はじめに
DataRobot Japan データサイエンティストの大久保です。金融業界を担当しています。
前回の記事:「DataRobotのOSS『syftr』を動かして最適なRAGパイプラインを探してみた」ではsyftr (GitHub)のチュートリアルを紹介し、テスト用のデータセットに対して最適なRAGを構築できることを確認しました。
前回は、RAGパイプラインの自動最適化ツール「syftr」を初めて動かすまでの手順を解説しました。syftrは、埋め込みモデルやLLMの選択、チャンクサイズの調整など、RAG構築時の膨大なパラメータ調整を自動化し、精度とコストのバランスが取れた最適な構成を見つけ出すフレームワークです。
記事では、環境構築からツールの実行、結果の可視化まで一通りの流れを紹介しました。具体的には、パッケージ管理ツールuvを使った環境セットアップ、Azure OpenAI APIの設定、そしてsyftr checkやsyftr runといった基本コマンドの使い方を説明しました。最後に、DataRobotの社内ドキュメント(DRDocs)を使ったサンプル実行で、パレートフロンティアを可視化し、精度60%を達成する最適なRAG構成を発見できることを確認しました。
今回の記事の位置づけ
前回はsyftrに同梱されているサンプルデータでの動作確認にとどまりましたが、実際の業務では自社のドキュメントや独自のQ&Aデータを使ってRAGを最適化したいというニーズがあります。そこで今回の実践編では、カスタムデータの準備方法から、実験計画書の詳細な設定、そして最適化結果を実務でどう活用するかまで、より実践的な内容を扱います。
これらの内容を通じて、syftrを使った本格的なRAG最適化のワークフローを習得していただけます。
この記事でやること
- 最新版のsyftrを反映した環境を構築する
- syftrで評価するためのカスタムデータを用意する
- 最適化の探索方法や、RAGパイプラインのパラメータ空間を定義する
- 最適化を実行し、結果を可視化・データ出力する
1. 実行環境の構築
環境構築の大まかな流れは前回の記事を参照してください。本節では前回との差異を解説します。
1.1. 最新リポジトリの反映
当記事で紹介する機能は前回記事の発表後に実装されたものとなります。mainリポジトリが更新されているので、最新のリポジトリをプル、あるいはクローンして下さい。
1.2. config.yamlの編集
前回記事の発表後、syftrでは大規模なリファクタリングが実施されました。config.yamlにおけるLLMの設定方法が変更されましたので、以下を参考に修正してください。
前回の設定では、generative_modelsの直下のレイヤーでazure_gpt_4o_miniと指定していたものが、gpt-4o-miniと簡素化されたことが分かります。
# config.yaml
# ...(省略)...
generative_models:
# azure_openai Provider Example
# See docs/llm-providers.md for full documentation of all provider configurations
gpt-4o-mini:
provider: azure_openai
deployment_name: "gpt-4o-mini"
model_name: "gpt-4o-mini"
api_version: "2024-10-21"
additional_kwargs:
user: syftr
cost:
type: tokens
input: 0.15
output: 0.60

2. カスタムデータの準備
2.1. カスタムデータの生成
RAGフローの性能を評価するためのQ&Aファイル(custom_qa_data.csv)と、RAGが参照する文書ファイル群(grounding_docs)を用意します。本記事ではこれらのデモデータをChatGPTで生成しますが、要件を満たしていればお手元のファイルをそのまま利用できます。
2.1.1. Q&Aの生成
Q&Aファイルは、id, question, answerからなる3列のcsvファイルとして用意する必要があります。

今回はGPTを使って以下のプロンプトでcustom_qa_data.csvを生成しました。
あなたは機械学習教育用のQ&Aデータセットを作成するアシスタントです。
RAGの性能評価に使うため、次の条件を満たす **custom_qa_data.csv** を生成してください。
### 出力フォーマット
- CSV形式(UTF-8, カンマ区切り)
- ヘッダー行: id,question,answer
- 各行は1問1答のペア
### データセット条件
- 問題数は30問
- questionとanswerはすべて全て日本語の文章
- 難易度は以下をバランスよく混ぜる:
1. **初級**(定義や基礎概念を問うもの: 例「過学習とは何ですか?」)の問題を20問
2. **中級**(応用的な推論が必要: 例「精度と再現率のどちらを優先すべきか、医療診断タスクではどう考えますか?」)の問題を10問
- 問題は機械学習全般に関連する内容に限定(深層学習、教師あり/なし学習、特徴量、評価指標、正則化、バイアス・バリアンスなど)
- 回答(answer)は簡潔かつ明確で、数行以内に収める
### 出力例(冒頭数行)
id,question,answer
1,過学習とは何ですか?,学習データには高精度だが未知データで性能が落ちる状態のことです。原因はモデルの複雑さやデータ不足であり,対策は正則化やデータ拡張,早期終了などです。
2,汎化とは何ですか?,訓練で得た規則が未知データにも通用する性質です。汎化性能が高いほど実運用で安定した予測ができます。
3,教師あり学習と教師なし学習の違いは?,教師あり学習は正解ラベル付きデータで予測関数を学びます。教師なし学習はラベルなしデータから構造やクラスタを見つけます。
---
必ず30問すべてをCSV形式で出力してください。
2.1.2. 文書ファイルの生成
RAGを構築するためにはVDBに投入する文書ファイルが必要となります。syftrは内部でLlamaIndexのSimpleDirectoryReaderを使用しているので、docx, pdf, txt, md, html, csvなどの様々な形式の文書ファイルからRAGを構築できます。
今回はGPTを使って以下のプロンプトでgrounding_docsを生成しました。custom_qa_data.csvを生成したスレッドをそのまま継続して利用しています。
あなたは機械学習の学習教材作成アシスタントです。
RAGの評価のために、次の条件を満たす **Markdown形式の文書ファイル群** を生成してください。
### 出力条件
- Markdownファイルは複数に分けてもよい
- 各ファイルは「# 見出し」から始まるまとまった解説文にすること
- ファイルはUTF-8で保存可能なプレーンテキストとして出力する
- 説明文は日本語の文章にすること
- 専門用語については英語のままでも良い
### 内容ルール
1. **初級レベルのQAに対応する内容**
- 回答そのものを明示的に記載する
- 例:「過学習とは、モデルが訓練データに過度に適応し、未知データにうまく一般化できない状態を指す。」
2. **中級レベルのQAに対応する内容**
- 回答を直接書かず、推論に必要な材料だけ記載する
- 例:「医療診断における評価指標の選択では、偽陰性と偽陽性のリスクを比較することが重要である。」
- この情報を組み合わせて初めて正解に到達できるようにする
3. **カバレッジ**
- 先に用意した `custom_qa_data.csv` の30問すべてをカバーする内容にする
- 同じトピックを1つのMarkdownファイルにまとめてよい
- 例:`basics.md`, `evaluation.md`, `regularization.md`, `deep_learning.md` など
### 出力例(冒頭のイメージ)
# 過学習と汎化
過学習とは、モデルが訓練データに過度に適応し、未知データにうまく一般化できない状態を指す。
汎化とは、学習した規則が未知のデータにもうまく適用できる性質を表す。
# 医療診断における指標選択
医療診断における評価指標の選択では、偽陰性と偽陽性のリスクを比較することが重要である。
偽陰性は病気を見逃すリスクを伴い、偽陽性は誤って健康な人を陽性と判定するリスクを伴う。
最終的に以下のようなディレクトリ構造でデータを用意しました。
custom_data/
├── custom_qa_data.csv
└── grounding_docs/
├── basics.md
├── deep_learning.md
├── evaluation.md
└── intermediate.md
2.2. カスタムデータの参照範囲を設定
Q&Aファイルの中で使用する行の範囲を明示的に指定する必要があります。今回使用するcustom_qa_data.csvは30問のQ&Aからなるので、この30行を使うように設定します。
syftrは機械学習の実験作法に倣い、Q&Aデータをsample, training, test, holdoutの4つのパーティションに分け、利用目的に沿って特定のパーティション内のQ&Aのみを参照する仕様になっています。
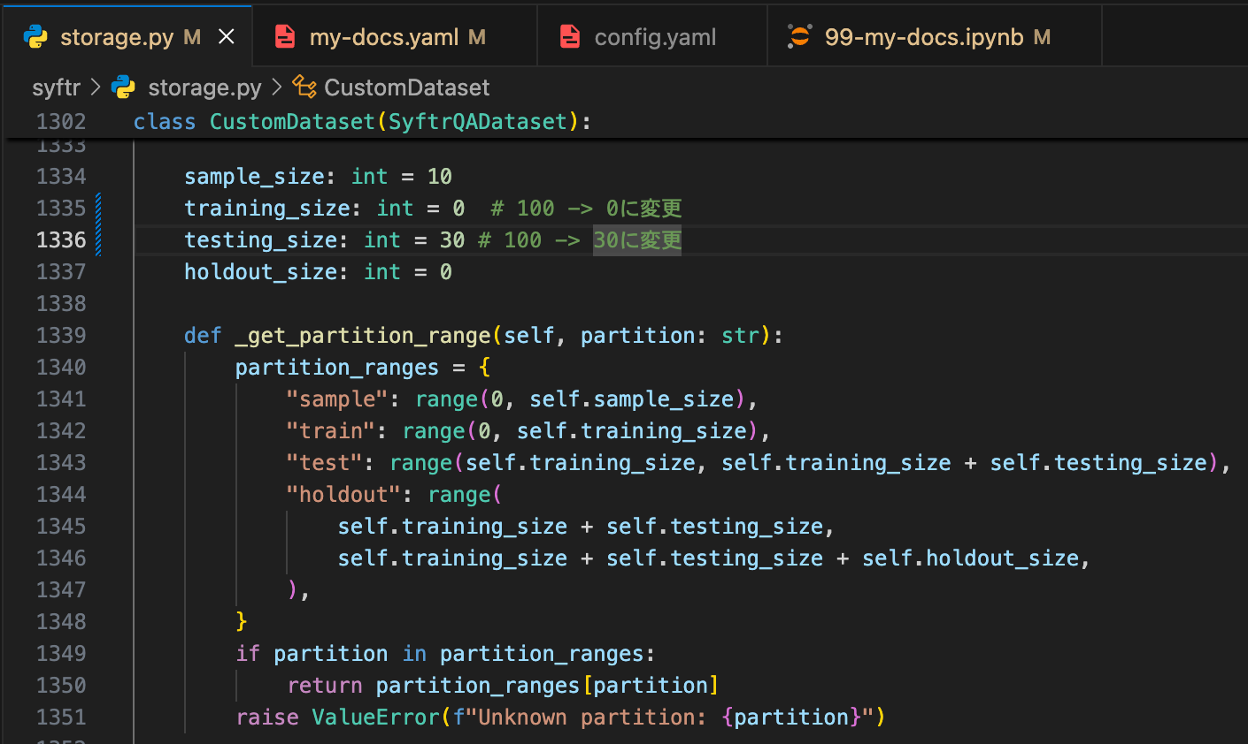
カスタムデータを検証する目的の場合は、30問すべてをtestパーティションに割り当てて下さい。以下の画像を参考に、syftr/storage.py内のCustomDatasetクラスのパーティションサイズパラメータを編集して下さい。特にtraining_sizeを0に変更することを忘れないように注意してください。
3. 実験計画書の編集
カスタムデータ用の実験計画書ファイル(my-docs.yaml)を開き、最適化に必要な設定を編集します。
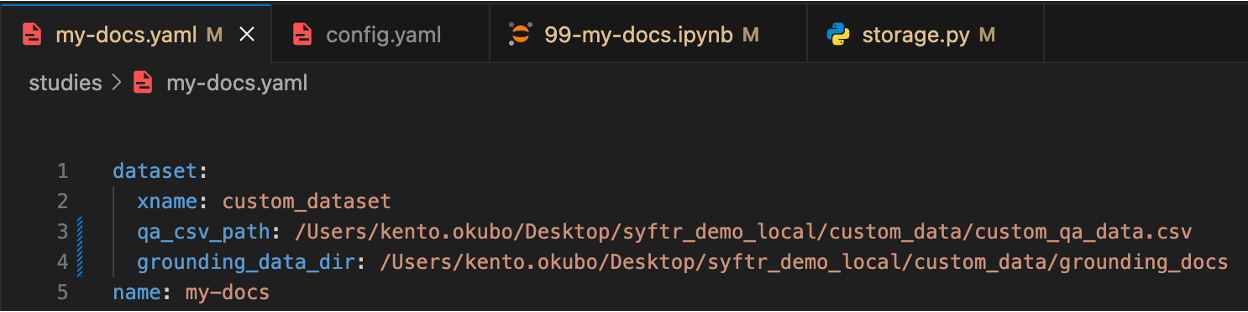
3.1. カスタムデータパス
今回用意したカスタムデータの絶対パスを指定する必要があります。以下の画像を参考に設定してください。
3.2. 計算パラメータ
optimizationブロックではRAGパイプラインを最適化するための「探索アルゴリズムの挙動・計算資源の使い方・試行回数のルール」などを設定できます。設定可能なパラメータの定義についてはOptimizationConfigクラスを参照して下さい。
計算効率の観点から、以下の表中のパラメータを調整する機会が多いと思います。my-docs.yamlではmax_concurrent_trialsのデフォルト値が1と低いので、計算効率を上げるために5や10などに設定するとよいでしょう。
| パラメータ | 内容 | 効果 |
|---|---|---|
| cpus_per_trial | 1試行に割り当てるCPUコア数 | 大きいほど速いが並列度は低下 |
| max_concurrent_trials | 同時に走れる試行の数 | 大きいほど並列性が上がるがリソースを圧迫 |
| num_eval_samples | 1試行で評価に使うサンプル数 | 大きいほど精度安定するがコスト増 |
| num_trials | 探索する試行(パラメータ組み合わせ)の数 | 大きいほど探索網羅的になるが時間・コスト増 |
3.3. 探索範囲
search_spaceブロックでは探索するRAGのハイパーパラメータの種類やその範囲を設定できます。設定可能なパラメータの定義についてはSearchSpaceクラスを参照して下さい。また原論文のAppendix 1にも詳細な説明があります。
設定可能なパラメータは多岐に渡るので、主要なものや注意を要するもののみを以下の表でまとめます。
| パラメータ | 解説 |
|---|---|
| response_synthesizer_llm_config | 回答生成に使う各種LLMの設定。 |
| embedding_models | 探索する埋め込みモデルの一覧。 |
| rag_modes | RAG の実行モード。VDBを参照しない”no_rag”の場合や、ReActなどのプロンプト設計パターンなども定義域に含む。 |
| rag_retriever | 検索器用のパラメータ。top_kなどの連続値パラメータも含む。連続値パラメータは離散サンプリングのための範囲やステップ幅を指定する。 |
| *_enabled | 例:reranker_enabledの場合、falseとtrueの両方を設定することでrerankerを使用するRAGと使用しないRAGの両者を探索範囲に含めることができる。trueのRAGを探索する場合に、rerankerブロックの各種configが参照される。 |
| toy_mode | trueの場合はチャンクサイズやQ&Aの使用範囲を制限して軽量化する。本番検証ではfalseにすること。 |
4. 最適化の実行
以上で各種の準備が完了したので、実際に最適化計算を実行してみましょう。
4.1. ノートブックの実行
examples/99-my-docs.ipynbをそのまま上のセルから順に実行しましょう。
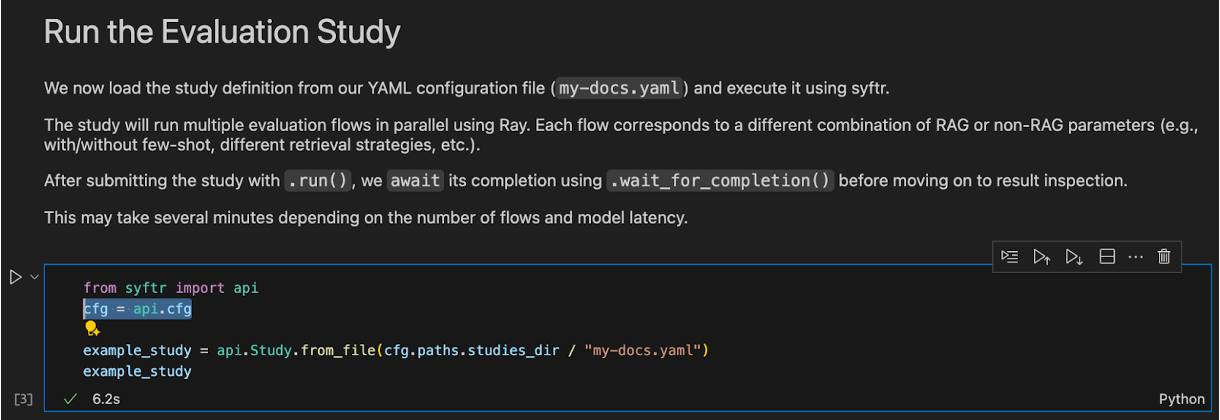
ただし本記事の執筆時点では1箇所だけモジュールインポートエラーが発生するセルがあります。上から3番目のコードセルに、cfgを明示的にインポートするコードを追加して下さい。
from syftr import api
cfg = api.cfg # <- この1行を追加する。
example_study = api.Study.from_file(cfg.paths.studies_dir / "my-docs.yaml")
example_study
計算時の挙動や、rayダッシュボードの確認方法については前回の記事を参照して下さい。
4.2. 主要なインサイト
計算が完了すると、ノートブックの末尾のPost-Evaluation Summaryセクションに分析結果が出力されます。筆者が実行した結果の一部を見てみましょう。
-
パレート最適なRAGのパラメータ取得
pareto_flowsによってパレート最適なRAGのパラメータを取得できます:

-
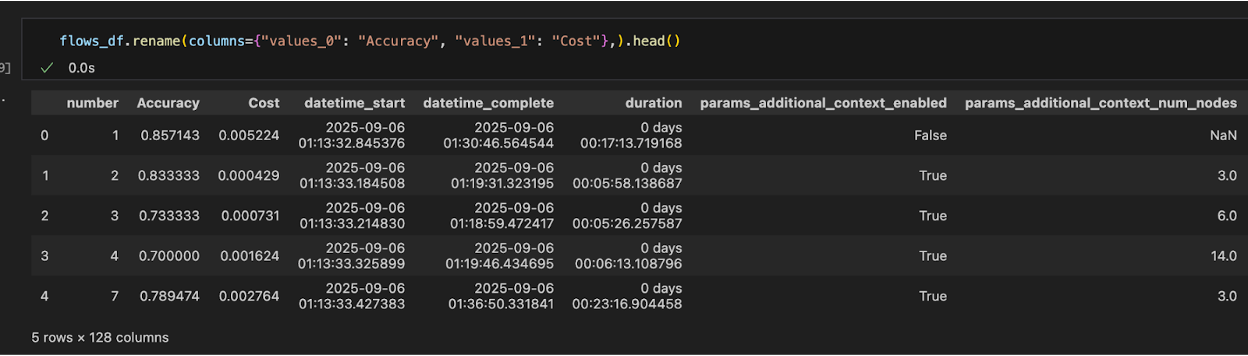
全結果のデータフレーム取得
実行に成功したすべてのRAGの計算結果やパラメータをデータフレームとして取得できます:
-
パレート図の表示
前回に引き続き、パレート図も表示することにより、精度とコストのトレードオフを可視化することができます。
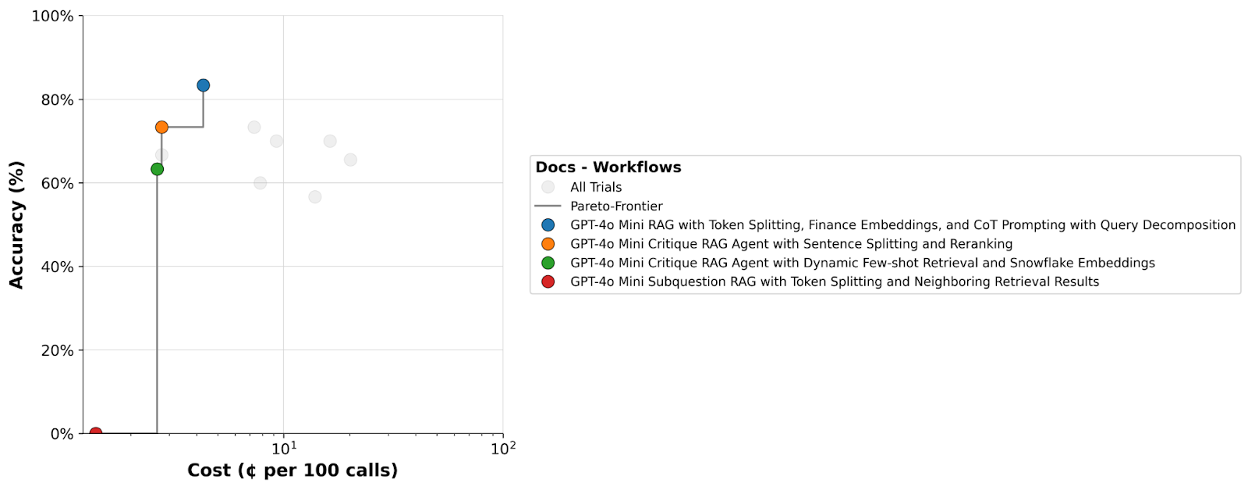
-
累積コストの確認
最適化の過程で発生した累積コストを確認できます:

-
パラメータ別の評価指標プロット
指定したパラメータに対する各種評価指標をプロットできます。今回はrag_modeを指定した場合の、各種RAGに対する結果をプロットしました:

-
複数パラメータの組み合わせ分析
複数のパラメータを組み合わせた場合でもグループ別に評価指標をプロットできます。今回はrag_modeとtemplate_nameを組み合わせてみました:
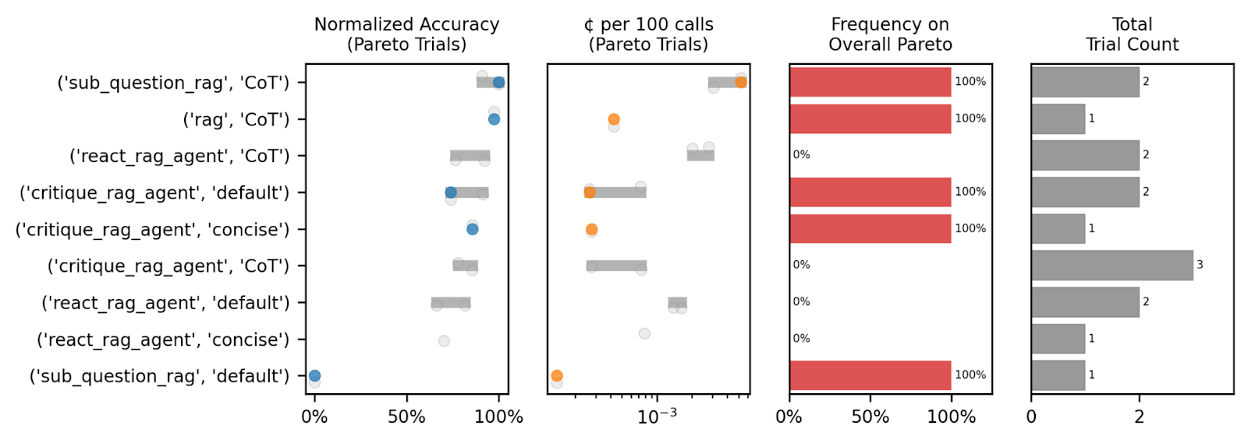
これらのインサイトを活用することで、最適化方針そのものも改善することができます:
まずは少ない試行回数で累積コストを確認し、より広範な探索を実行する際のコストを見積もる。
RAGの性能に直結する有力なパラメータや、パラメータ間の組み合わせを発見する。
以上の分析から探索範囲を有力な範囲に狭く深く絞るように計画書を編集し、再度最適化を実行する。
OSS「syftr」実践編:まとめ
本記事ではsyftrの実践編として、実際にユーザーが用意したデータセットに対してRAGを最適化する手順を紹介しました。柔軟な入力データ・実験計画に対応していることや、最適化後のインサイトからRAGフローの性能に対する理解が促進することを確認しました。
今回使用したLLMはgpt-4o-miniのみでした。RAGの最適化において複数のLLMプロバイダの比較は盲点になりがちです。syftrはエージェントワークフォースプラットフォームへの組み込みを予定しており、その際はゲートウェイ機能によって様々なLLMを探索することが可能となります。syftrとLLMゲートウェイの組み合わせによって探索範囲が拡張され、従来の最適化ソリューション以上に精度の向上やコストの削減が見込めることが期待されます。
参考資料
GitHubリポジトリ
原論文: syftr: Pareto-Optimal Generative Al
前回記事: DataRobotのOSS『syftr』を動かして最適なRAGパイプラインを探してみた