こんな人向けの記事です
- Power BIで取得したデータをさらにPower Automateに渡して処理したい
- BIのデータを定期的にSharePointフォルダにファイルとして書き出したい
- クラウドフローでCSVファイルを取り込んで処理したいが適当なアクションが見つからない
- プレミアムコネクタを使わずに様々なDBからデータを取り込みたい
経緯
この記事を書こうとした出発点は、Power BIのデータをPower Automateを使ってSharePointのフォルダに定期的に書き出したいというものでした。
この点については、以前までセマンティックモデルから改ページレポートを作成して、それをクラウドフローで書き出すという方法を採っていました。
ただ、改ページレポートを作るのも少し手間がかかりますし、管理するべきものが増えるのはできるだけ避けたいものです。そんな時に、こちらのアクションが使えるのでは?と思い立って試してみたのがきっかけです。
今回使用しているデータ
今回使用したデータは気象庁が提供している1時間ごとの観測点の気象データです。ダウンロードしてSharePointに保存して使いました。もちろん公開されているWeb上のデータに対して直接Power BIでアクセスして定期的に最新データを取り込むことも可能です。
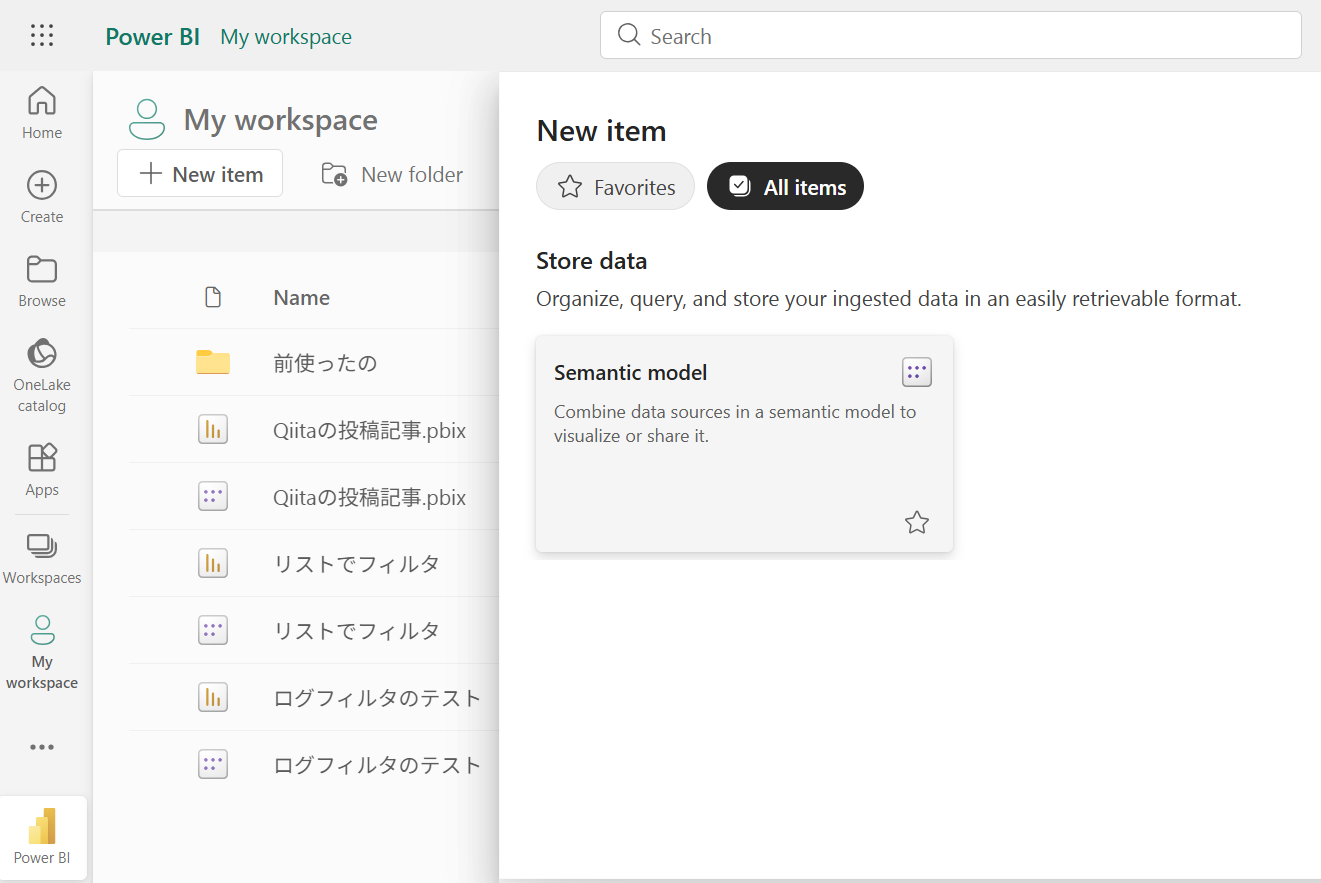
セマンティックモデルにデータを取り込む
まず、取り込みたいデータ(今回はSharePoint上のCSVファイルをセマンティックモデルに取り込みます。
以下はWeb上(Power BI サービス)で完結するためにワークスペース上からセマンティックモデルを作成していますが、もちろんPower BI デスクトップで取り込んで発行しても構いません。
テストしてみるとマイワークスペースではクラウドフロー側でエラーが出ました。Proライセンスを持っているユーザーでワークスペースを作成して実行する必要があるようです。
新規作成から、セマンティックモデルを選択します。
データの追加方法で「CSV」を選択します。
SharePoint上にCSVファイルを置いてある場合には、詳細からパスを取得しましょう。
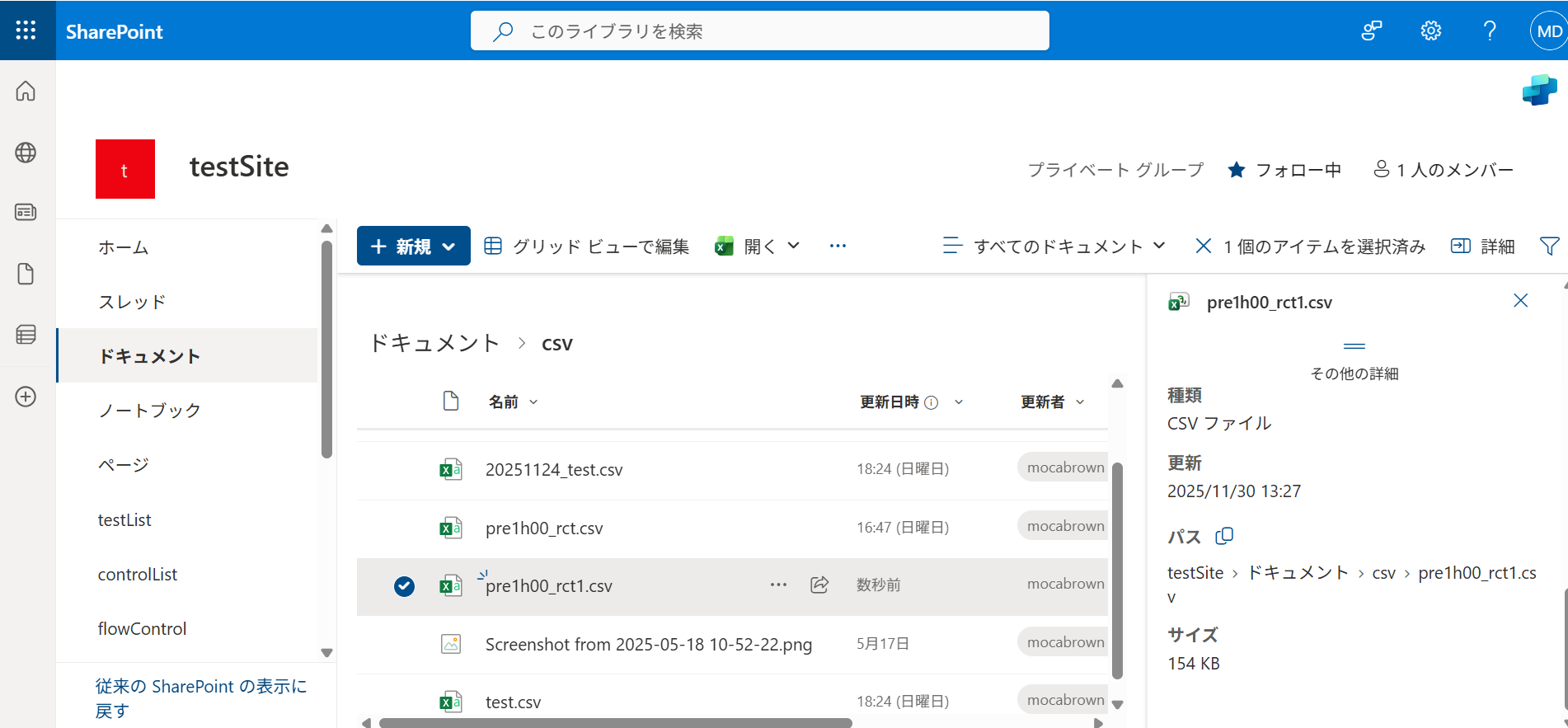
SharePoint上のファイルを取得しますので、認証方式は「組織アカウント」、プライバシーレベルも「組織」を選んでおくとよいでしょう。もちろんWeb上にオープンデータとして公開されているようなファイルも取り込めます。その場合は認証する必要がないので「匿名」を選びます。
CSVファイルの中身が見えますので、文字化けなどなければ次へ進みます。
ワークスペースを選択して、適当な名前をつけて保存します。作成をクリックします。
以下のような画面が現れますが気にせず、画面左側にあるワークスペースのアイコンをクリックしてワークスペースに戻ります。
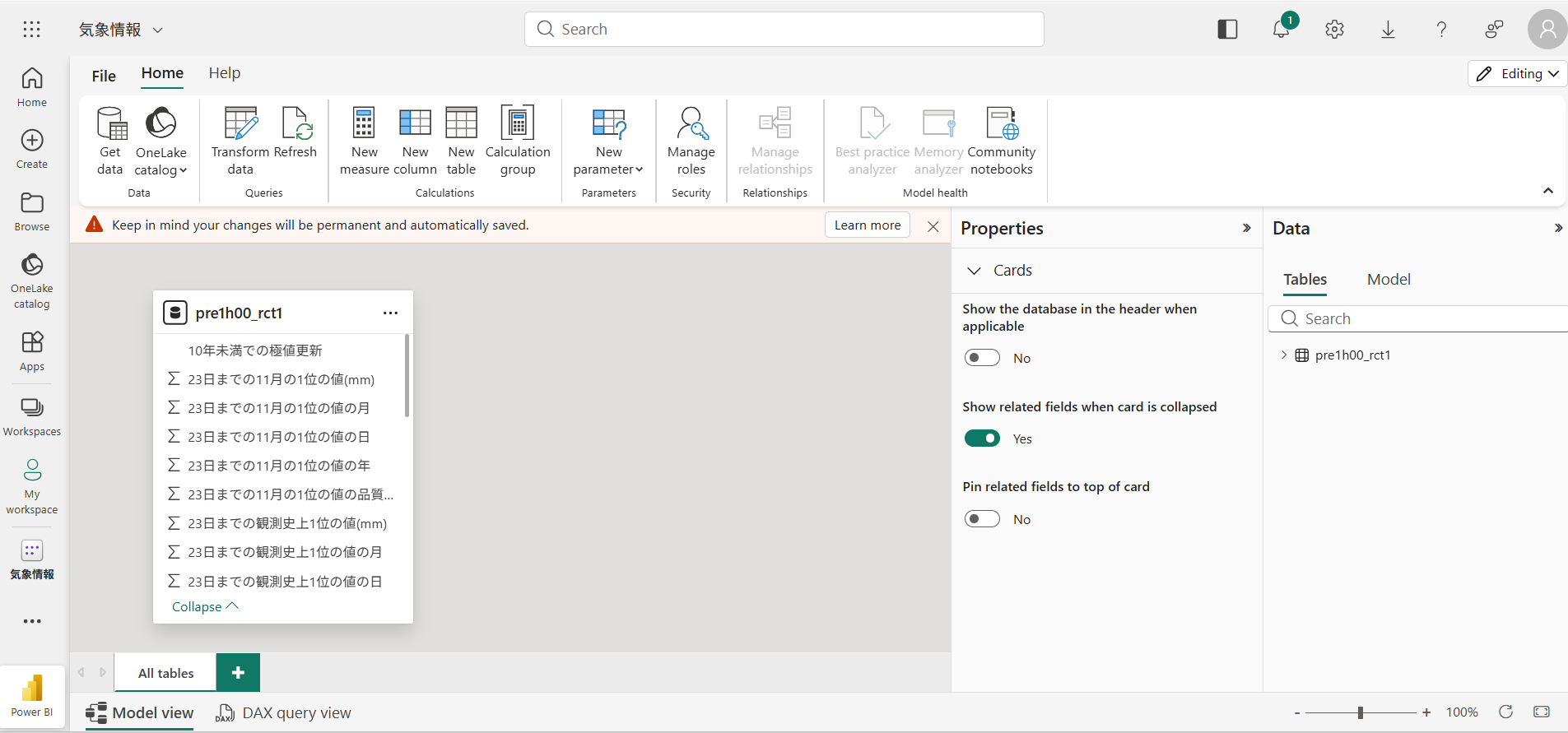
ワークスペースに先ほど名前を付けたセマンティックモデルが現れました。ざっくりいうと、取り込んだデータの塊のような存在です。Power BIではふつうこのセマンティックモデルに紐づいたレポート画面を作成してデータを見える化して表示させることができます。
今回はPower Automateにデータを取り込むことを主眼にしているので省きましたが、すでにBIレポートが広く公開されているというような場合には、そのデータが置いてあるワークスペースにアクセス権をつけてもらえるならば、再度活用できるというイメージでとらえてもらうとよいでしょう。
Power Automateからセマンティックモデルのデータを取り込む
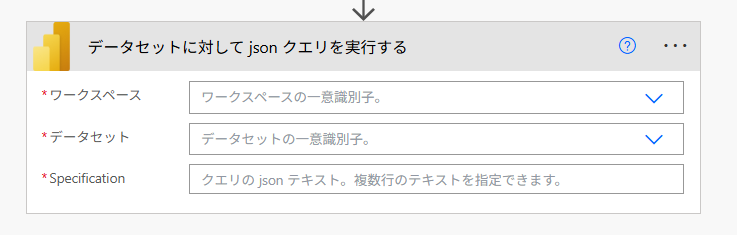
Power Automateで新しいクラウドフローを作成したら、「データセットに対してjsonクエリを実行する」を追加して
先ほどのワークスペースとデータセット(セマンティックモデルのこと)を指定します。
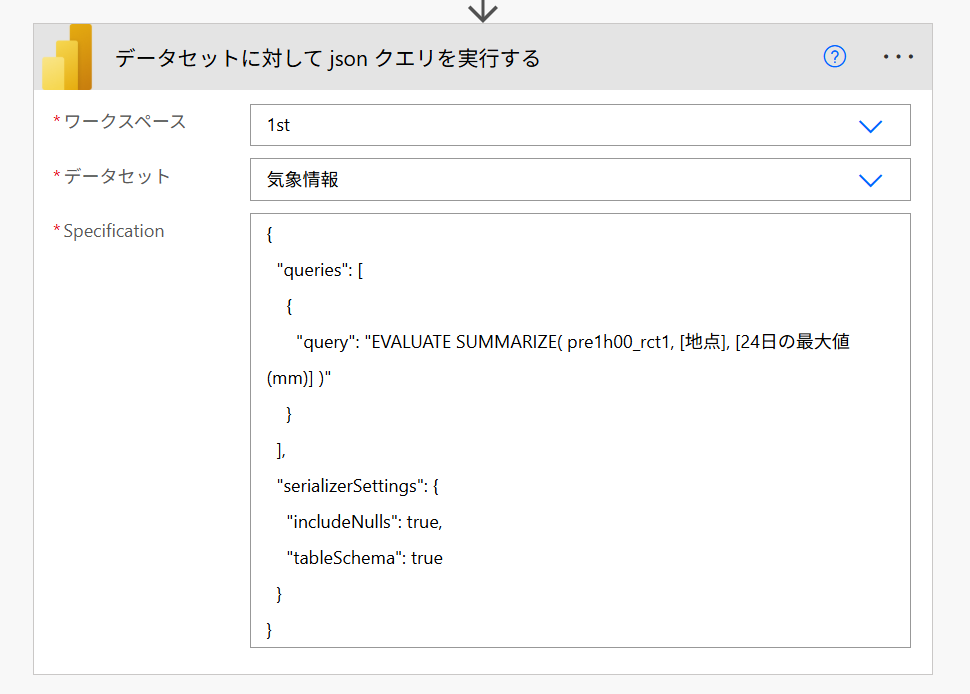
3番目の項目には、以下のようなJSONを記述します。
{
"queries": [
{
"query": "EVALUATE SUMMARIZE( pre1h00_rct1, [地点], [24日の最大値(mm)] )"
}
],
"serializerSettings": {
"includeNulls": true,
"tableSchema": true
}
}
こちらを実行してみると、以下のようなJSONとして結果が返ってきます。
ここまでできれば、あとは「選択」アクションなどを使って配列したり応用が利きます。
{
"results": [
{
"tables": [
{
"rows": [
{
"pre1h00_rct1[地点]": "豊富(トヨトミ)",
"pre1h00_rct1[24日の最大値(mm)]": 0
},
{
"pre1h00_rct1[地点]": "中頓別(ナカトンベツ)",
"pre1h00_rct1[24日の最大値(mm)]": 0
},
{
"pre1h00_rct1[地点]": "福井(フクイ)",
"pre1h00_rct1[24日の最大値(mm)]": 0
},
{
"pre1h00_rct1[地点]": "敦賀(ツルガ)",
"pre1h00_rct1[24日の最大値(mm)]": 0
},
{
"pre1h00_rct1[地点]": "彦根(ヒコネ)",
"pre1h00_rct1[24日の最大値(mm)]": 0
}
]
}
]
}
]
}
ちなみに、queryとして指示を出していることからわかるように、条件を加えることもできます。
たとえば、福井と敦賀でフィルターする場合はこのように指定します。
{
"queries": [
{
"query": "EVALUATE SELECTCOLUMNS( FILTER(pre1h00_rct1, pre1h00_rct1[地点] IN {\"福井(フクイ)\", \"敦賀(ツルガ)\"}), \"地点\", pre1h00_rct1[地点], \"24日の最大値(mm)\", pre1h00_rct1[24日の最大値(mm)] )"
}
],
"serializerSettings": { "includeNulls": true, "tableSchema": true }
}
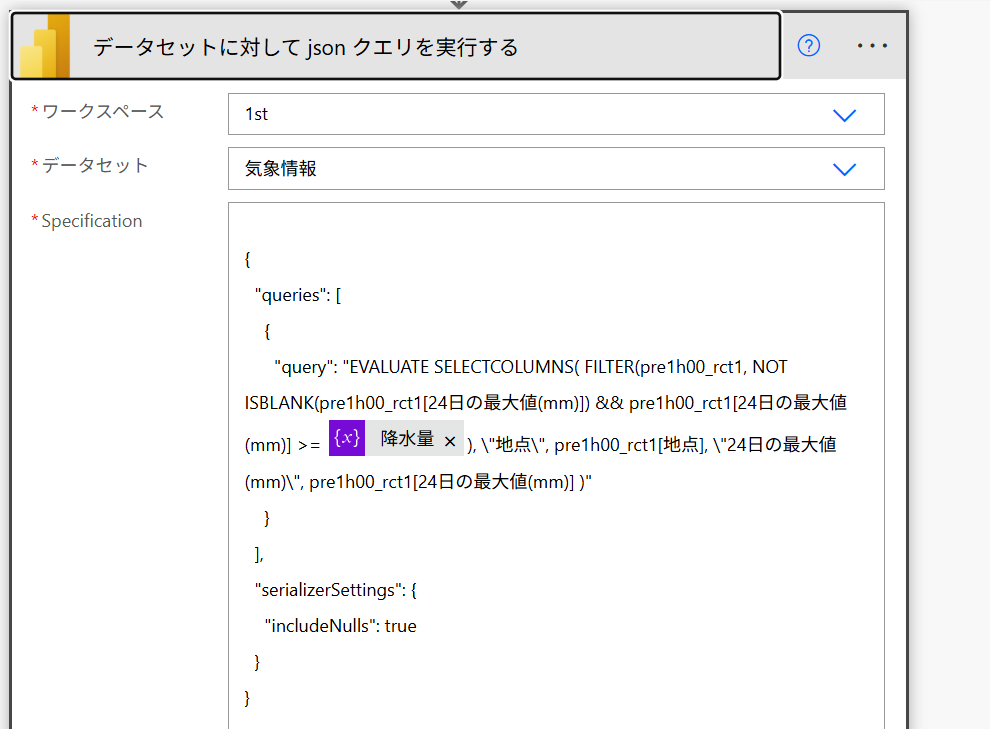
もちろん、等号、不等号も使えます。10mm以上の雨が降っていた地域だけをフィルターするには以下のように指定します。
{
"queries": [
{
"query": "EVALUATE SELECTCOLUMNS( FILTER(pre1h00_rct1, NOT ISBLANK(pre1h00_rct1[24日の最大値(mm)]) && pre1h00_rct1[24日の最大値(mm)] >= 10 ), \"地点\", pre1h00_rct1[地点], \"24日の最大値(mm)\", pre1h00_rct1[24日の最大値(mm)] )"
}
],
"serializerSettings": {
"includeNulls": true,
"tableSchema": true
}
}
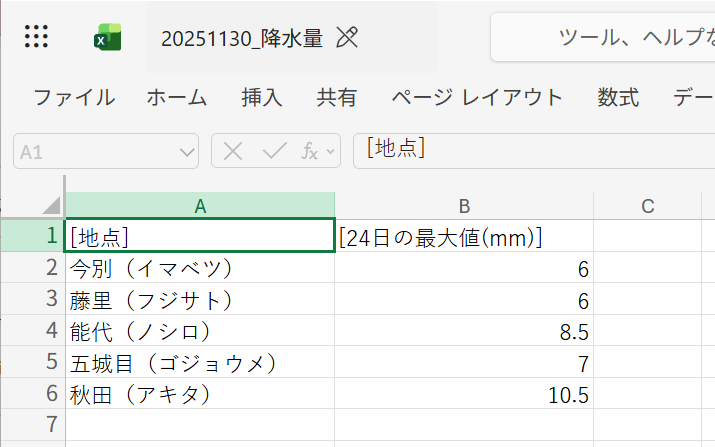
ちなみに出力結果はこのとおり。
{
"results": [
{
"tables": [
{
"rows": [
{
"[地点]": "秋田(アキタ)",
"[24日の最大値(mm)]": 10.5
}
]
}
]
}
]
}
当然、数値の指定には変数を使えるので、動的にクエリーを投げることができます。
たとえば、Power BIで用意したデータから、成績上位や平均点以上のメンバーを一覧にしてExcelファイルに書き出してSharePointフォルダに日付名ファイルとして保存、というような自動化ができそうです。
ファイル化は簡単
降水量の閾値は数値型の変数で指定してみました。「CSVテーブルの作成」アクションを使うと、JSONから簡単にCSV形式のテキストを作成できます。あとは、SharePointコネクタの「ファイルの作成」アクションにコンテンツとして渡してやるだけです。
ファイル名に指定する日付は以下のような関数を使います。
convertTimeZone(utcNow(), 'UTC', 'Tokyo Standard Time','yyyyMMdd')
「CSVテーブルの作成」には以下のように渡します。データ部分が深い位置にあるためです。
body('データセットに対して_json_クエリを実行する')?['results'][0]?['tables'][0]?['rows']
ファイルコンテンツの前には、文字化け防止の同じない関数を加えておきます。
decodeUriComponent('%EF%BB%BF')
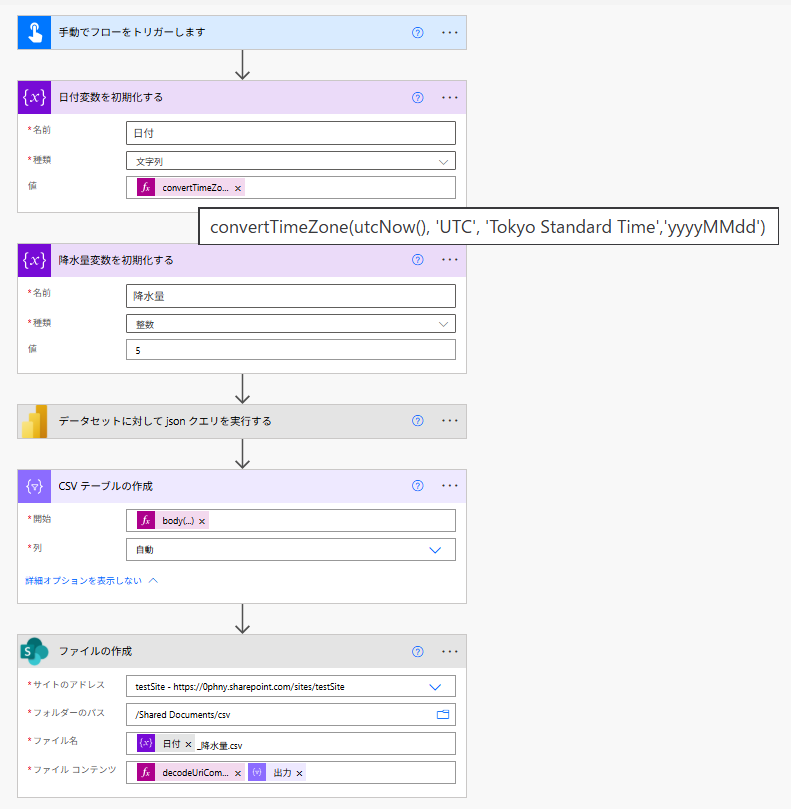
クエリ部分はこんな感じ。変数で降水量の数字を可変にしています。
こんな具合にCSVファイルを出力できました。
サマリーを作ってファイル化、再度BIで取り込みというのはいかが?
Power BIでは日頃とても大きなサイズのデータを扱います。
もちろんタイムインテリジェンスをつかってデータの推移をグラフ化したりという操作を大きなデータから行うこともできるのですが、過去の結果は変わらないという条件があるならば、このようにセマンティックモデルのデータからサマリーを作ってファイルとして保存し、その結果を再度Power BIで取り込むという方法も視野にいれるのはいかがでしょう?
今回はCSVファイルからセマンティックもでるを作りましたが、ご存じのようにPower BIはオンプレミスデータゲートウェイを使うとオンプレのDBをデータソースとして使うこともできます。このあたりをクラウドフローだけで実現しようと思うとプレミアムコネクタが必須になりますが、Power BIを噛ませることで大きなデータや、ちょっと変わったデータソースからの取得が容易になります。
Power BIとPower Automate、どちらか一方ではなくて、両方を使えるとできることの幅が広がるので、ぜひPower Platformの両輪として使ってみてはいかがでしょうか?
おまけ
この記事の前ふりとして、Power Automateで超高速にCSVファイルを取り込む方法を紹介しています。
記事はPower Automateアドベントカレンダー 2025/12/9に投稿しています。
今回は「データセットに対してJSONクエリを実行する」アクションを使いましたが、「データセットに対してクエリを実行する」アクションを使った方法もこちらで紹介しています。
また、同様のことを改ページレポートをつかっても実現できます。
武器はいろいろ持っているに越したことがありません。そういうのもあったなぁ、とぜひ頭の隅に。
こんな人が書いてます。
職場でPower Platformの管理者さんをしています。ブログではPower AutomateのTipsのようなものを書いています。QiitaではPower BIとクラウドフローのちょこ技を記事にしています。そちらも読んで「いいね」などしていただけるととっても喜びます。
大阪開催Power Platform系のイベントやオンラインの集まりには時々参加していますので、こちらのアイコンを見かけたら声をかけていただけると嬉しいです。