Railsで作っているwebAPIから、以下のようなエラーが頻発するようになりました。
ERROR -- : [77b6b755-3175-4319-b7c6-b7e5b8e00cca] could not obtain a connection from the pool within 5.000 seconds (waited 5.176 seconds); all pooled connections were in use
全てのプール接続が使用中でしたという趣旨のエラーで、どう言うことなのだろうかと悩みましたが、原因は、「同時にアクセスしてきたリクエストのうち、Rails側で許容しているプール数の上限に達してしまい、捌ききれないリクエストが発生していた」でした。
勿体無いことに、RDSのマックスコネクションは理論値で1000カウントまでいけたのに、Rails側ではデフォルトの設定値の5のままになっていて、同時アクセスを5までしか受け付けられないようになっていました。
アプリケーションサーバーの設定の効率化について考えて、アプリのパフォーマンスをよくしていくために考えたことをこれから展開していきます。
弊社の他のプロジェクトでも設定値が考慮されていないプロジェクトがあったので、他にもこの現象で悩んでいる人がいるかもしれないと思い、考察したことを記事にしました。
Railsでこれらを設定する場所
詳しい内容は後述しますが、結論として、worker数、スレッド数、pool数を設定する場所は以下です。
- pool数の設定
default: &default
adapter: mysql2
encoding: utf8mb4
charset: utf8mb4
collation: utf8mb4_general_ci
pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> ←ここ
- スレッド数
環境毎に設定ファイルを分けたりしている場合はファイルは以下の命名とは限らない。
# Puma can serve each request in a thread from an internal thread pool.
# The `threads` method setting takes two numbers: a minimum and maximum.
# Any libraries that use thread pools should be configured to match
# the maximum value specified for Puma. Default is set to 5 threads for minimum
# and maximum; this matches the default thread size of Active Record.
#
max_threads_count = ENV.fetch('RAILS_MAX_THREADS') { 5 } ←スレッド数
min_threads_count = ENV.fetch('RAILS_MIN_THREADS') { max_threads_count }
threads min_threads_count, max_threads_coun
# Specifies the number of `workers` to boot in clustered mode.
# Workers are forked web server processes. If using threads and workers together
# the concurrency of the application would be max `threads` * `workers`.
# Workers do not work on JRuby or Windows (both of which do not support
# processes).
#
workers ENV.fetch('WEB_CONCURRENCY') { 2 } ←ワーカー数
まずパフォーマンスについて考えるは2軸
サーバのパフォーマンスの効率化などを考える際に考えることは大きく分けて以下かなと思っています。
- サーバを効率よく使うために負荷試験を行い現状の実績値を把握してそれを元にサーバーの設定を最適化する
- 具体的な例だと、今回の記事のような、サーバのスレッド数やpool数、CPUコア数やメモリの設定値を幾つにすればいいかを負荷試験で確認する
- アプリケーションの処理速度の改善のためSQLのチューニングなどを行いリクエスト一つ一つが与えるサーバーへの負荷を軽減をする
- アプリ側のクエリでメモリを大きく消費するような大容量クエリがあるとサーバーの設定云々の話ではないので、それを確認し撲滅することでサーバーのパフォーマンスを改善する(今回はこのことについては記事に書いていない)
- 重いクエリがあり例えばそのクエリの処理時間に10秒かかってしまうとすると、その10秒の間に同じクエリを使うリクエストがどんどん来る場合、その処理が終わるまでpoolを占有することになるので、占有しているpoolが設定値の上限値に達すると、poolが空いていないので、リクエストがエラーになってしまうというのがカラクリ。(待ち行列が発生している状態)
- この場合は、pool数の増加より、ボトルネックになっている処理を見つけるためにソースコードを見直すことが重要になる
今回は負荷試験を行う予算がなかったので、スレッド数やpool数の設定値は、確認できるメトリクスのデータなどを参考に調整していきました。SQLのチューニングも行なっていますが、この記事では、サーバーの設定におけるパフォーマンスチューニングの話だけをしていきます。
CPUとメモリについて
サーバーのパフォーマンスを考える際にこの二つの理解は避けて通れませんでした。プロの方には釈迦に説法な話です。自分は素人なので、以下のように理解してます。
- CPU ≒ 頭脳
- コア数が多いほど処理能力が高くなる(スペックが高いほど処理速度も速い)
- メモリ ≒ 机の広さ
- メモリが大きいほど机の広さは広くなる(机にいっぱい処理を広げられるので同時にいろんなことができるため結果として処理速度が速くなる)
CPUの処理能力が高くても書類を広げる机の広さ(メモリ)が足りなければ処理しきれないので、CPUとメモリの設定はセットで考えることが必要です。
アプリケーションをサーバーで動かす場合は、その中で様々なプログラム(Rails,puma,種々のライブラリなど) が動いていて、プログラムを実行するときに、プロセスを立ち上げて、メモリを消費する。それぞれのプロセス内にはスレッドが立っており、当然pumaのプロセスにもスレッドが立つので、これらの数値をいじることで、同時アクセス時にどのようにアクセスを捌くかを調整できます。
今回は、アプリケーションサーバーpumaのプロセス内のスレッドを調整することで対処していきましたが、スレッドを増やすと、プロセスが消費するメモリも多くなるため、サーバー自体のメモリやCPUを調整しなければならず、その部分についても触れています。
サーバとDB
- サーバとDBのCPU使用率を見て、どちらがボトルネックかを見る
- サーバをオートスケールでスケールアウトして処理能力を上げても、DBのCPU使用率がオーバーして処理しきれなければ同じ。
- DBで処理できるマックスコネクション数の上限を確認
- 今回は、DBのマックスコネクション値が余りまくってたので、サーバーの方を調整したことになる
対応方針結論
以下の対応を行いました。
DBのマックスコネクション数に合わせてサーバで同時に処理できるアクセス数を増やす設定変更をサーバに対して実施
thread数を増やしDBのコネクションpool数を増やす
自分なりに色々な情報を収集しそれを元に噛み砕いた図です。スレッド数とかの設定値は適当です。
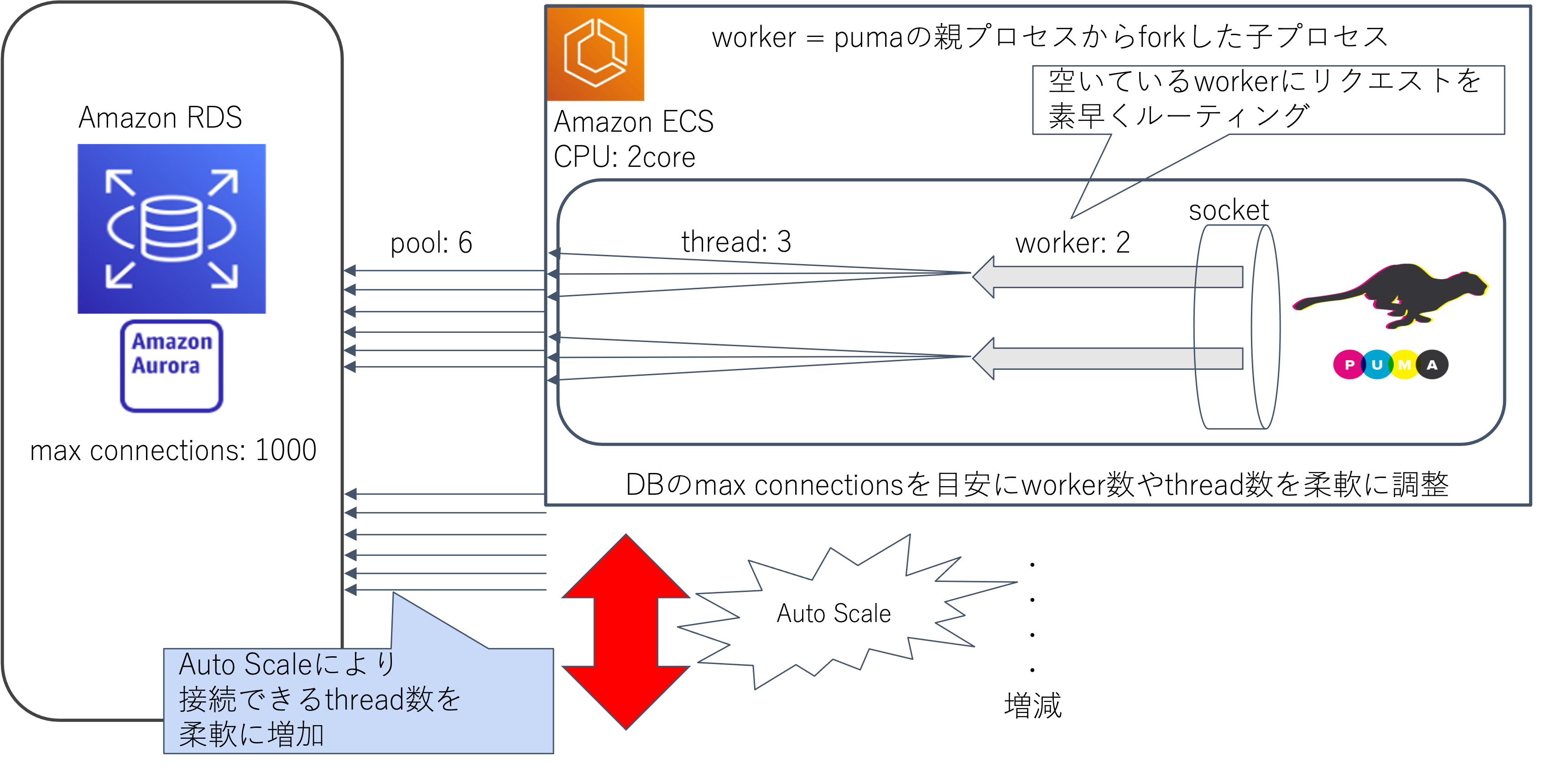
- worker = pumaの親プロセスからforkした子プロセス
- アプリ(puma)のプロセスを1つ作成し、そこから多数のコピー(worker)を作成
- Pumaは、どちらも複数の子プロセスが1つのソケットで直接リッスンする設計
- プロセスを複製するメリットとしては、Pumaのクラスタモードは、各workerプロセスの負荷のかかり具合を見てリクエストをよしなに流す機能がついているため。 これはロードバランサーで行う負荷分散の方式である「ラウンドロビン」や「ランダム配信」と比較して、より効率的に素早くリクエストを処理することができるので効率が良い
- threadを増やす方法自体は、アプリの並列性(同時処理、スループット)を簡易なリソース設定で改善できる点がメリット。
- 全体pool数 = worker数 × thread数 × タスク数(サーバー台数)= 並列実行可能数 ( https://blog.serverworks.co.jp/tech/2020/01/23/rails_connection_pool/ )
- pool数の設定はdatabase.ymlで行うが、スレッド数と pool数の設定値を揃えないと、スレッドで処理は受け付けているがそれを流すpool数が足りない(all pooled connections were in use)のエラーは解消されない。https://blog.serverworks.co.jp/tech/2020/01/23/rails_connection_pool/
- database.ymlのpoolに設定する値はpuma の thread 数の設定と同数とする。
- database.ymlでのpool数の設定は同一プロセスで使う最大DB接続数なので、プロセスが2つあって、それぞれで5スレッド動いているような場合、database.ymlでのpool数の設定は10にする必要はなく、5でよいということの模様。(workerの数を掛ける必要はなし)puma の thread 数の設定と同数とするいうことらしい。
If you are using the Puma web server we recommend setting the pool value to equal ENV[‘RAILS_MAX_THREADS’]
- mysql max connections = 1000(pool数はこれを超えてはいけない)
- マックスコネクション数の確認方法は後述
- 同時処理できるアクセス数を増やす設定をサーバに行うと、サーバのCPU使用率/メモリ使用率は上昇するリスクは上がるがオートスケールを行うので、そこで飲み込む
参考
参考にさせていただきました。ありがとうございます。
- https://techracho.bpsinc.jp/hachi8833/2017_11_13/47696
- https://tech.unifa-e.com/entry/2020/08/28/161733
- https://qiita.com/WisteriaWave/items/1e558cdf998793e97391
運用例
実際は以下のような感じになると思います。
- app
- worker 2 ✖︎ thread 30 = pool 60
- pool 60✖︎ ECS 3 = pool 180
- worker(push通知用の非同期処理用)
- worker 2 ✖︎ thread 30 = pool 60
- pool 60✖︎ ECS 3 = pool 180
- pool数合計
- 360
CPU使用率/メモリ使用率の現状等
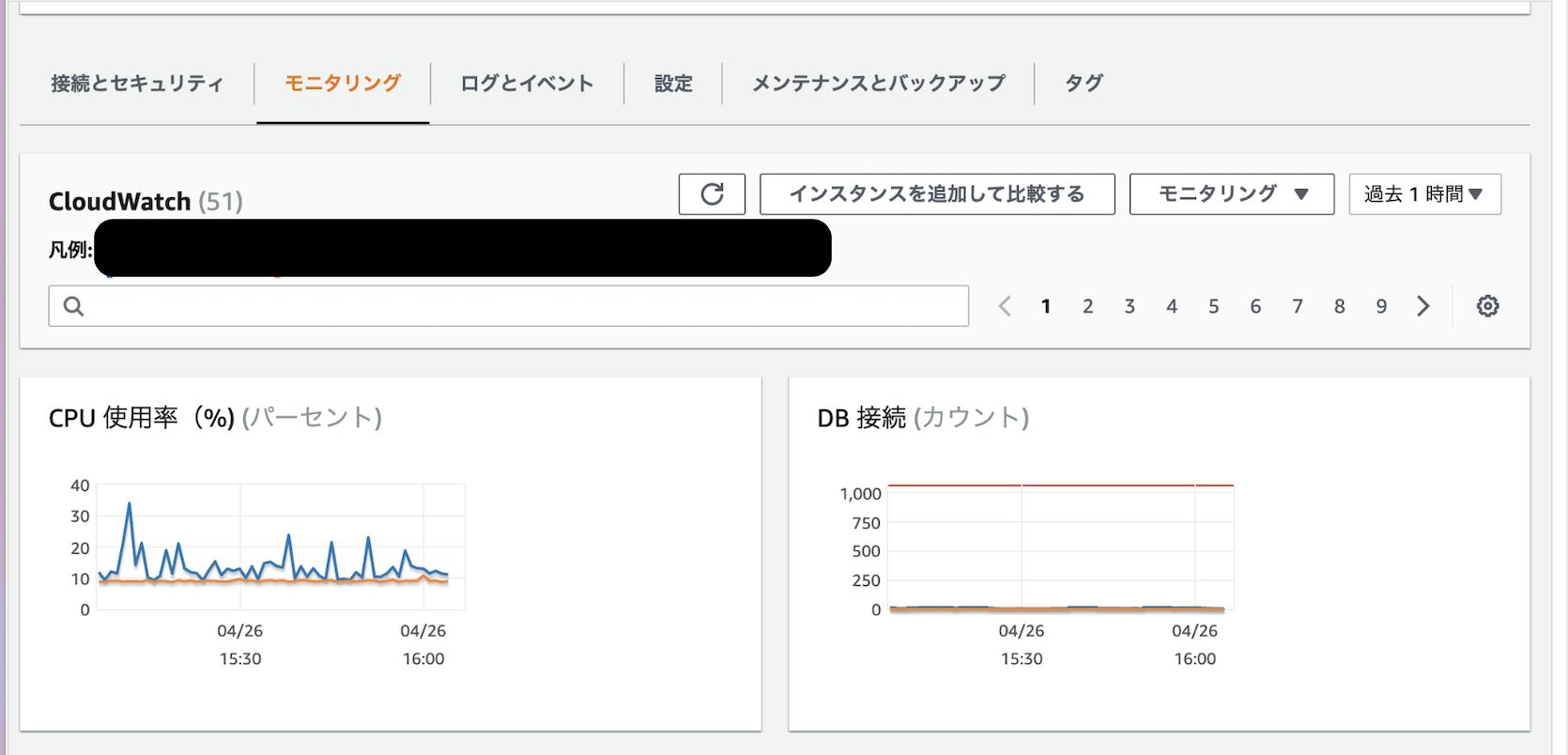
実際にメトリクスも確認していきました。
- RDSのCPU使用率/コネクションカウント
- DBのマックスコネクション数が1000なので増やしても大丈夫そう。
- マックスコネクション数の確認方法
show variables like "%max_connections%";
-
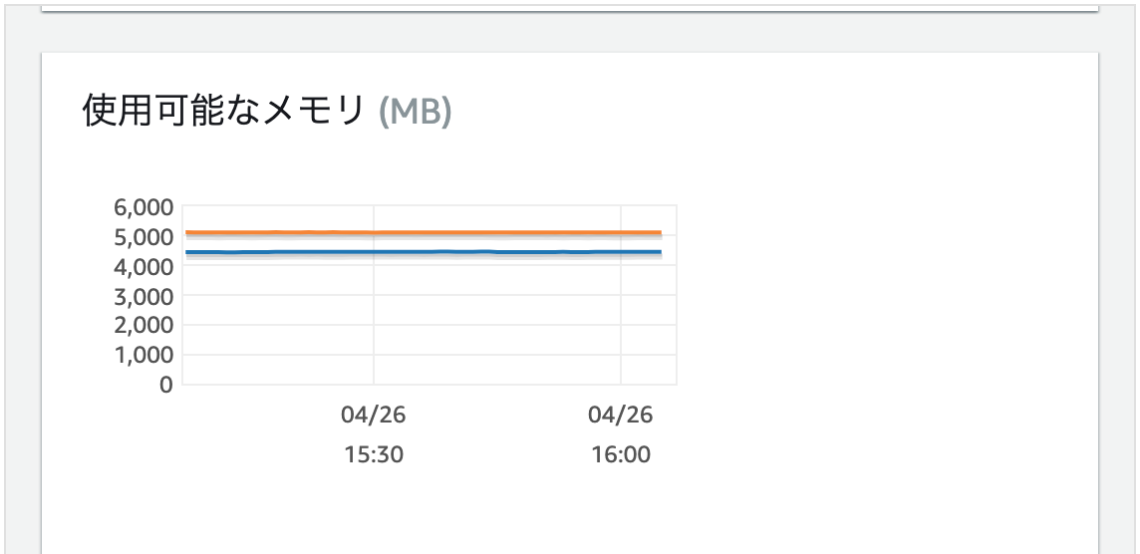
RDSの使用可能な空きメモリ
まだまだ全然大丈夫そう。
-
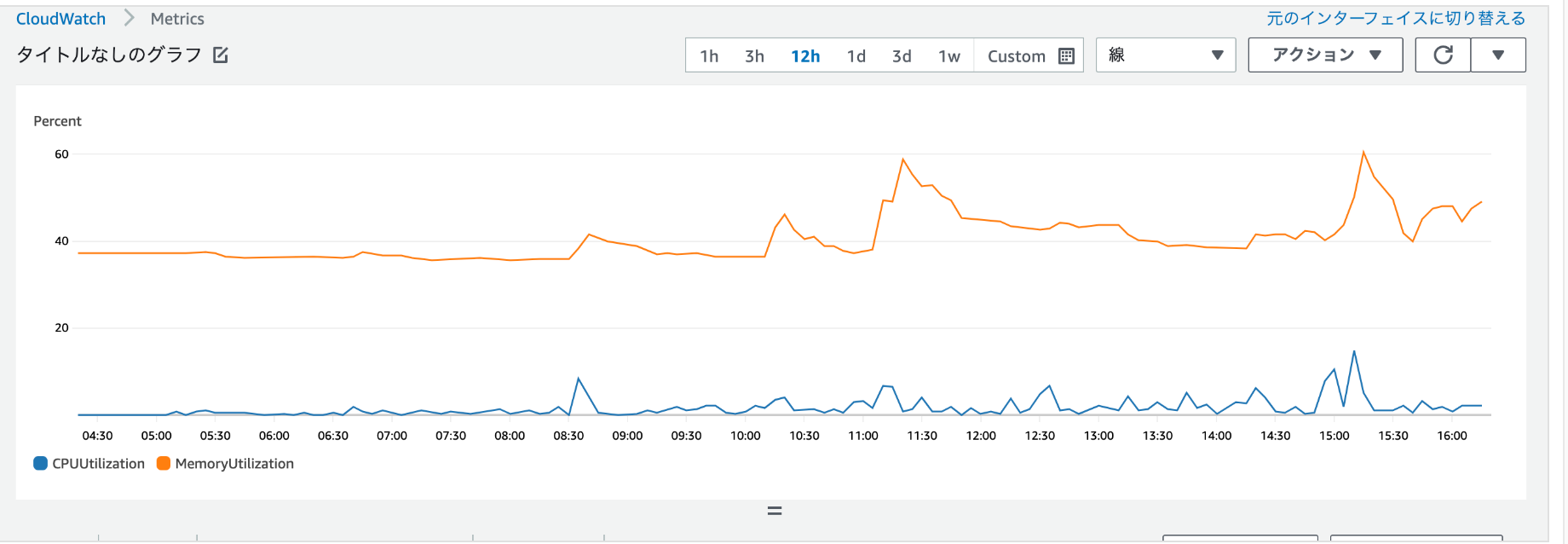
ECSのCPU/メモリ使用率
- メモリ使用率は平均で40%程度、60%に上がっている箇所は旧設定時に同時アクセスで待ちが発生している時間帯だったので、poolを増やせば解消されるため考慮不要。
- CPUがまだまだ空きがあると判断できるので、ECSのタスク数を増やすよりサーバの設定を変更して同時処理できるようにスレッド数、pool数を増やしてサーバのメモリの空きを活用できるようにしてあげる方が効率的。
-
ECSのタスク数をオートスケールにするため、サーバのCPUの負荷を気にしなくても勝手に増えてくれるので、とりあえずスレッド数は結構大きめに設定して大丈夫そう
ECSのオートスケールについて
-
ECSのオートスケールポリシー
- ECSのオートスケールポリシーはAWSが提供しているものとしては2種類存在
- オートスケールを行うと、コンテナ(タスク数)を増減させることができ、サーバーが落ちることを防ぐ
-
種類
- Target Tracking Scaling Policy
- Step Scaling Policy
-
Target Tracking Scaling Policy
指定したメトリクスが指定した数値になるようにスケールアウト/インを行うオートスケール
例えばCPUの平均使用率が50%となるように指定した場合は、それを超えるとスケールアウト(増加)する
50%を下回る場合は50%になるように合わせてタスク数を調整するが、最小タスク数を設定していればそのタスク数を下回ることはない
平均使用率の計算はこちら
- Step Scaling Policy
- 指定した閾値に基づいてスケールアウト/インを行うオートスケール
- スケールアウト/インを段階的に定義できる
例:
CPUの平均使用率が61-70% -> コンテナを1つ増やす
CPUの平均使用率が71-80% -> コンテナを3つ増やす
CPUの平均使用率が81%以上 -> コンテナを5つ増やす
CPUの平均使用率が50%以下 -> コンテナを1つ減らす
ECSのCPUユニット(コア数)やメモリについて
タスクサイズ
- タスクメモリ (MiB)
- Amazon EC2 インスタンスでホストされるタスクの場合、このフィールドは省略可能
- Fargate (Linux と Windows コンテナの両方) でホストしたタスクの場合、このフィールドは必須
- ハード制限
- タスク CPU (単位)
- Amazon EC2 インスタンスでホストされるタスクの場合、このフィールドは省略可能
- Fargate (Linux と Windows コンテナの両方) でホストしたタスクの場合、このフィールドは必須
- 1024のCPUユニットを持つタスクは、1個のCPUコアを専有出来る(= 1コアのCPU)
- ハード制限
コンテナ定義
Fargate タスク定義では、CPU とメモリをタスクレベルで指定する必要があります。Fargate タスクのコンテナレベルで CPU とメモリを指定することもできますが、これはオプションです。ほとんどのユースケースでは、タスクレベルでこれらのリソースを指定するだけで十分です。以下の表に、タスクレベルの CPU とメモリの有効な組み合わせを示します。

- メモリ制限(ハード制限)
- EC2 起動タイプを使用する場合は必須
- Fargate起動タイプを使用する場合はオプション
- メモリ制限(ソフト制限)
- EC2 起動タイプを使用する場合は必須
- Fargate起動タイプを使用する場合はオプション
- CPU ユニット数
- EC2 起動タイプを使用する場合は必須
- インスタンス毎のCPUユニット上限値については以下の計算で導出
- メモリから勘案してユニット数を幾つにするか考える
Amazon EC2 Instances 詳細ページのインスタンスタイプに一覧表示されている vCPU 数に 1,024 を乗算して、Amazon EC2 インスタンスタイプごとに使用可能な CPU ユニットの数を判断できます。
サービス(タスク)のCPU使用率/メモリ使用率の計算について
オートスケールの設定はCPU使用率/メモリ使用率はサービス単位で計算されるものを指標とし、サービス内のタスク数(コンテナ数)を増やせばCPU使用率は下がる(オートスケールを設定すればCPU使用率は上限値の設定を上回らない範囲で調整される)
サービス(fargate、ホストOS単位)のCPU使用率の計算
(Total CPU units used by tasks in service) x 100
Service CPU utilization = ----------------------------------------------------------------------------
(Total CPU units specified in task definition) x (number of tasks in service)
サービス(fargate、ホストOS単位)のメモリ使用率の計算
(Total MiB of memory used by tasks in service) x 100
Service memory utilization = --------------------------------------------------------------------------------
(Total MiB of memory specified in task definition) x (number of tasks in service)

ECSのメトリクス
-
Amazon ECS は使用しているサービスのCPUとメモリの平均使用量を含む CloudWatch メトリクスを発行
-
サービス単位だけでなくクラスター単位のメトリクスもある
クラスター全体のCPU使用率は下記の計算式
https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/developerguide/cloudwatch-metrics.html#cluster_utilization
(Total CPU units used by tasks in cluster) x 100
Cluster CPU utilization = --------------------------------------------------------------
(Total CPU units registered by container instances in cluster)