ここ数年、AIは目覚ましい進化を遂げています。テキストを生成する大規模言語モデル(LLM)から、推論ツールのオーケストレーションや業務完遂までを自律的に担うAIエージェントへと進化が加速しています。
エンタープライズにおいて、この変化はビジネスモデルそのものを変革し得る大きな飛躍です。しかしその真価を引き出すには、「評価」の在り方も同時に進化させる必要があります。
本記事では、AIエージェントの位置づけ、従来のソフトウェアとの違い、評価が難しい理由、そして企業で活用する際に欠かせない評価フレームワークについて解説します。
生成AIからエージェントへ:次の飛躍
生成AIの登場によって、人間らしいテキスト、画像、コードの生成が可能になりました。メール文面を数秒で下書きしたり、スライドの骨子を生成したり、コード断片を自動で提示できるようになったのは画期的でした。
しかし、企業利用の観点では限界も見えてきています。生成AIは「答え」を作り出すことはできますが、それを実際の業務フローに組み込み、成果にまでつなげるには人の手が必要です。生成されたメール文をCRMに登録し、顧客対応を完結させるには依然として担当者の作業が欠かせません。
ここで登場するのがAIエージェントです。エージェントは単なる提案に留まらず、自律的に次のような行動を取ります。
-
タスクの分解と推論:複数ステップに分けて課題を整理し、解決プロセスを設計する
-
意思決定:文脈に応じて利用するツールやAPI、データソースを選択する
-
実行:会議を自動で予約、データベースを更新、問い合わせチケットを振り分けるなど、エンタープライズシステム上でアクションを完遂する
つまりエージェントは、生産性を高めるアシスタントから、業務を推進する「デジタル同僚」へと進化した存在です。 ただしその分、評価と管理の難しさも増しています。
アプリケーションとエージェント:共通点と主要な違い
エージェントは単なるソフトウェアの一種に見えるかもしれません。
しかし従来のソフトウェアアプリケーションとエージェントには、共通する点があります。
- ワークフローの中でエンドユーザーにサービスを提供すること
- 稼働率、スケーラビリティー、コンプライアンスといったエンタープライズ基準を満たす必要があること
- 慎重な設計とガバナンスが求められること
エージェントが異なる点
- 推論と適応性:エージェントは状況に応じて計画をその場で立て直し、複数のルートで成功に至る可能性があります
- 非決定性:同じ入力でも、確率的推論によって出力が異なる場合があります
この柔軟性は強力ですが、評価を格段に難しくする要因にもなります。コードのように単純な成否で判定できず、出力の質やリスク、業務上の影響を多面的に評価する必要があります。
従来の評価手法が通用しない理由
この柔軟性こそがエージェントを強力なものにしていますが、同時にその評価を全く新しい挑戦にしています。エージェントはコードというよりは(予測不能な)人間のように振る舞うため、私たちは評価の方法を変える必要があります。
成功と失敗の範囲は、単なるタスクの完了を超えます。失敗には、エージェントがハルシネーション(幻覚)を起こす、性能が劣化する、不要なステップを実行する、PII(個人を特定できる情報)を漏洩するなど、多様な形があります。
これは、従来のソフトウェアで有効だった二元的な合否テストやコードレビューが、エージェントには機能しないことを意味します。なぜなら、エージェントの失敗の仕方は一つではないからです。その代わりに企業は、エージェントが現実世界の制約の中で、いかにうまく推論し、適応し、一貫した価値を提供できるかを評価しなければなりません。
最悪の場合、エージェントに特化した評価を怠ることは、ビジネス上の失敗(誤ったアウトプット、劣悪なUX)、コンプライアンス上の失敗(PII漏洩、バイアス)、運用上の失敗(レイテンシー、コスト超過)のリスクを冒すことになります。これらは稀なケースではなく、企業全体に及ぶシステミックなリスクなのです。
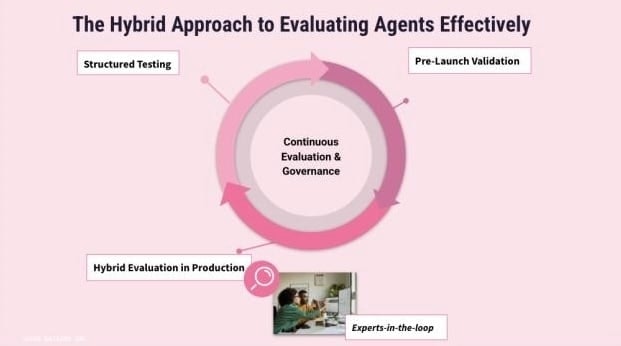
エージェント評価の5つの柱
エンタープライズでAIエージェントを安全かつ効果的にスケールさせるためには、次の5つの観点で評価することが不可欠です。
1. タスクの成功と出力品質
エージェントの出力は常に正確で信頼でき、ビジネスの期待に沿っている必要があります。エージェントが本来の役割を果たせなければ、他の要素は意味を持ちません。
測定すべき内容
- 重要な業務ワークフローにおけるタスク完了率
- SME(専門家)の判断に基づく出力の正確性、精度、コンプライアンス
- エラー率、再試行回数、エスカレーション頻度
測定方法
- 優先度の高いユースケースについてSMEと共にベンチマークとなる基準を定義します
- リスクの高いタスクに対しては人間がレビューする仕組みを導入します
- 長期的なパフォーマンスを追跡し、継続的な改善を確認します
2. ビジネス価値とユーザー満足度
エージェントは「正しい」だけでなく、エンドユーザーの業務を効率化することが求められます。ビジネス価値とユーザー満足度を評価することで、スムーズで直感的な利用者の体験プロセスを実現し、導入とROIを確保できます。
測定すべき内容
- 基準となる従来プロセスと比較したワークフローごとの時間削減量
- エンドユーザーの利用率およびリピート使用率
- エージェントとのやり取りに特化したNPS(ネットプロモータースコア)や満足度調査
測定方法
- エージェントを活用したワークフローと従来のワークフローを比較するA/Bテストを行います
- 利用者の体験プロセスを計測し、摩擦点を特定します
- 定性的なフィードバックを収集し、エージェント改善の指針とします
3. 推論力とツール活用の有効性
エージェントは手順を組み合わせ、適切なツールを呼び出し、無駄に回り道をせずに業務を完了させる必要があります。推論力とツール活用の有効性を評価することで、入力から出力までのプロセスが効率的で透明性があり、検証可能であることを保証します。
測定すべき内容
- 適切にツールを選択し順序立てて使用する能力
- タスクごとの不要または冗長なステップ数
- 中断された推論やループ状態に陥る頻度
測定方法
- 推論の経路やツールの呼び出しをログで追跡します
- 「エージェントトレイル」を可視化し、非効率性を特定します
- シナリオベースのテストを用いて、エッジケースにおける推論を検証します
4. 信頼性、監督、コンプライアンス
エンタープライズにおいては信頼がすべてです。エージェントが安全で倫理的かつ規制に準拠して行動できるようにするためには、透明性、監査可能性、そして安全性ガードが必要です。
測定すべき内容
- ポリシー違反や偏見、または有害な出力の発生件数
- 意思決定やツール使用の監査可能性
- 安全性ガード(レッドチーミング、ガードレール、モデレーション)の有効性
測定方法
- 定期的に自動化された安全性テストを実施します
- コンプライアンスチームのために完全な監査ログを保持します
- リスクの閾値が超えた場合にSMEによるレビューへエスカレーションするワークフローを統合します
5. スケールと運用パフォーマンス
優れたデモも、本番環境で機能しなければ意味がありません。スケールにおける運用パフォーマンスを評価することで、実際のワークロード下でもエンタープライズレベルの要件を満たすことを保証します。
測定すべき内容
- 負荷下でのレイテンシーと応答時間
- 稼働時間とエラー率を、定義されたSLO(サービスレベル目標)と比較した値
- 時間の経過に伴う変動を含めた1インタラクション当たりのコスト
測定方法
- 異常を検知するアラート機能を備えた継続的モニタリングダッシュボードを活用します
- 予測されるピーク利用時にストレステストを実施します
- ユーザー、チーム、ワークフローレベルでコストを追跡し、予期せぬコスト増加を早期に把握します
エンタープライズへの導入に向けた評価フレームワーク
エージェント評価は単なる現状測定ではなく、継続的な信頼構築と改善のサイクルが求められます。
- 反復的評価:デプロイ、モニタリング、改善のサイクルを前提にする
- 文脈に基づくベンチマーク:汎用AIベンチマークではなく、自社業務プロセスに即した評価指標を設計する
- クロスファンクショナルなガバナンス:IT、業務部門、コンプライアンスの連携でバランスを取る
- 人と専門家の関与:人による監督が出力の安全性と妥当性を担保し、専門家がビジネスリスクを理解して成功基準を定義することで、最終的にエージェントが信頼できる存在となる
今取り組むべき理由
AIエージェント導入を試行する企業は急速に増えています。その中で、早期に評価フレームワークを確立した企業は競争優位を築くことができます。動くかどうかではなく、確実に、安全に、スケールして動くかどうかを判断できる企業こそが、ビジネス成果に直結する真のAI活用を実現します。
Dataikuでは、エージェントをエンタープライズAIの次なるフロンティアと位置づけています。厳格な評価と堅牢なガバナンス(英語)を組み合わせることで、PoCから本番導入へと自信を持って進めることが可能になります。
Webセミナーを見る
本セッションでは、AIエージェントが抱える課題を深掘りし、エージェント型AIのニーズに応じて評価手法をどのように進化させるべきかを解説します。また、5つのカテゴリにわたるリスク低減のための戦略についても学ぶことができます。