概要
保守しているシステムで、Railsからこんなエラーが出力されている。
Error while trying to deserialize arguments:
could not obtain a database connection within 5.000 seconds (waited 5.001 seconds)
このメッセージでググるとやたら「コネクションプール」というワードが見つかる。
・・・なにそれ?
そしてこのエラーはどうやったら解決できるの?
この記事は解決を目的としてあがいた記録である。
コネクションプールとは?
以下自分の理解。
ざっくり
- DBへの接続をあらかじめ作成・保持しておき、必要になった場面で貸し出すことにより、接続の手続き自体をなくして接続の負荷をカットするシステムのこと
詳細
DBへの接続をあらかじめ作成・保持しておく場所のことをコネクションプールという。
コネクションプールを利用する場合、アプリケーションからDBへの接続は、コネクションプール管理モジュールによって制御される。
コネクションプール管理モジュールには以下の機能がある。
- 設定された最大物理接続(※1)数までのDB接続をあらかじめ作成し、コネクションプールに保持しておく
- アプリケーションから論理接続(※1)要求があった場合、コネクションプールに保持してあるDB接続を渡す。
- ただし、コネクション枯渇(※2)の場合は、以下のような挙動をする(設定?によって異なる模様)
- パターン1:論理接続要求をコネクション取得待ちキューに入れて、DB接続の空きを待つ。
- パターン2:エラーを返す
- パターン3:最大物理接続数を超えてDB接続を行い、アプリケーションに払い出せるDB接続の空きを作る。処理が終わったら速やかにDB接続を切断する。
- しばらく使われていないDB接続を切断する、アプリケーション側でアイドル状態になってしまっているDB接続を強制的にコネクションプールに返却させるという機能もある。
コネクションプーリングでは、DB接続を保持し続けることで、アプリケーションから単純にDB接続した場合に発生する以下の課題を解決する。
- CPU使用量やDB接続にかかる時間、負荷が大きい(アプリサーバ/DBサーバ)
なおDB接続を保持し続けると、今度はメモリ使用率が大きくなるという新たな問題が発生する。
コネクションプール管理モジュールでは使われていないDB接続を開放することでこの問題を低減している。。
ちなみに、コネクションプール管理モジュールがある場所の違いとして、クライアント型/サーバ型の分類がある。
クライアント型とサーバ型
| 方式 | 説明 |
|---|---|
| クライアント型 | アプリケーションがコネクションプール管理モジュールも持つ方式。よく使われる方式らしい。 |
| サーバ(プロキシ)型 | アプリケーションとDB間にコネクションプールサーバを挟む方式。アプリケーションは接続要求のたびにコネクションプールサーバへ接続するため、クライアント型より遅い。障害発生時にキューで接続要求を管理できることがメリットらしい。 |
注記
※1 物理接続と論理接続
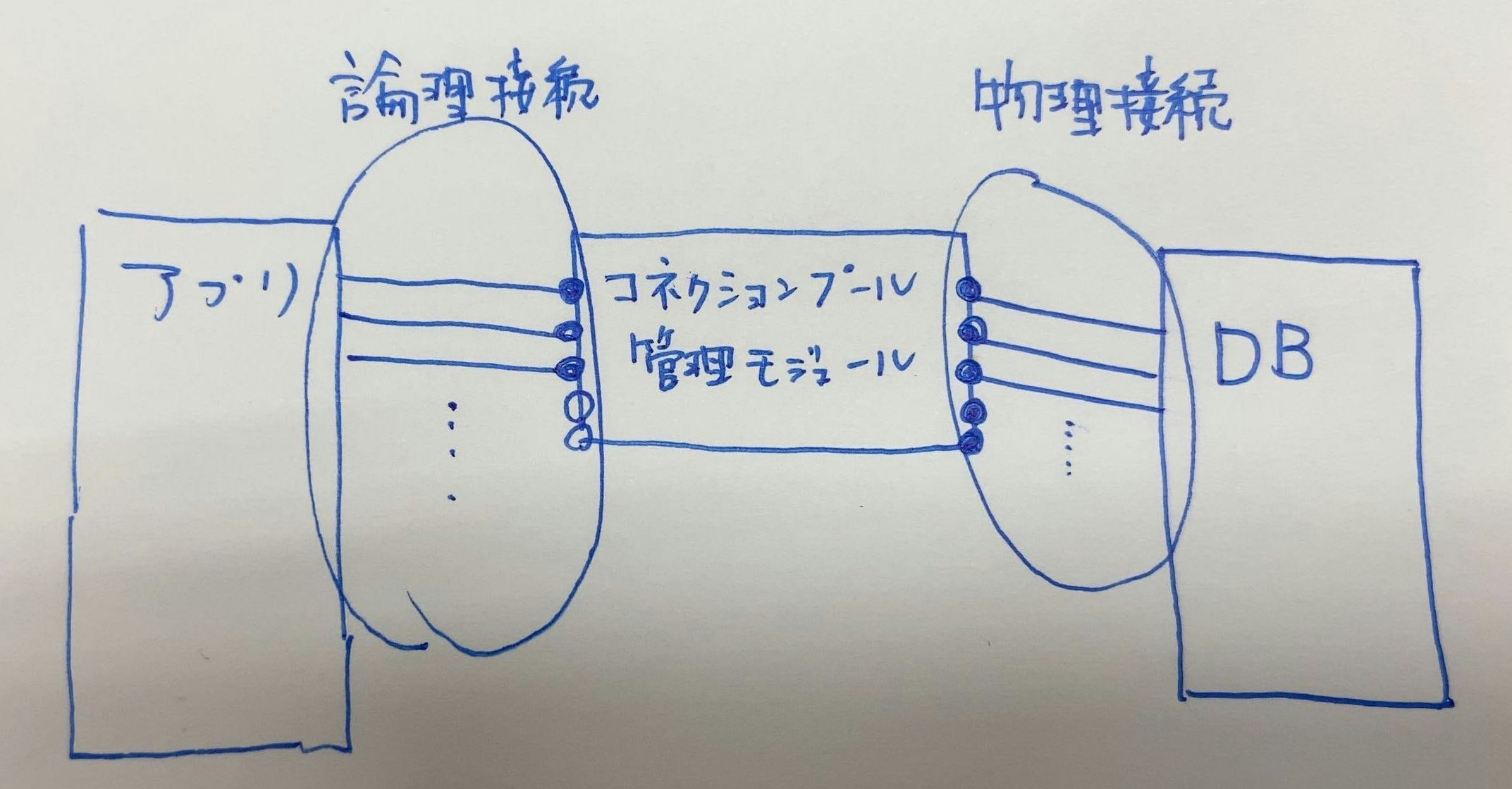
- 物理接続:コネクションプールからDBへの接続
- 論理接続:アプリケーションからコネクションプール管理モジュールへの接続。というかコネクションプール管理モジュールによって保持されているDB接続をアプリケーションにわたすこと。
※2 コネクション枯渇
コネクションプール管理モジュールからアプリケーションに払い出されているDB接続総数が、設定されている最大物理接続数に達してしまっている状態のこと
参考
https://wa3.i-3-i.info/word12762.html
https://support.asteria.com/hc/ja/articles/228983127-%E3%82%B3%E3%83%8D%E3%82%AF%E3%82%B7%E3%83%A7%E3%83%B3%E3%83%97%E3%83%BC%E3%83%AB%E3%81%A8%E3%81%AF%E4%BD%95%E3%81%A7%E3%81%99%E3%81%8B-
◎https://morizyun.github.io/blog/connection-pooling-database-db-postgresql/
http://e-words.jp/w/%E3%82%B3%E3%83%8D%E3%82%AF%E3%82%B7%E3%83%A7%E3%83%B3%E3%83%97%E3%83%BC%E3%83%AA%E3%83%B3%E3%82%B0.html
http://itdoc.hitachi.co.jp/manuals/3020/30203M0360/EM030358.HTM
https://www.techscore.com/blog/2019/09/19/%E3%82%B3%E3%83%8D%E3%82%AF%E3%82%B7%E3%83%A7%E3%83%B3%E3%83%97%E3%83%BC%E3%83%AA%E3%83%B3%E3%82%B0%E3%81%AF%E5%AE%9F%E9%9A%9B%E5%BF%85%E8%A6%81%E3%81%AA%E3%81%AE%E3%81%8B%EF%BC%88postgresql%EF%BC%89/
**これがコネクションプールの特にすばらしい参考記事だった。**→https://www.oracle.com/jp/technical-resources/articles/secret-of-oracle-site.html
現在のアプリケーションではどうなってるの?
エラーが発生しているシステムではコネクションプール用のサーバが立っているなど聞いたこともない。
railsからエラーが返ってきているので、クライアント型だろうと予想できた。
ネットを徘徊していると以下のような記事が。
Rails4.2のコネクションプールの実装を理解する
Railsではコネクションプール数を設定していても、1スレッドあたり1コネクションしか使いません。つまり、シングルスレッドのUnicornでは、1ワーカープロセス = 1コネクションとなります。
今のシステムのrailsも4.2だからこの記事の情報は有益そう。
エラーが発生してるのは、workerサーバ上でのsidekiqでのジョブ実行。
sidekiqについてはconcurrencyを20に設定しているので、1sidekiqプロセスで20スレッドがある。
最大20のDB接続が必要になるはず。
…とおもったが、
の記事によると、sidekiq起動時に1DB接続が発生するので、concurrencyの数 + 1をconfig/database.ymlのpoolに設定しとかないとダメらしい。
今のシステムを確認したところ、workerサーバについてはpoolは21に設定されていた。あれ?問題なさそうだが・・・?
気になるところ
1. リードレプリカでreadとwriteで同一DB参照してる&コネクション枯渇エラーでリードレプリカがらみのログが確認される
今のシステム、octopusというgemをつかってリードレプリカの設定してるんだけど、なぜか
readとwriteのDBが同じに設定されてるんだよね。
リードレプリカの意味がない・・・・。
なお、記事冒頭のエラーログについては(全部載っけてないけど)下のログが続きで出ていて、octopusがslaveへクエリーを投げている時にエラーが出てるっぽい。
.../gems/ar-octopus-0.8.6/lib/octopus/proxy.rb:479:in `block in send_queries_to_slave'
つまり、リードレプリカ周りが原因の一端を担っている可能性が高そう。
2. DB側の接続数を見ると、明らかにpoolの値超えてる*
コネクションプール管理モジュールで設定している最大接続数ではない、RDS(Postgres)に実際に接続されている数は以下のSQL文でpsqlから確認できる
SELECT client_addr, client_port, application_name, query_start, state FROM pg_stat_activity ORDER BY application_name asc, client_addr asc;
これで、確認した当時の実際のDB接続数はsidekiqのスレッドは「24」、sidekiq開始時のDB接続数は「2」だった。
あっ・・・!
の中に、slaveのpoolはshards.ymlで設定するっぽいようなコメントが。
ほうほう。じゃあ確認してみましょうかね?
ということで確認すると、poolが5に設定されていた。
・・・・あれ?もしかして・・・
database.ymlに設定されているpool 21と この5足したら26で実際のDB接続値と一致するやん!!
てことは、リードレプリカ使うときには write側の最大接続数はdatabase.ymlのpoolで設定が採用され、read側の最大接続数はshards.ymlの設定が採用される ってことか!
なるほどねーまとめると、・
sidekiqでは最大20のジョブを捌けるようにしてます。
書き込みの方はdatabase.ymlの設定でpool:21にしてるので、21個DB接続が確保されてるんで、並列実行に使われているスレッド数がmax20に達しても問題ないです。
でも・・・読み込みの方はshards.ymlの設定でpool:5にしてて、5個のDB接続しか確保されないんで、並列実行に使われるスレッド数が4より大きくなった時にコネクション枯渇します、っていうことになりますね。
…完全に片手落ちやん!意味ないやん!
解決しよう!
shards.ymlに21設定したら解決だろうと思ったが。
そもそもRDS(PostgreSQL)自体の最大接続数が80なんだよね。
で、今70くらい常時接続がある。
workerサーバーは2台あるので、それぞれのslaveのDBのpoolを5→21にすると、32増えますね。
・・・ってことは・・・最大物理接続数が70+32=102になっちゃって、DB自体の最大接続数上限超えますやん!
どうしましょうね・・・?
案は2つ。
案1 現状のDB接続最大数を維持する。
すなわちconcurrencyを12に,poolをmaster,slaveで13にする。
案2 DB1つしかないのでリードレプリカ使わないようにする
結論からするとより正統派の案2を採用した。
そもそもDB1つしかないのにリードレプリカ設定してる結果、read側のDB接続と、write側のDB接続が別枠扱いになっちゃってて、加えて同一DBを見てるんで読み込みにかかる負荷も変わってなくて、結果read分の接続保持に無駄にメモリ消費しちゃってるだけ っていう謎の状態だしね。
あっ、そういえば後から知ったのだが、 poolの設定は同一プロセスで使う最大DB接続数 らしい。つまり、プロセスが2つあって、それぞれで5スレッド動いているような場合、poolの設定は10にする必要はなく、5でいいらしい。