本書は、【SSD(物体検出)】の予測時のコード(keras)がどのように実装されているのか説明します。 SSDモデルをより深く理解するのに役立てばと思います。
今回参照したコードは、下記のGitHUBのコードです。
https://github.com/rykov8/ssd_keras
実際に動かす際に必要となる環境準備は下記のサイトを参考にしてください。
https://github.com/weiliu89/caffe/tree/ssd
※筆者が所属するNPO法人の勉強用にメモしたものですので、誤りや不足、加筆修正すべきことろがありましたらご指摘ください。継続してブラッシュアップしていきます。
また、SSDモデルの解説をQiitaに投稿していますので合わせてご参照ください。
0.全体の処理イメージ
全体の処理イメージは図1のようになります。
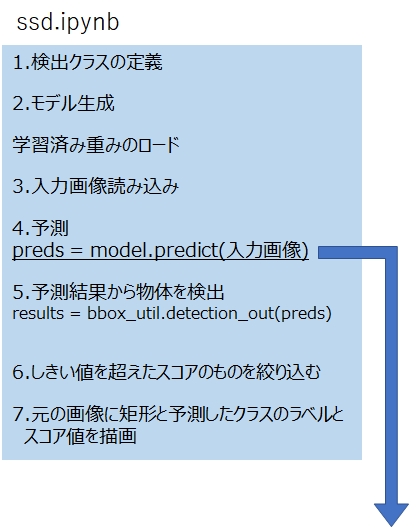

【図1】 全体処理イメージ
以下、コードを表示しながら順に説明します。
1.検出クラスの定義
摘出するクラスは以下のように定義されています。
voc_classes = ['Aeroplane', 'Bicycle', 'Bird', 'Boat', 'Bottle',
'Bus', 'Car', 'Cat', 'Chair', 'Cow', 'Diningtable',
'Dog', 'Horse', 'Motorbike', 'Person', 'Pottedplant',
'Sheep', 'Sofa', 'Train', 'Tvmonitor']
NUM_CLASSES = 21
デフォルトの矩形(BBOX)数は、本コードでは以下の数になっています。
38×38×3、19×19×6、10×10×6、5×5×6、3×3×6、1×1×6 = 7308個
算出は、ssd_layers.pyの以下のコードで算出しています。
111 def get_output_shape_for(self, input_shape):
112 num_priors_ = len(self.aspect_ratios)
113 layer_width = input_shape[self.waxis]
114 layer_height = input_shape[self.haxis]
115 num_boxes = num_priors_</color> * layer_width * layer_height
116 return (input_shape[0], num_boxes, 8)
ここで、num_priors_は、ネットワーク定義(ssd.py)のPriorで指定した「aspect_ratios」からPriorクラス初期化時に算出しています。
※SSDのネットワークモデルはssd.pyに記載されています。
152 priorbox = PriorBox(img_size, 30.0, aspect_ratios=[2],
152 variances=[0.1, 0.1, 0.2, 0.2],
154 name='conv4_3_norm_mbox_priorbox')
・・・
171 priorbox = PriorBox(img_size, 60.0, max_size=114.0, aspect_ratios=[2, 3],
172 variances=[0.1, 0.1, 0.2, 0.2],
173 name='fc7_mbox_priorbox')
・・・
具体的には、aspect_ratios=[2]であれば、デフォルトで作る「1」と指定したリスト値である「2」および「2」をflipさせた「0.5」の3つになります(その他「2, 3」の指定がありますが、このときmaxsizeを指定しているとデフォルトの「1」に加え、「1」をさらに追加するので、「1, 1, 2, 3, 0.5, 0.333」の6つになります)。
2.モデルの生成
モデルの生成は、ssd.ipynbで実施しています。
またモデルの生成後に、学習済み重みのロードを実施しいてます。
input_shape=(300, 300, 3)
model = SSD300(input_shape, num_classes=NUM_CLASSES)
model.load_weights('weights_SSD300.hdf5', by_name=True)
3.入力画像の読み込み
ssd.ipynbでは下記のように入力するPASCAL VOC2007の画像を1枚づつ指定しています。
inputs = []
images = []
img_path = './pics/fish-bike.jpg'
img = image.load_img(img_path, target_size=(300, 300))
img = image.img_to_array(img)
images.append(imread(img_path))
inputs.append(img.copy())
・・・
ランダムに画像を抽出したい場合は、上記コードを下記のように置き換えれば可能です。
import random
import pickle
image_meta_file = ./path/VOC2007.P #VOC2007.Pのファイル情報
gt = pickle.load(open(image_meta_file, 'rb'))
keys = sorted(gt.keys())
imgs = random.sample(keys, n) # nはランダムに入力する画像枚数を指定
for img_name in imgs:
img_path = path_prefix + img_name
images.append(imread(img_path))
img = image.load_img(img_path, target_size=(300, 300))
img = image.img_to_array(img)
inputs.append(img.copy())
4.予測(prediction)
次にいよいよ予測に入ります。
下記のコードで予測を実施しています。
preds = model.predict(inputs, batch_size=1, verbose=1)
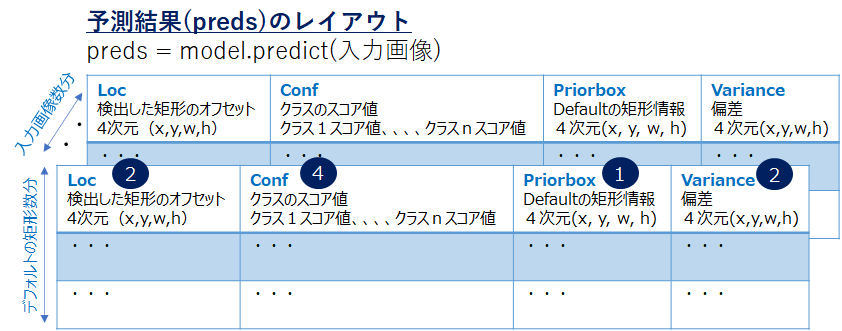
返却されるpredsは、図1に記載のとおりです。
ここではinputsされた画像枚数分を一括して処理しています。また、全矩形(7308)×全クラス(21)を予測した結果が返却されます。
5.予測結果から物体を検出
先ほどの「preds」をssd_util.py/BBoxUtilityクラスのdetection_out()に渡して物体検出の各種処理を行います。
from ssd_utils import BBoxUtility
・・・
results = bbox_util.detection_out(preds)
具体的には以下の流れになります。
まずは矩形処理を行うdecode_boxes()を呼び出します。以降の①~③はこのdecode_boxes()で行われます。
211 decode_bbox = self.decode_boxes(mbox_loc[i],
212 mbox_priorbox[i], variances[i])
①priorboxの情報から各BBOXの中心位置、幅、高さを算出
164 prior_width = mbox_priorbox[:, 2] - mbox_priorbox[:, 0]
165 prior_height = mbox_priorbox[:, 3] - mbox_priorbox[:, 1]
166 prior_center_x = 0.5 * (mbox_priorbox[:, 2] + mbox_priorbox[:, 0])
167 prior_center_y = 0.5 * (mbox_priorbox[:, 3] + mbox_priorbox[:, 1])
②検出したバウンデックスボックスのオフセット値とVariance値から矩形情報(中心位置、幅、高さ)の計算
168 decode_bbox_center_x = mbox_loc[:, 0] * prior_width * variances[:, 0]
169 decode_bbox_center_x += prior_center_x
170 decode_bbox_center_y = mbox_loc[:, 1] * prior_width * variances[:, 1]
171 decode_bbox_center_y += prior_center_y
172 decode_bbox_width = np.exp(mbox_loc[:, 2] * variances[:, 2])
173 decode_bbox_width *= prior_width
174 decode_bbox_height = np.exp(mbox_loc[:, 3] * variances[:, 3])
175 decode_bbox_height *= prior_height
③②の計算結果から矩形の左上、右下の座標を計算
176 decode_bbox_xmin = decode_bbox_center_x - 0.5 * decode_bbox_width
177 decode_bbox_ymin = decode_bbox_center_y - 0.5 * decode_bbox_height
178 decode_bbox_xmax = decode_bbox_center_x + 0.5 * decode_bbox_width
179 decode_bbox_ymax = decode_bbox_center_y + 0.5 * decode_bbox_height
④クラスconfの処理
続いて予測したクラスのスコア値(conf)を用いて、最終的に使う矩形を選択します。
- 予測したクラスから背景を除き、スコア値がしきい値以上のものを抽出します。
ここでのしきい値は最終的に選択する矩形ではなく、あくまでも処理対象とするスコア値となります(デフォルト値 0.01)。
214 if c == background_label_id:
215 continue
216 c_confs = mbox_conf[i, :, c]
217 c_confs_m = c_confs > confidence_threshold
さらに NNS(Non Maxinum Suppresion) により重なって抽出された矩形でスコア値が低いものは除外します。
NMSは、Tensorflowのライブラリィ(tf.image.non_max_suppression)を使って処理されます。
218 if len(c_confs[c_confs_m]) > 0:
219 boxes_to_process = decode_bbox[c_confs_m]
220 confs_to_process = c_confs[c_confs_m]
221 feed_dict = {self.boxes: boxes_to_process,
222 self.scores: confs_to_process}
223 idx = self.sess.run(self.nms, feed_dict=feed_dict) #★NMS実行
224 good_boxes = boxes_to_process[idx] #矩形の絞り込み
225 confs = confs_to_process[idx][:, None]
226 labels = c * np.ones((len(idx), 1))
- results(返却値)に追加
resulutsレコードにクラス単位で処理した結果を追加していきます。
227 c_pred = np.concatenate((labels, confs, good_boxes),
228 axis=1)
229 results[-1].extend(c_pred)
- 上記をすべてのクラスで実施し、スコア値が高い順にソートしてresultsを返却します。
このときresults[-1][:keep_top_k]にあるようにクラスのスコア値が上位K個のみ抽出します(top-k-filterring)。
230 if len(results[-1]) > 0:
231 results[-1] = np.array(results[-1])
232 argsort = np.argsort(results[-1][:, 1])[::-1]
233 results[-1] = results[-1][argsort]
234 results[-1] = results[-1][:keep_top_k]
235 return results
6.しきい値を超えたスコアのもの絞り込む
ssd.ipynbに戻り、detection_out()から返却されたresultsを参照し、最終的に描画する矩形を選択します。
下記の例では「0.6」以上のスコアに絞っています。
for i, img in enumerate(images):
# Parse the outputs.
det_label = results[i][:, 0]
・・・
# Get detections with confidence higher than 0.6.
top_indices = [i for i, conf in enumerate(det_conf) if conf >= 0.6]
top_conf = det_conf[top_indices]
・・・
7.元の画像に矩形と予測したクラスのラベルとスコア値を描画
最後に、元の画像に検出した矩形と、クラスのラベルとそのスコア値を左上に描画して終了になります。
for i in range(top_conf.shape[0]):
xmin = int(round(top_xmin[i] * img.shape[1]))
ymin = int(round(top_ymin[i] * img.shape[0]))
xmax = int(round(top_xmax[i] * img.shape[1]))
ymax = int(round(top_ymax[i] * img.shape[0]))
score = top_conf[i]
label = int(top_label_indices[i])
label_name = voc_classes[label - 1]
display_txt = '{:0.2f}, {}'.format(score, label_name)
coords = (xmin, ymin), xmax-xmin+1, ymax-ymin+1
color = colors[label]
currentAxis.add_patch(plt.Rectangle(*coords, fill=False,
edgecolor=color, linewidth=2))
currentAxis.text(xmin, ymin, display_txt, bbox={'facecolor':color,
'alpha':0.5})
plt.show()
結果は、こんな感じです。
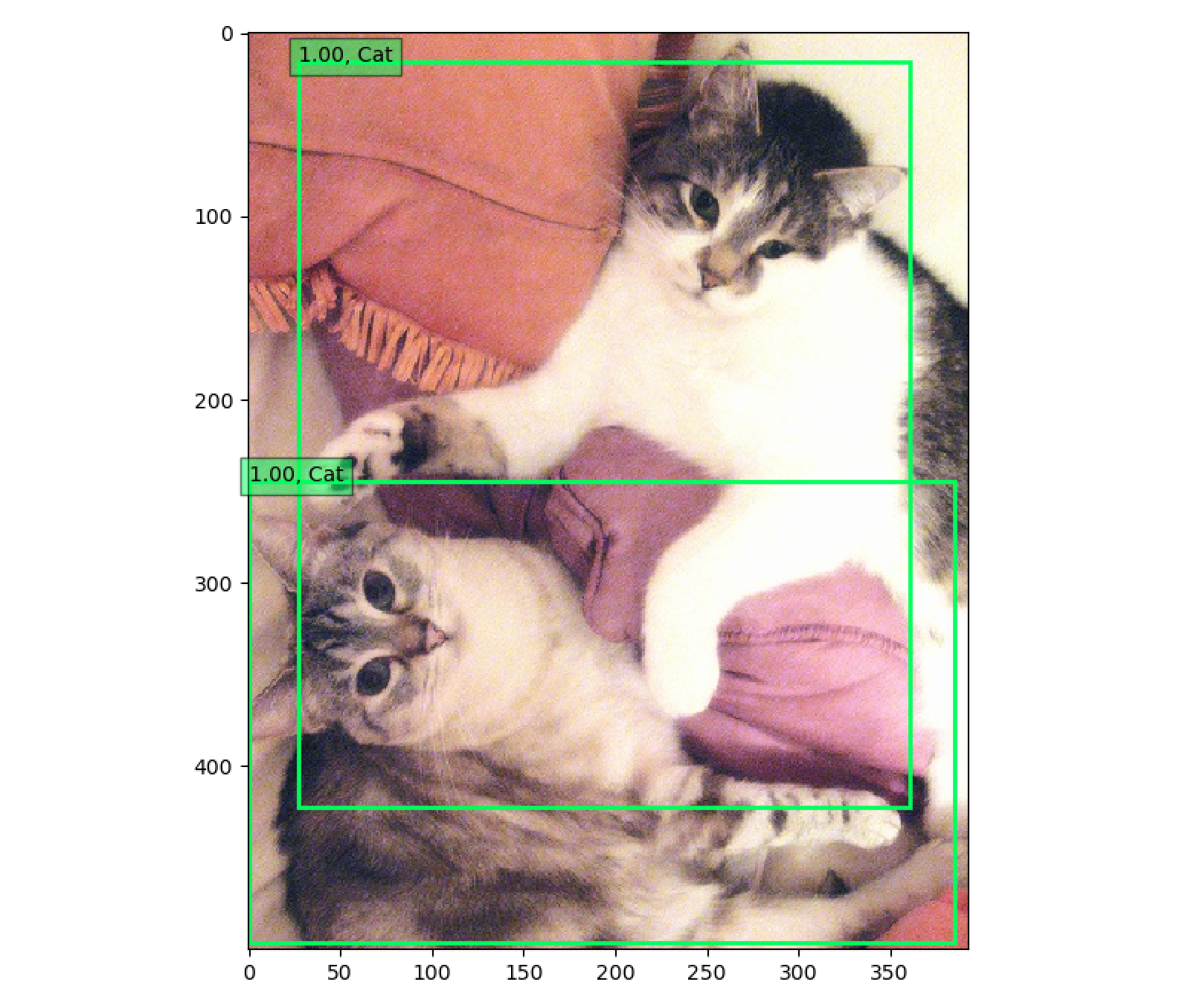
【図2】 SSD出力イメージ(例)
おわりに
いかがでしたでしょうか? 実装されているコードは想定よりシンプルだったのではと思います。SSDでの物体検出はPCでも十分に動くと思いますので(さすがに学習は厳しいですが、筆者はMacbook上のWindows10(Parallels Desktop)でも問題なく動きます)、実際に動かしてみてはいかがでしょうか。
本書がSSDがコード上でどう実装されているのかお役に立てれば幸いです。