- 製造業出身のデータサイエンティストがお送りする記事
- 今回は、探索的データ解析(EDA)の一つであるautovizを試してみた。
はじめに
探索的データ解析(EDA:Exploratory data analysis)は、機械学習などのデータ分析業務を実施する際に、データの理解を目的として実施する作業を指します。
つまり、現場の問題を解決する際に、どのようなデータセットを扱っているのか、どのような状況にあるのかを、しっかりと理解するのが重要であり、探索的データ解析は上記を目的とした作業です。
過去には下記ライブラリーを使用した方法を整理しておりますので、参考にしてください。
autoviz実行例
今回は、探索的データ解析ツールの一つである「autoviz」を使ってみようと思います。
今回もUCI Machine Learning Repositoryで公開されているボストン住宅の価格データを用いてPandas-profilingを実装します。
pythonのコードは下記の通りです。
# 必要なライブラリーのインポート
import pandas as pd
import numpy as np
from autoviz.AutoViz_Class import AutoViz_Class
次にデータを読み込みます。
# データセットの読込み
df = pd.read_csv("../data/Boston.csv")
df.head()

次にautovizを実装します。
autoviz = AutoViz_Class().AutoViz("../data/Boston.csv")
これで実装は終了です。
autovizはjupyter notebook上で結果を確認できます。
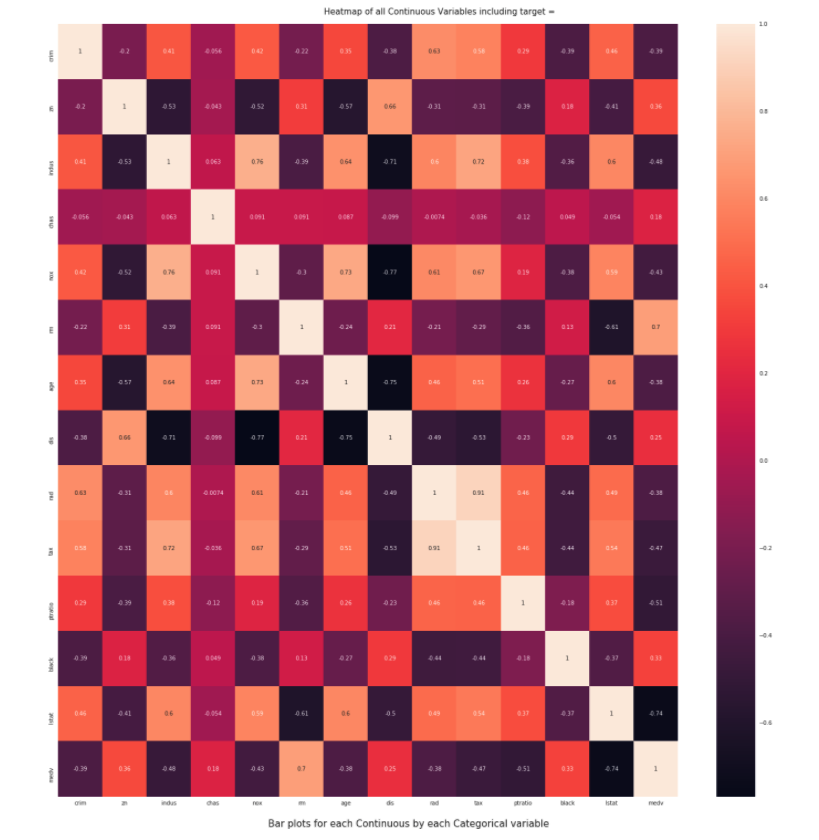
カラム間の関係性は下記のような感じで確認できます。

また、各カラムのヒストグラム、箱ひげ図、正規確率プロットも確認できます。
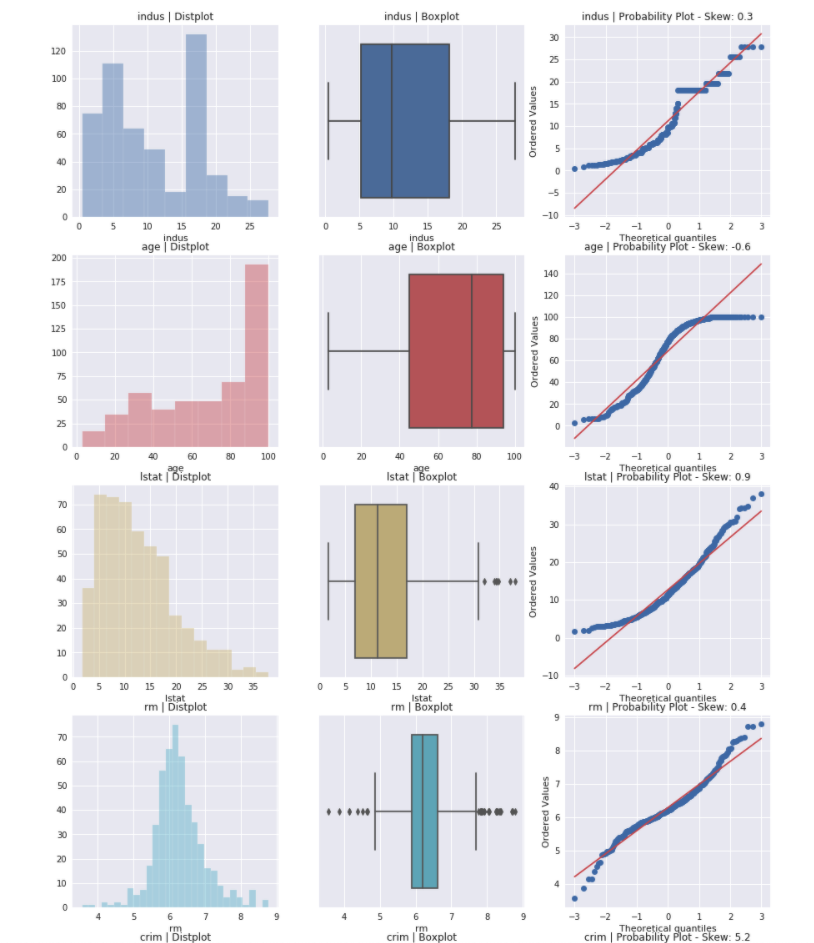
連続値については、ヴァイオリンプロットが表示されます。

カテゴリ毎の相関係数も確認できます。
さいごに
最後まで読んで頂き、ありがとうございました。
今回は、探索的データ解析の一つであるautovizを使ってみました。上手く活用するという意味では有効な方法の一つであると思いました。ただ、このライブラリーだけで全ては完結しないとは思いましたので、上手く活用できたらと思います。
訂正要望がありましたら、ご連絡頂けますと幸いです。