本記事では、リアルな画像を生成できるStyleGAN2について説明します(CNNやGANの基礎を理解している前提で記載しています。まだ理解していない方は別冊のCNNやGANの基礎を先に読んでいただけると理解しやすいと思います)。
また、どんなものなのかを実際に体験するための手順も別記事にて投稿しています。興味のある方は、こちらも見ていただければ幸いです。
0.はじめに
StyleGANは、高解像度の画像生成可能なProgressiveGANをベースに画像の画風変換(Style Transfer)を取り入れたアルゴリズムです。また、StyleGAN2は、StyleGANの課題を改善したアルゴリズムです。そのため、StyleGAN2を理解するために、ProgressiveGAN、StyleGAN、StyleGAN2と順を追って理解を進めていきたいと思います。
1 ProgressiveGAN(PGGAN)
(1) PGGAN とは
PGGANは、GANにおける高解像の画像生成の以下3つの課題を回避することで高解像度の画像生成を可能にしたアルゴリズムです。
- 高解像度の画像では、正解画像と偽物画像との識別がDiscriminatorで容易となり、GeneratorとDiscriminatorの学習が十分に行えない。
- 高解像度の画像を扱うので通常より多くのメモリが必要になる。そのため、より小さなミニバッチサイズで学習を行ってしまうと学習が不安定になる。
- 学習に時間がかかる。
基本コンセプトは、「GeneratorとDiscriminatorを、より簡単な低解像度の画像から段階的に学習させて、学習の段階が進むにつれて高解像度の情報を持つ新しい層を追加してく」というものです。これにより、GANの高解像の画像生成の課題の回避と、学習の高速化が可能になっています。
(2) PGGANのアーキテクチャ
PGGANのアーキテクチャを図1に示します。
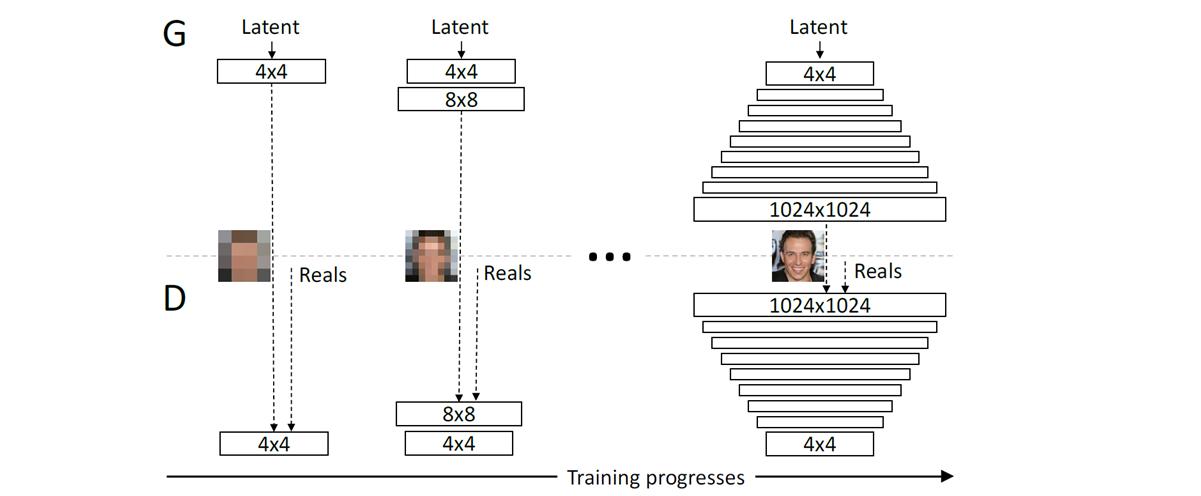
Progressiveなネットワークの構成と学習(Progressive growing of GANs)
以下のように4×4の画像から1024×1024の画像まで、段階的(Progressive)な処理で行われます。
①Training Progresses 1
②Training Progresses 2
③Train Progresses 3~9
-
学習の実装について
学習においては、以下のような実装があります。
①Training Progresses1~8を1エポック間に渡って学習し、最後のTraining Progresses9を残りのエポックを学習させる。
②1エポック目(Training Progresses1)、2エポック目(Training Progresses1~2)、3エポック目(Training Progresses2)、4エポック目(Training Progresses2~3)、、、15エポック目(Training Progresses8~9)、16~最終エポック目(Training Progresses9)で学習させる。 -
Progressiveなネットワークの効果
画像生成タスクにおいては、画像の大域的特徴量と局所的特徴量の両方を捉えることが重要になりますが、Progressiveなネットワークでは単に画像を高解像度化するだけではなく低解像度の処理で画像の大域的特徴量を先に捉え高解像度の処理で局所的特徴量を捉えるという効果もあります。
(3)高解像度の画像生成のための工夫
A) なめらかな解像度の変換
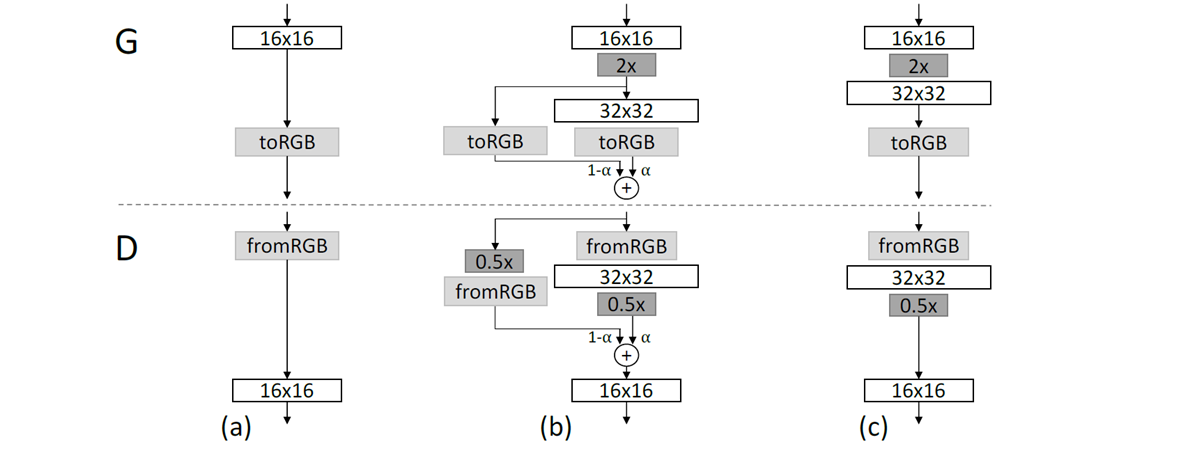
PGGANでは、上述のように画像の解像度をnearest neightborフィルタリングとaverage poolingとを用いて、それぞれ2倍、1/2倍の倍々でアップサンプリングやダウンサンプリングしていきますが、ある解像度で十分に学習させたネットワークであっても、この倍々処理を急激に行うと非なめらかな変化を生じさせてしまいます。そのためPCGANではアップサンプリングおよびダウンサンプリングのための新しい畳み込み層をネットワークに追加するときに、画像のRGB値を線形補間によって、なめらかに変化させるようにしています。
B) 生成画像の多様性向上とモード崩壊防止のための工夫
PGGANでは、前述のような高解像度の画像生成のための工夫だけでなく、minibatch standard deviation(簡略化されたminibatch discrimination)を用いて生成画像の多様性向上とモード崩壊防止のための工夫もしています。
GANの課題の一つとしてモード崩壊(学習が不十分な識別器に対して生成器を最適化した場合や、生成器への入力ノイズzの潜在変数としての次元が足りていない場合などにおいて、生成器による生成画像がある特定の画像に集中してしまい、学習用データが本来持っている多様な種類の画像を生成できなくなってしまうこと)があります。Minibatch discriminationでは、このモード崩壊を防止するために、discriminatorにミニバッチデータ内のデータの多様性を検出できる仕組みを導入しています。PGGANでは、このminibatch discriminationの仕組みを大幅に簡略化した仕組みであるminibatch standard deviation を導入することで、minibatch discriminationのように、新しいハイパーパラメータを必要とすることなく、生成データの多様性を向上させモード崩壊を防止しています。
ⅰ) ミニバッチデータ内の各画像データの各ピクセル値(RGB値)に対して、同じ位置に対応しているピクセル値(RGB値)で標準偏差を計算する。
ⅱ) すべての高さ(H)と幅(W)チャネル数(C)で、この各ピクセル(=標準偏差)を平均化しスカラー値を取得する。
ⅲ) 得られるスカラーをコピーし結合することで、1つのH×Wのテンソル(=特徴マップ)を取得する。
C) 学習の安定化のための工夫
一般的にGANにおいては学習を安定化させることを目的として、batch normalizationの仕組みがネットワークに導入されています。しかしながら、PGGANではbatch normalizationによる学習安定化効果は見られないとして、別の学習安定化のための工夫を使用しています。
①Equalized learning rate ※重み更新に対する工夫
一般的にディープラーニングにおいては学習率が減衰するような最適化アルゴリズム(Adam等)を用いてネットワークの重みを更新します。PGGANではこのような重みの更新ではなく、以下に示すようなもっと単純な方法でネットワークの重みを更新します。
ⅰ)GeneratorとDiscriminatorのネットワークの各層(ⅰ)の重み wi の初期値を、wi ~ N(0, 1) で初期化する。
ⅱ)初期化した重みを、各層の実行時(=順伝搬での計算時)に、以下の式で再設定する。
\hat{w_{i}}=w_{i}/c
(標準化定数 c = √2/層の数)
②Pixelwise feature vector normalization in generator ※データに対する工夫
GeneratorとDiscriminatorの不適切な競争の結果として、GeneratorとDiscriminatorからの出力信号(=偽物画像と判別結果)が制御不能になることを防止するために、PGGANではGeneratorの各畳み込み層の後の中間層からの出力(=特徴ベクトル)に対して「各ピクセル毎」に以下のような特徴ベクトルの正規化処理を行います。
b_{x,y}=a_{x,y}/\sqrt{\frac{1}{N}\sum_{j=0}^{N-1}(a^j_{x,y})^2+\epsilon}
この正規化手法により、(batch normalizationと同様にして)学習の際の変化の大きさに応じて信号を増幅または減衰ができるようになるので、結果として学習の安定化が得られます。
2 StyleGAN
(1) StyleGAN とは
StyleGANは、ProgressiveGANをベースに非常にクオリティの高い画像を高解像度で生成できます。また、単に高解像度の画像を生成できるだけでなく、人物画像の高レベルで大域的な属性(顔の輪郭、眼鏡の有無など)から、局所的な属性(しわや肌質など)まで切り分けをアルゴリズムで制御できるようになっています。
(2) StyleGANのアーキテクチャ
StyleGANの全体アーキテクチャとGeneratorの詳細なアーキテクチャを図3に示します。
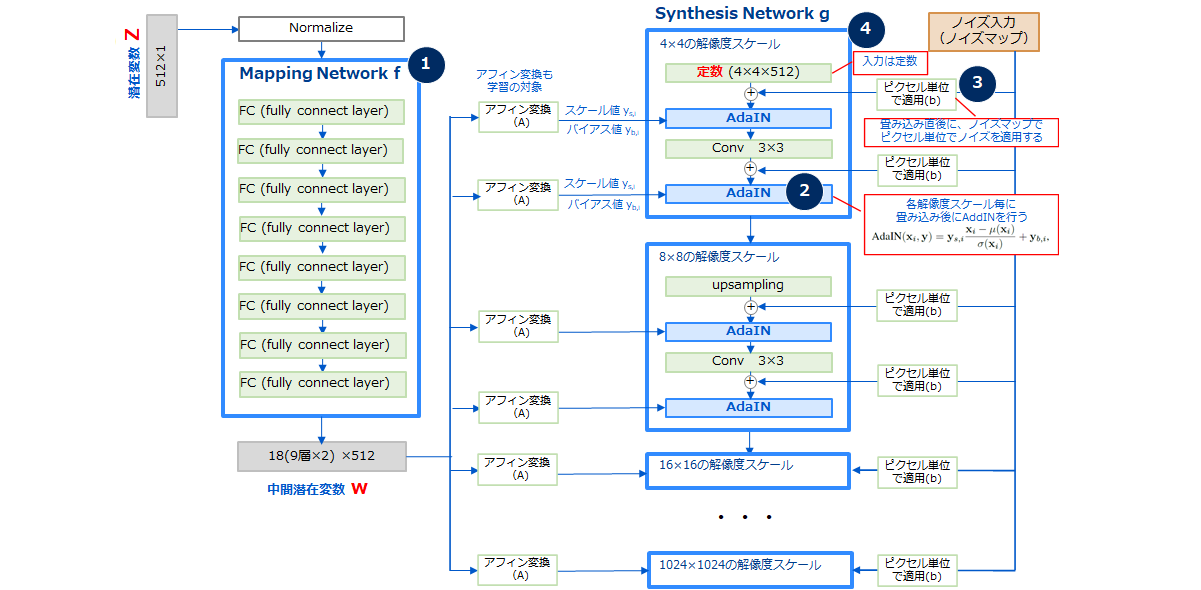
(3) StyleGANの特徴
①Mapping network f(潜在空間zから潜在空間wへの写像と潜在表現の獲得)
従来のGANでは、入力ノイズ z ∈ Z (Z:潜在空間)をそのままGeneratorに入力していましたが、この方法では図4(B)に示すように画像の特徴量の一部の組み合わせが存在しないケースにおいて、入力ノイズzが存在する潜在空間Zは、線形ではなくentanglement(もつれ)のある歪んだ空間となります。
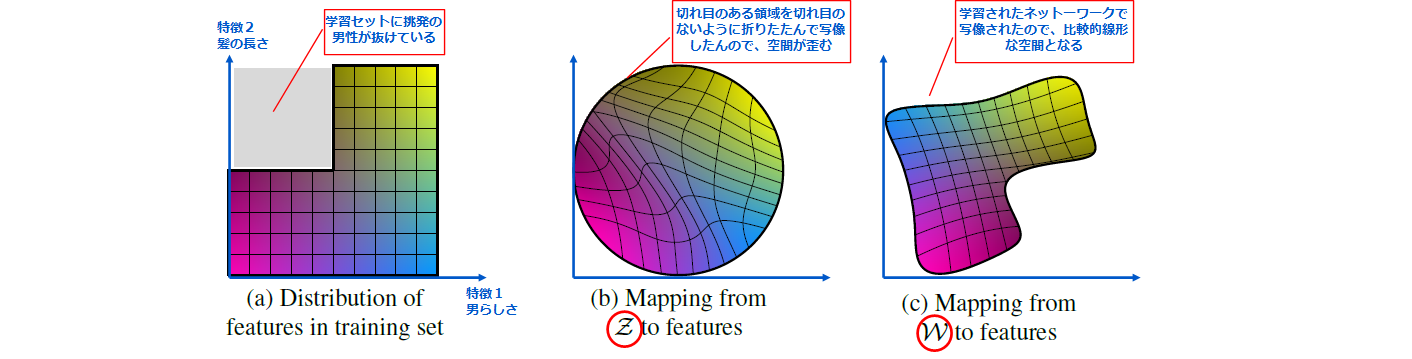
このようなentanglement(もつれ、歪み)のある空間では、潜在空間のある部分空間からサンプリングしたベクトル(図4では特徴軸上のベクトル)だけを使って画像を生成したときには、複数の要素が同時に変動してしまいます(ex. 性別や肌色などが同時に代わる)。 ※一方で、disentangle(解きほぐし)されている潜在空間では、潜在空間のある部分からサンプリングしたベクトルだけを使って画像を生成したときには変動する要素が1つのみであるため意図している画像の生成がしやすくなります。
このような問題に対処するために、StyleGANでは潜在変数である入力ノイズzをmapping network fという8層のMLP(多層パーセプトロン)で構成されるネットワークに入力し、中間的な潜在空間Wへと写像して、別の潜在変数w∈Wを獲得した上で後段のSynthesis Networkに入力します。Mapping networkは学習されるネットワークであるため潜在変数wは図4(C)に示すように、画像の特徴量のentanglementの少ない状態で最適化されることが期待できます。
②Adaptive Instance Normalization(AdaIN)(各解像度スケールでのAdaINの採用)
AdaINは、Instance Normalizationの発展版で1つのモデルであらゆるスタイル(画風)への変換を可能にした正規化手法です。StyleGANにおいてAdaINは、Mapping Networkによって得られた中間潜在変数wに対して、アフィン変換(平行移動変換)を施した後に、このアフィン変換によるスケール値とバイアス値を、それぞれのAdaINの制御パラメータであるスケール項ys,i とバイアス項 yb,i として用います。
AdaINは、以下の式で与えられます。
AdaIN(x_{i},y)=y_{s,i}\frac{x{i}-\mu(x_{i})}{\sigma(x_{i})}+y_{b,i}
このAdaINの処理は、特徴マップ単位(=チャンネル単位)での正規化処理になっていますが、このAdaINによる変換を各解像度スケール(4×4、8×8、、、1024×1024)の畳み込みの後に行うことで、各解像度での画像全体に渡って大域的にスタイルを変化させることができるようになります。
③Pixel-wise Noise InputとStochastic variation(ピクセル単位のノイズ入力と確率的変動)
従来のGANでは局所的な特徴生成も大局的な特徴生成と同様に潜在変数としての入力ノイズを直接Generatorに入力することで実現するアーキテクチャになっていましたが、前述の潜在空間の歪みによりノイズの影響を制御することが困難でした。
StyleGANでは、Synthesis networkでの各畳み込みの直後にノイズマップでピクセル単位のノイズを直接加えることで局所的な特徴生成を直接制御することを可能にしています。
※前述のAdaINが大域的なスタイルの変化、ノイズマップが局所的なスタイルの変化を制御します。ノイズの影響と効果については図5のようになります(論文より)。

(a)ベースとなる生成された画像 (b)ベースとなる画像はそのままで、それぞれノイズを変えたときの4つの画像 (c)ノイズの影響を受けている個所をグレースケールで表示した画像(白が影響大)、 髪の毛やシルエット、背景の一部、目の反射にも影響しているが、アイデンティティやポーズといった大域的な特徴には影響を与えていません。
図6は、Synthesis Networkのどの層にノイズを加えるかで生成画像の効果を示した図です(論文より)。

(a)全ての層にノイズを加えた場合 (b)ノイズを加えない場合 (c)高解像度の層(64×64~1024×1024)のみにノイズを加えた場合 (d)低解像度の層(4×4~32×32)のみにノイズを加えた場合
ノイズを加えないと全体的に均一で立体感のない画像が生成されています。ノイズを加えると肌質などの局所的で細かなテクスチャーが加味されてよりリアルな画像が生成されています。そしてノイズを加える層で、粗いノイズ(低解像度)では髪の毛が大きく巻いていたり背景が大きく見えたりしますが、細かいノイズ(高解像度)では髪の毛の巻具合や背景の細かさ肌の毛穴などが浮かび上がってきます。
④progressiveGANから入力層を排除(代わりに学習済み定数マップを入力)
ProgressiveGANでは、乱数を生成してGeneratorへの初期入力(4×4)としています。
一方StyleGANでは入力層を排除し、学習済み定数マップ(4×4×512)を入力します。これは、StyleGANが生成画像を中間潜在変数wとAdaIN、そしてノイズマップによって制御しており可変な入力が不要であるためです。
(4) Style Mixing
Style Nixingは、潜在空間よりサンプリングした2つの潜在変数z1、z2 ∈ Z 、及び2つの中間潜在空間 w1、w2 ∈ W に関してSynthesis NetwrokのAdaINのパラメータとして入力する際に、ある解像度スケールまでは z1・w1 を入力し、それ以降の解像度スケールには z2・w2 を入力するように切り替えます。こうすることでSynthesis Networkは、隣接した解像度スケールの層間で画風(Style)に相関があるように学習しなくなるので、画風の影響を各解像度スケールの層に局所化させることが可能になります。
図7は2つの中間潜在変数を切り替えたときの例になります(論文より)。
低解像度(4×4 ~ 8×2)で中間潜在変数をw1->w2に切り替えると、ポーズやヘアスタイル、顔の形、眼鏡などの大域的な特徴がソースBからもたらせられますが、すべての色(目、髪、照明)と細かい顔の特徴はソースAに似ています。代わりに中間解像度(16×16〜32×32)で中間潜在変数をw1->w2に切り替えると、より小さなスケールで顔の特徴やヘアスタイル、目の開閉がソースBから継承されますが、ポーズや一般的な顔の形状、眼鏡はソースAから継承されます。
最後に、高解像度(64×64 ~ 1024×1024)で中間潜在変数をw1->w2に切り替えるとソースBから主に配色やピクセル単位の局所的な特徴が引き継がれます。

(5) 潜在空間におけるentanglement(もつれ)とdisentanglement(解きほぐし)の評価
StyleGANでは、entanglement/disentanglementを定量化する指標として、Perceptual path length(PPL)とLinear separabilityの2つの指標を使っています。
(ⅰ)Perceptual path length(PPL)
潜在空間ベクトルの補間により、画像に驚くほど非線形の変化が生じる可能性があります。
StyleGANでは、このような線形補間においてどれだけ急激に画像が変化するのかをPPLで計測します。PPLは文字通り「人間の知覚的」に潜在空間上で画像がなめらかに変化するのかの指標です。
2つの潜在変数 z1、z2 を比率tで混ぜ合わせた潜在変数で生成した画像と、比率t+εで混ぜ合わせた潜在変数で生成した画像の距離の期待値となっています。実態はVGG(画像認識ネットワーク)を使用し、それぞれが算出する特徴量ベクトルの距離を「知覚的」な距離としています。解析的には求めることはできないので、多くの画像で計算を行って期待値をとった結果がPPLの値になります(値が小さいほど潜在空間が知覚的になめらかだということになります)。
- 潜在空間ZでのPPL
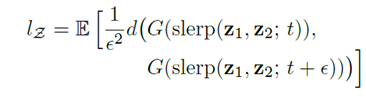
- 中間潜在空間wでのPPL
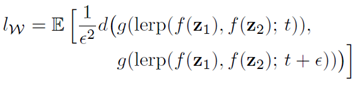
(ⅱ) Linear separability
disentanglement(解きほぐし)されている潜在空間では、潜在空間のある部分からサンプリングしたベクトルだけを使って画像生成したときは、生成された画像で変動する要素は1つのみである。これは見方をかえると潜在空間の各点が線形分離可能であることを意味している。そのためStyleGANでは、潜在空間内の点がどれだけうまく線形分離可能であるかを測定することでentanglement/disentanglementの定量的指標として利用しています。
※興味がある場合、詳細なロジックについては論文を参照してください
3 StyleGAN2
(1) StyleGAN2とは
StyleGAN2は、StyleGANで課題となっていたdropletと呼ばれるノイズが生じる問題(図8)や生成画像の特徴の一部が不自然になる事象(図9)を、アーキテクチャを見直して解消したものです。
-
dropletと呼ばれるノイズが生じる問題

図8.dropletの発生の例 -
生成画像の特徴の一部が不自然になる事象
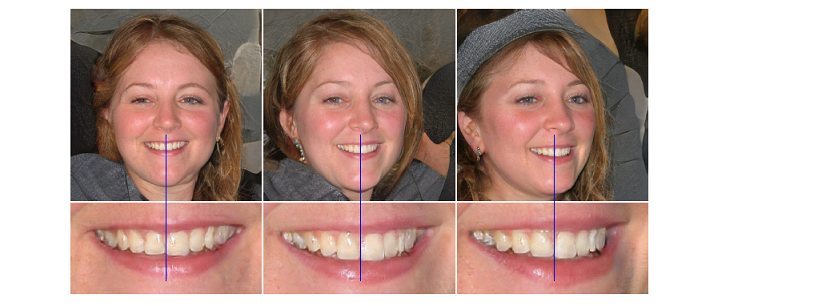
図9.生成画像の特徴の一部が不自然になる例(顔の向きに関わらず正面を向いて生成される歯)
(2) StyleGAN2の特徴
StyleGAN2では、上記の課題を解決するために主に以下の3つの観点での改善が行われています。
(ⅰ)AdaINのように実際の統計量で正規化するのではなく、推定の統計量で正規化することで不要なモードの顕在化を防ぎ、「dropletを除去」する。
(ⅱ)Progressive Growingの代わりにskip connectionを持った階層的なGeneratorを用いることで、「生成画像の特徴の一部が不自然になる事象」を低減する。
(ⅲ)潜在空間をなめらかにすることで、画像品質を向上する。
(ⅰ) dropletの除去(論文2章:Instance normalization revisited)
StyleGANでのAdaINは実際に入ってきたデータの統計量を使って正規化していますが、これがdropletの原因になっていました。この対策として実際に入ってきたデータの統計量ではなく、「推定の統計量」を使って畳み込みの重みを正規化することでdropletの発生を防げることがわかりました。実際には下記の図10のように対策しています。
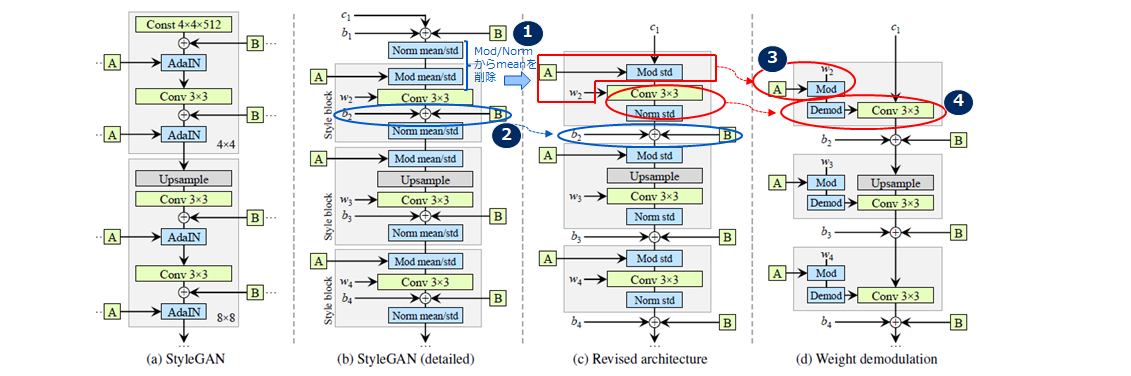
図10(a)が元のStyleGANのアーキテクチャで、「A」はスタイルを生成する中間潜在変数wから学習されたアフィン変換を示し、「B」はノイズブロードキャスト操作です。図10(a)のAdaINを詳細に記述すると2つの手順に分解できます。1つ目はコンテンツ情報を自身の統計量で正規化(Norm mean/std)すること、2つ目は正規化されたコンテンツ情報をスタイル情報「A」を線形変換(Mod mean/std)することです。また、学習した重み(w)、バイアス(b)および入力を(c)としてボックスごとに1つのスタイルがアクティブになるように灰色のボックスをStyle blockとして詳細化したものが図10(b)になります。なお活性化関数(leaky ReLU)は、バイアスを追加した直後に常に適用されます。 次に図10(c)に記載いてあるように、実際の統計量である平均値(mean)を取り除き正規化の操作を標準偏差(std)による割り算のみに、スタイルの線形変換も係数の掛け算だけにします(図10①)。そしてノイズ挿入部はStyle blockの中にある必要はないのでStyle blockの外に出します(図10②)。 次に図10(d)で、最初のStyleベクトルによる線形変換を畳み込みの内部で実施します。Style block内ではMapping Networkで生成したスタイルベクトルwを線形変換したsi(ys,i)をかけています。コンテンツ画像にsiをかけたものを畳み込みの重みwijkで処理するという操作は、コンテンツ画像を重みwijkとsiの積で畳み込むということと等価なので、この操作は以下のように書き換えることができます(図10③)。
w'_{ijk}=s_{i}・w_{ijk}
最後に、正規化(norm)の処理(図10(C)では標準偏差で割っているだけ)を畳み込みの内部で実施するようにします。入力が標準正規分布に従っていると仮定する出力画像の標準偏差は重みのL2ノルムによってスケーリングされ、以下のようになります。
\sigma_{j}=\sqrt{\sum_{i,k}(w'_{ijk})^2}
正規化(norm)の処理では上述のように標準偏差で割っているだけでしたので、畳み見込んだ出力に標準変数の逆数をかければいいことになりますので、畳み込んだ出力に標準偏差をかける操作は、重みwijkに標準偏差の逆数をかけたもので畳み込むことと等価です。従って正規化(norm)の操作は以下になります(図10④)。
w''_{ijk}=w'_{ijk}/\sqrt{\sum_{i,k}(w'_{ijk})^2+\epsilon}
以上の見直しにより、Style block全体が単一の畳み込み層に実装されています。
この正規化の改善により、図11のように生成された画像からdropletが削除されるようになります(論文の図3より引用)。

(ⅱ) 生成画像の特徴の一部が不自然になる事象を低減(論文4章:Progressive growing revisited)
Progressive growingは高解像度の画像生成は非常に成功したモデルですが、個々のGeneratorが独立しているので頻出する特徴を生成する傾向にあり、その結果として先述した顔が動いても歯が追従していかないという結果に繋がっています。そのためStyleGAN2ではStyleGANのネットワークの再構築しProgressive growingに代わる新たなアーキテクチャを探すにより高解像度の画像生成ができるようにしています。具体的には図12の3つのモデルを検証しています。
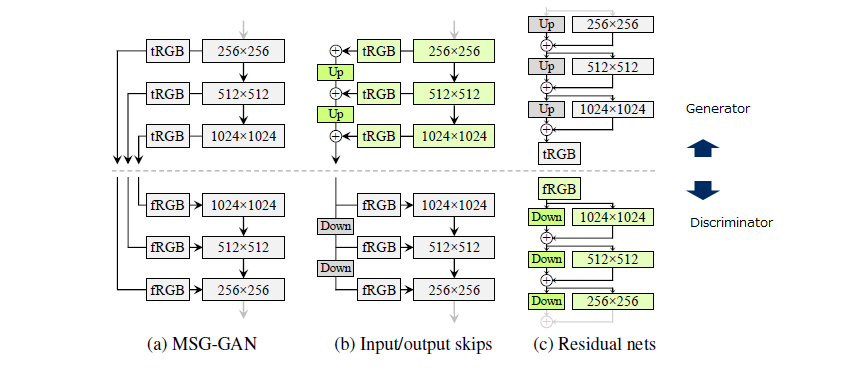
図12(a)はMSG-GANです。複数のスキップ接続を使用してGeneratorとDiscriminatorの同一の解像度を接続しています。図12(b)は各解像度のRGB出力をアップサンプリング(Discriminatorではその逆)して合計して設計を簡略化しています。図12(c)では、さらにresidual connectionを使うように変更しています。
これらを全部組み合わせて評価した結果、Generatorでは図12(b)をDiscriminatorでは図12(c)を採用しています(緑色で表示)。
このアーキテクチャを採用して生成された画像を図13に示します。顔の向きに合わせて歯や目も自然に合わせて動いているのがわかります。
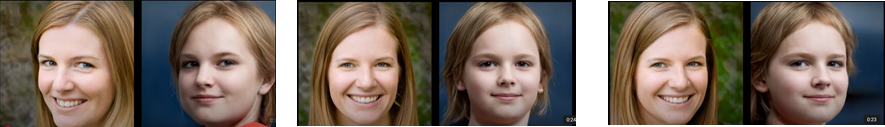
(ⅲ) 潜在空間をなめらかにすることによる画像品質向上(論文3章:Image quality and generator smoothness)
潜在空間の知覚的ななめらかさを表すPerceptual Path Length(PPL)と生成される画像の品質に相関があることがわかってきたのでモデルの正則化に組み込んでいます。
正則化項は以下になり、潜在変数の摂動に対するGeneratorの出力値の変換をなるべく小さくするように仕向けています。
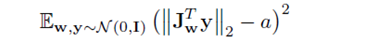
ここでJwはヤコビ行列(Jacobian matrix)で、Jw = ∂g(w) / ∂w、yは正規分布のピクセル強度を持つランダム画像、aは定数ですが、||$\mathbf J^T_{w}y $||2 の移動平均によって動的に変化させながら学習を行い、それによって最適な値が学習中に設定されるようになっています。
また、正則化項の更新は計算コストとメモリ使用量を削減から更新頻度を下げる(16ミニバッチごとに1回の実行でも影響がないことが分かっているため)戦略をとっています(Lazy regularization)。
4 おわりに
StyleGAN2はStyleGANでの問題を修正し、生成画像の品質をさらに向上させ、学習時のパフォーマンスの向上も実現しました(とはいえNVIDIA DGX-1(8GPU)でFFHQの学習データで9日かかるみたいです)。
実際に生成される画像も本物と区別がつかないくらいすばらしいものですので、学習済みモデルからの画像生成をコードを修正してPC(CPU)でも実行できるようにしていきたいと思います。
【参考文献、サイト】
・論文
・Analyzing and Improving the Image Quality of StyleGAN
・情報工学_機械学習_生成モデル.md
・GANの基礎からStyleGAN2まで
© 2021 NPO法人AI開発推進協会