等間隔に設定されます。
各Anchorから「基準の長さ」と「縦横比」をそれぞれ決めることで、複数のAnchor boxesを作り出します。例えば、基準の長さ=(64, 128, 256)、縦横比=(1:1, 1:2, 2:1)とすると、下図5のようなAnchor boxesが生成されます。
このとき1つのAnchorに対して、基準の長さ(3要素) × 縦横比(3要素)=9個の矩形が生成されます。また、各Anchor boxesの面積は揃える必要があります(ex.基準の長さ=64であれば、縦横比=1:1のときは64×64=4096なので、縦横比=1:2のときは縦45×横91(=4096)の矩形、縦横比=2:1のときは縦91×横45(=4096)の矩形)。
実際には画像からはみ出したAnchor boxesは無視するので、実際は以下のようになります。
ⅱ) RPN層での出力について
RPN層では、Anchor boxの中身が背景なのか物体か(下図6のcls layerの2k scores)、物体だった場合は正解(ground truth)とどのくらいズレているのか(下図6のreg layerの4k coordinates)」の2項目を出力します。
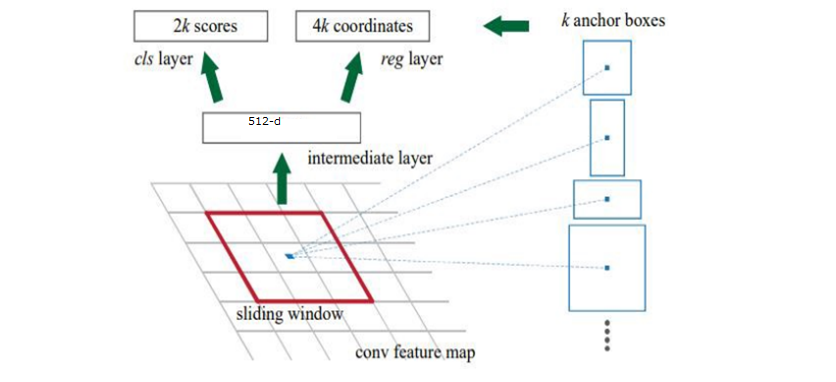
上図6において、「k」はAnchor boxesの数です(今回の例では9)。
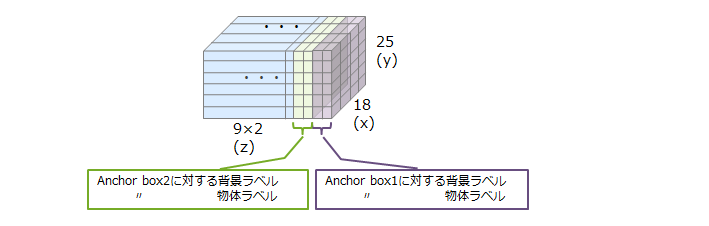
① 「背景が物体か」については、ground truthとAnchor boxesのIoUを計算し、「IoU < 0.3」なら「背景」、「IoU > 0.7」なら「物体」とラベルを付けます。そのため、9(Anchor boxesの数) × 2(ラベル) = 18クラスが作られます。なお、「0.3 ≦ IoU ≦ 0.7」のboxについては、背景とも物体とも言えないので学習には使いません。(IoUの閾値もハイパーパラメータで指定)
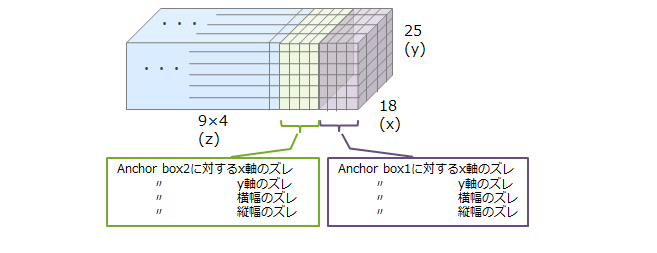
② 「ground truthであるAnchor boxのズレ」については、「中心x座標のズレ」、「中心y座標のズレ」、「横の長さのズレ」、「縦の長さのズレ」という4つの指標で評価します。そのため、9(Anchor boxesの数) × 4(ズレ) = 36クラスが作られます。
3.Faster R-CNNの学習
Faster R-CNNの学習は、RPN部分の学習(図1.Aの部分)とFaster R-CNN全体の学習(図1.Bの部分)を交互に行い、それぞれに精度を高めながら学習を進めます。
(1) RPNの学習
① 入力画像をVGG16等に通して特徴マップを得る
② ①に対し、さらに3×3の畳み込み(512チャネル)を行い、さらに1×1の畳み込みをかけることで、「背景か物体か」用のアウトプットと、「ground truthとのズレ」用のアウトプットの2つを作る
①を入力、②を出力のモデルとして学習します。「物体か背景か」の2値分類問題と、「ground truthとのズレ」の回帰問題を同時に解いていきます。前者はバイナリクロスエントロピー、後者はL1ノルム(絶対値誤差)をベースにした誤差関数を適用して学習を行います。
(2) Faster R-CNN全体の学習
① 入力画像をVGG16等に通して特徴マップを得る(RPNでの学習と同じもの)
② ROI Pooling(※3)を使用し、特徴マップを固定長のサイズにする
③ ②で得たベクトルを4096の全結合層に2回通し、最後にクラス分類用と、矩形ズレ回帰用の2種類の出力を得る
①を入力、②出力のモデルとして、学習します。なお、RPNを学習させるために用いた「3×3の畳み込み + 1×1の畳み込み」は、RPN特有の構造のため、Faster R-CNNで何かを予測する際には使用しません。また、③の全結合層部分の入出力は常に固定サイズとなるため、Faster R-CNNでは入力画像のサイズに依存しない学習、予測が可能になります。
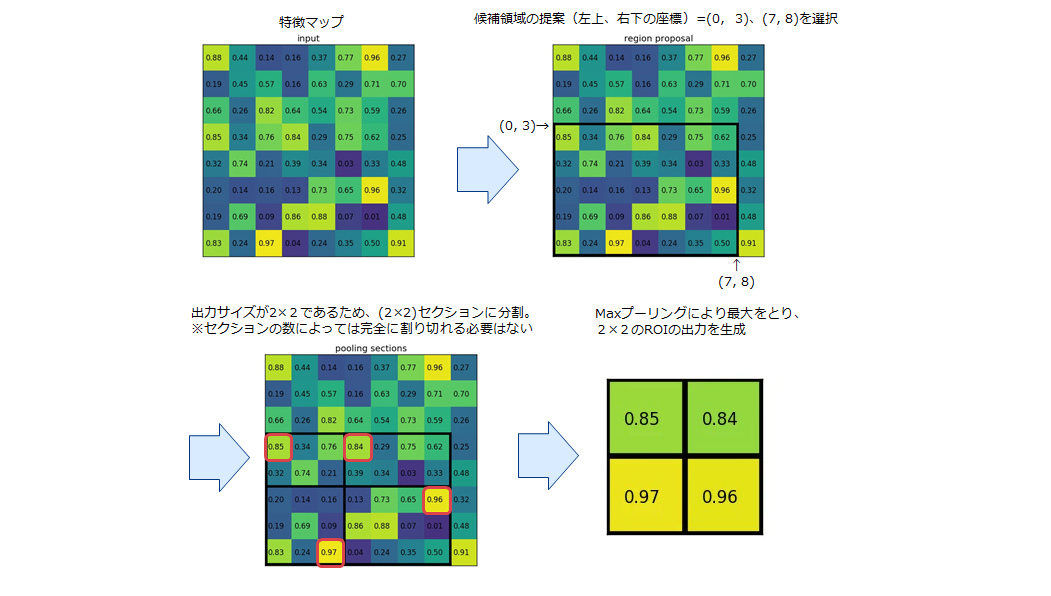
※3:ROIプーリングとは、Fast R-CNNで採用された不均一なサイズの入力に対して最大プーリングを実行し「固定サイズの特徴マップ」を得る手法です。
① 領域候補を同じサイズのセクション(断片)に分割する(このとき、セクションの数は出力の次元と同じ)
② 各セクションで最大値を見つける
③ これらの最大値を出力バッファにコピーする
この結果、サイズの異なる長方形のリストから、固定サイズの対応する特徴マップのリストを素早く取得できます(出力サイズの次元は、入力の特徴マップのサイズや領域提案のサイズには依存せず、領域候補を分割するセクション(断片)の数だけによって決定される)。
ROIプーリングのメリットの1つは処理速度です。フレームに複数の物体候補がある場合、それらのすべてに対して同じ入力特徴マップを使用でき、一般的に非常にコストがかかるモデルネットワーク処理の初期段階での畳み込み計算を大幅に削減可能なためです。実際の動作は以下のようなになる。
例)8×8の単一の特徴マップの1つの関心領域(左上、右下の座標)=(0, 3)、(7, 8)に対して、
2×2のRoIプーリングを実行
【参考サイト】Region of interest pooling explained
4.おわりに
Faster R-CNNの説明は以上になります。Faster R-CNNはYOROやSSDとならび代表的な物体検出モデルです。 是非マスタしましょう。SSDについては、別冊にて執筆しておりますので、興味のある方はぜひ参照ください。