1. はじめに
こんにちは、DataRobotの長野です。本ブログ(DataRobot AIエージェントテンプレート入門:CrewAIを用いたAIエージェントの構築 後編)では、AIエージェントテンプレートの具体的なユースケースを用いた実装を確認しながらより複雑なAIエージェントを構築していきます。
なお、「DataRobot AIエージェントテンプレート入門:CrewAIを用いたAIエージェントの構築 前編」ではAIエージェントテンプレートの中身を読み解くことでAIエージェント構築の基本についてまとめていますので、ぜひ本ブログを読む前にご一読ください。
また、本ブログの前段となるテンプレートの全体像を紹介している「DataRobot AIエージェントテンプレート入門:セットアップからデプロイまで」も、ご覧いただけるとより理解度が高まると思います。
2. テンプレートの編集:テーマアイデアシートのレビューエージェントの構築
それでは、これまで学んだことを活かし、実際にテーマシートを編集・レビューするエージェントを構築します。せっかくなので、CrewAIのもう一つの先ほどの逐次型(sequential)とは異なる階層型 (hierarchical) プロセスの活用事例をご紹介します。
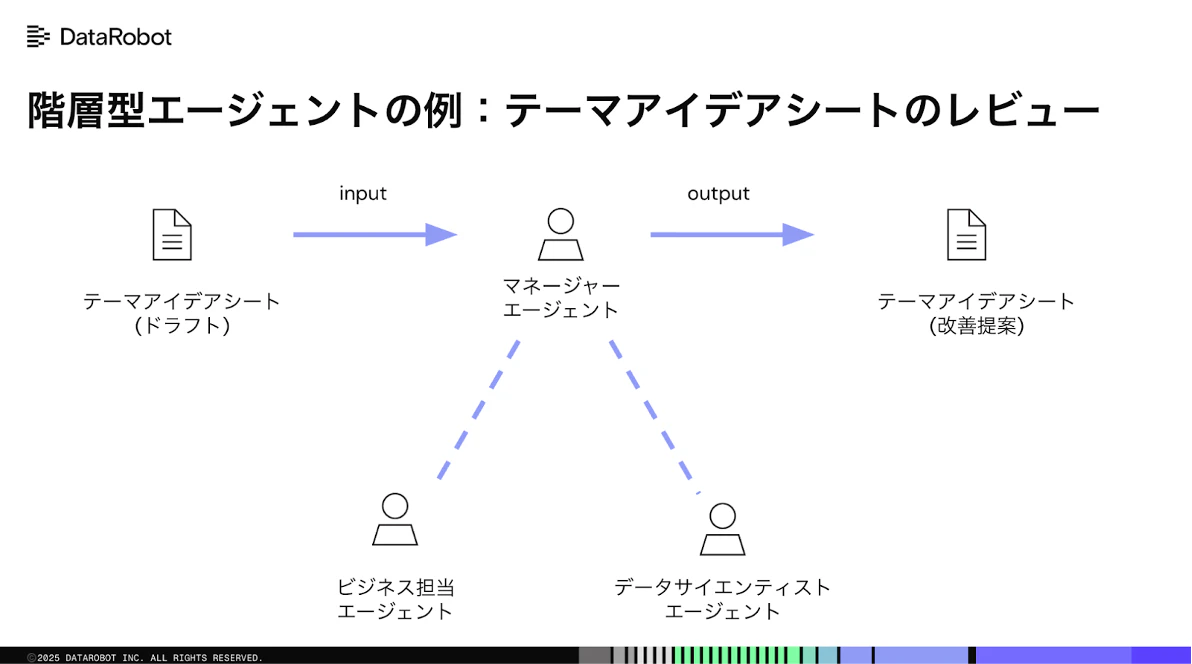
DataRobotでは、AIプロジェクトの初期段階で「テーマアイデアシート」というフレームワークを用い、AIプロジェクトの質を評価します。このシートのブラッシュアップは、通常、専門的なノウハウを持つ人材が行いますが、今回はそのプロセスをAIエージェントに自動化させてみましょう。このようなタスクでは、上図のようにマネージャー役が全体を監督し、専門家(ビジネス担当、データサイエンティスト)にヒアリングを繰り返す、という動きが求められます。
これを単純な逐次型で実装しようとすると、「マネージャー → ビジネス担当 → マネージャー → データサイエンティスト…」といった、冗長で複雑なフローを組まなければなりません。
そこで登場するのが階層型エージェントです。マネージャーエージェントが自律的に判断し、必要な専門家にタスクを委任することで、より柔軟で効率的なワークフローが実現できます。こうしてみると階層型の方が良さそうですが、柔軟性とコントロールのしやすさはトレードオフです。まずはシンプルな逐次型で試し、より複雑な意思決定が必要な場合に階層型へ移行するのがお勧めの進め方です。
2.1 階層型エージェントの実装
それでは、階層型エージェントをagent.pyに実装しましょう。アーキテクチャを大きく変更するため、コードの大幅な書き換えが必要に思えるかもしれません。しかし、驚くほど簡単です。前回のsequential(逐次実行)モデルからの変更点は、実質的に以下の2点だけです。
- Crewを定義する際のprocessパラメータを、sequentialからhierarchicalへ変更。
- 各エージェントの個別タスクを、マネージャーが采配を振る1つの包括的なタスクへ統合。
たったこれだけの変更で、AIたちの働き方は直線的な逐次型から、動的な階層型に変わります。
@property
def agent_pm(self) -> Agent:
"""マネージャーエージェント:プロジェクトマネージャー"""
return Agent(
role="プロジェクトマネージャー(PM)",
goal="ビジネス価値と技術的実現性の両方を満たす、具体的なアクションに繋がるテーマ定義シートを完成させる",
backstory="あなたはビジネスと技術の両方に精通したPMです。両サイドの意見をまとめ、プロジェクトを成功に導く責任があります。",
allow_delegation=True,
verbose=self.verbose,
llm=self.llm,
)
@property
def agent_business(self) -> Agent:
"""部下エージェント1:ビジネスサイド"""
return Agent(
role="ビジネスサイドの担当者",
goal="プロジェクトがビジネス価値に直結しているか、ROIやKPIの観点から厳しく評価する",
backstory="あなたは事業の収益責任を負う立場にあります。技術的な詳細よりも、そのプロジェクトが「儲かるのか」「顧客のためになるのか」を最重要視します。",
allow_delegation=False,
verbose=self.verbose,
llm=self.llm,
)
@property
def agent_ds(self) -> Agent:
"""部下エージェント2:データサイエンティスト"""
return Agent(
role="データサイエンティスト",
goal="プロジェクトがデータと技術の観点から実現可能か、リスクや工数を見積もる",
backstory="あなたはデータ分析とモデル構築の専門家です。データの有無や品質、分析手法の妥当性など、技術的な実現性を冷静に判断します。",
allow_delegation=False,
verbose=self.verbose,
llm=self.llm,
)
@property
def task_review(self) -> Task:
"""レビュータスクの定義"""
theme_sheet_draft = """
プロジェクトテーマ:カタログ送付の優先順位付け
■ 課題の明確化
解決したい課題:
1. カタログ送付はお客様へのロイヤリティを高める重要なプログラムだが、労力がかかり効率的に行いたい。
2. カタログ送付を受けた方の購入率を向上させ、現在の手法で作るリストの量より多くのカタログを送付できるニーズが出できている。
3. カタログ送付リスト作成にかかる工数を削減する。
■ データ準備とモデリング
予測対象:
- カタログを受け取った顧客が1ヶ月以内に購入するかどうか。
使用するデータセット:
- POSデータ:最新の各カテゴリでのRFM、過去1年間の購入回数など。
- Webログ:最新ページ訪問からの期間と頻度、閲覧履歴など。
- 顧客マスタ:性別、年齢、都道府県、顧客期間。
予測の対象グループ/サンプル数:
- カタログ送付者。サンプル数:過去5年間のカタログ送付者、延べ1000万人。
モデルがビジネス適用される条件:
1. 2019年モデルのデータでモデルを作り、既存手法との精度を比較。機械学習モデルの精度が上回り、購入率が既存手法より0.5%高いことが第1条件。
2. 1の条件を満たした後にビジネス実験(A/Bテスト)を実施。新しい予測モデルによる購入率が旧予測モデルより1%高いことが第2条件。
■ ビジネス適用
業務における実運用フロー:
1. 送付顧客をマーケティング予算によって決定。
2. 予測モデルに基づき、顧客の購入確率が高い順にカタログを送付する。
モデルのデプロイ&実運用化:
- 予測タイプ:3ヶ月に1度、バッチ予測で約500万人(既存顧客数)に対して購入確率を計算する。
- システム連携:最終適用段階ではシーズンごとのモデル生成・予測を自動化し、基幹システム(Oracle)に書き込む。
ビジネスインパクト:
- 追加利益:3000万円/カタログ送付
- 削減コスト:25万円/カタログ送付
- 計算可能なインパクト:合計12,100万円
"""
return Task(
description=f"""
以下のテーマ定義シートのドラフトについて、チームでレビューを実施せよ。
ドラフト内容:
---
{theme_sheet_draft}
---
レビュー手順:
1. 「ビジネスサイド」の担当者に、このシートをビジネス観点(課題、価値、KPI、活用方法、インパクトの妥当性)からレビューさせ、フィードバックを収集せよ。
2. 「データサイエンティスト」に、このシートを技術観点(データ、実現性、モデルの条件、工数、リスク)からレビューさせ、フィードバックを収集せよ。
3. 両者のフィードバックを統合し、元のドラフトが抱える「論点」「リスク」「未定義な項目」をすべて洗い出せ。
4. 最終的に、洗い出した項目を追記した「改訂版テーマ定義シート」を生成せよ。
""",
expected_output="""
ビジネスサイドとデータサイエンスサイド、両方の観点からのフィードバックと、
それによって明らかになったリスクや論点を具体的に示してください。
""",
agent=self.agent_pm,
)
def crew(self) -> Crew:
"""Crewの組み立て"""
return Crew(
agents=[self.agent_pm, self.agent_business, self.agent_ds],
tasks=[self.task_review],
process=Process.hierarchical, #階層型エージェントに変更部分
manager_llm=self.llm,
verbose=self.verbose,
)
それでは、作成したAIエージェントをtaskコマンドで実行してみましょう。以下のコマンドをターミナルで実行してください。
task agent:cli -- execute --user_prompt '実行して' > output.txt
このコマンドには、入門ブログで解説した基本形とは異なる、2つの重要なポイントがあります。
1. user_promptの役割
今回は--user_promptに'実行して'というシンプルなテキストを渡しています。これは、レビュー対象の「テーマ定義シート」がエージェントのコード内に直接書き込まれている(ハードコードされている)プロトタイプだからです。本格的な運用では、この部分にテーマ定義シートの全文を直接渡したり、PDFなどのファイルパスを指定する設計にするのがより実践的です。
2. > output.txtによるログの保存
コマンドの末尾にある> output.txtは、リダイレクトと呼ばれる操作です。これを付けると、エージェントの思考過程を含む全ての実行結果が、ターミナル画面ではなくoutput.txtというファイルに保存されます。後から動作内容を分析したい場合に非常に便利な機能です。
2.2 階層型エージェントの実行結果の確認
それでは、output.txtに書き出された階層型エージェントの処理結果を確認してみましょう。まずは、AIエージェントが最終的に生成した「改訂版テーマアイデアシート」を確認します。全文は長いため、主要な部分を抜粋したスクリーンショットを以下に示します。
生成されたアウトプットは、ビジネスと技術、両サイドの視点が反映された良いベースラインと言えるでしょう。一方で、「もう少し踏み込んだ議論」を期待した部分もあるかもしれません。これはAIエージェント開発における重要なポイントです。多くの場合、最初から完璧な結果は出ません。このベースラインを基に、以下のような改善を加えていくのが定石です。
プロンプトの改善: 各エージェントのbackstoryやgoal、あるいはTaskのexpected_outputをより具体的にし、「もっと鋭い指摘をするように」と促すことで、議論の質を高めます。
ツールの活用: 今回の議論はあくまで「机上ベース」でした。次の一手として、データサイエンティストエージェントにDataRobotを操作するツールを与え、実際のデータセットでモデリングさせた結果を議論に反映させれば、アウトプットの質が飛躍的に向上する可能性はあります(ツールに関しては別の記事で詳しく解説します。)。
2.3 階層型エージェントの内部動作の確認
では、この最終成果物が生成されるまでに、エージェントチームの内部ではどのような「議論」が行われていたのでしょうか?output.txtの全文を追うのも一つの手ですが、非常に長文です。そこで、ログの主要なやり取りをAIに要約させた結果を以下に示します。私が試したケースでは6ステップを踏んで最終アウトプットを出していました。シンプルな実装にも関わらず複雑な処理ができていますね。
[ ユーザー ]
|
| (1. レビュー全体を指示)
v
[ プロジェクトマネージャー(PM) ]
|
| (2. ビジネス観点でのレビューを依頼)
v
[ ビジネスサイド]
|
| (3. ビジネス観点のレビュー結果を報告)
v
[ プロジェクトマネージャー(PM) ]
|
| (4. 技術観点でのレビューを依頼)
v
[ データサイエンティスト ]
|
| (5. 技術観点のレビュー結果を報告)
v
[ プロジェクトマネージャー(PM) ]
|
| (6. 両者のフィードバックを統合し、最終版を作成)
v
[ 最終成果物:改訂版テーマ定義シート ]
|
| (成果物を提示)
v
[ ユーザー ]
3. DataRobot AIエージェントテンプレート入門:CrewAIを用いたAIエージェントの構築(後編)まとめ
本ブログでは、DataRobotのAIエージェントテンプレートを用い、CrewAIによるAIエージェントの構築のプロセスを解説しました。
「AIエージェント」という言葉は、非常に広い意味で使われています。一見すると複雑で掴みどころがないように感じるかもしれませんが、その本質の多くは、本ブログで紹介した基本的な要素の組み合わせで表現が可能です。このフレームワークを一度でも体験すれば、世の中の様々なAIエージェントがどのような考え方で構築されているのか、その全体像が見えてくるはずです。ぜひご自身の手で、まずは簡単なAIエージェントの構築から始めてみていただければと思います。