- 製造業出身のデータサイエンティストがお送りする記事
- 今回は、探索的データ解析(EDA)の一つであるPandas-profilingを試してみた。
はじめに
探索的データ解析(EDA:Exploratory data analysis)は、機械学習などのデータ分析業務を実施する際に、データの理解を目的として実施する作業を指します。
つまり、現場の問題を解決する際に、どのようなデータセットを扱っているのか、どのような状況にあるのかを、しっかりと理解するのが重要であり、探索的データ解析は上記を目的とした作業です。
Pandas-profiling実行例
今回は、探索的データ解析ツールの一つである「Pandas-profiling」を使ってみようと思います。
今回もUCI Machine Learning Repositoryで公開されているボストン住宅の価格データを用いてPandas-profilingを実装します。
pythonのコードは下記の通りです。
# 必要なライブラリーのインポート
import pandas as pd
import numpy as np
import pandas_profiling as pdp
from sklearn.datasets import load_boston
次にデータを読み込みます。
# データセットの読込み
boston = load_boston()
# データフレームの作成
# 説明変数の格納
df = pd.DataFrame(boston.data, columns = boston.feature_names)
# 目的変数の追加
df['MEDV'] = boston.target
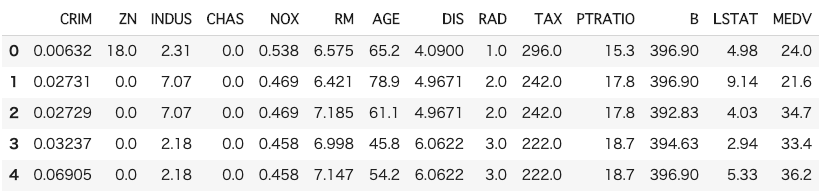
# データの中身を確認
df.head()
次にPandas-profilingを実装します。
report = pdp.ProfileReport(df)
report.to_file('Pandas-profiling_report.html')
これで実装は終了です。
後は、出力されたhtmlファイルを使って分析をしていきます。
Pandas-profilingで分析できる内容
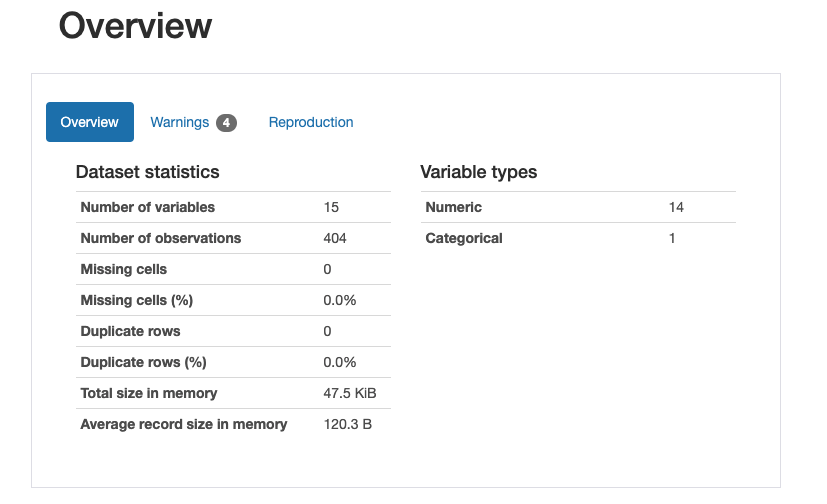
最初にデータの概要が分かります。
データの型や欠損率、サンプル数とかがパッと分かります。
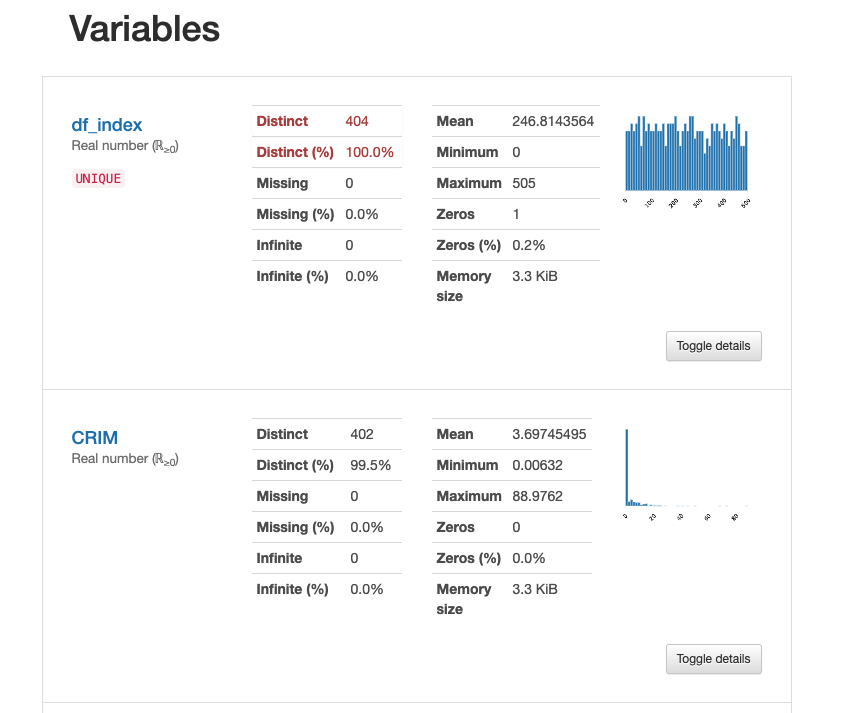
各カラムの基本情報やヒストグラムも一目で分かります。
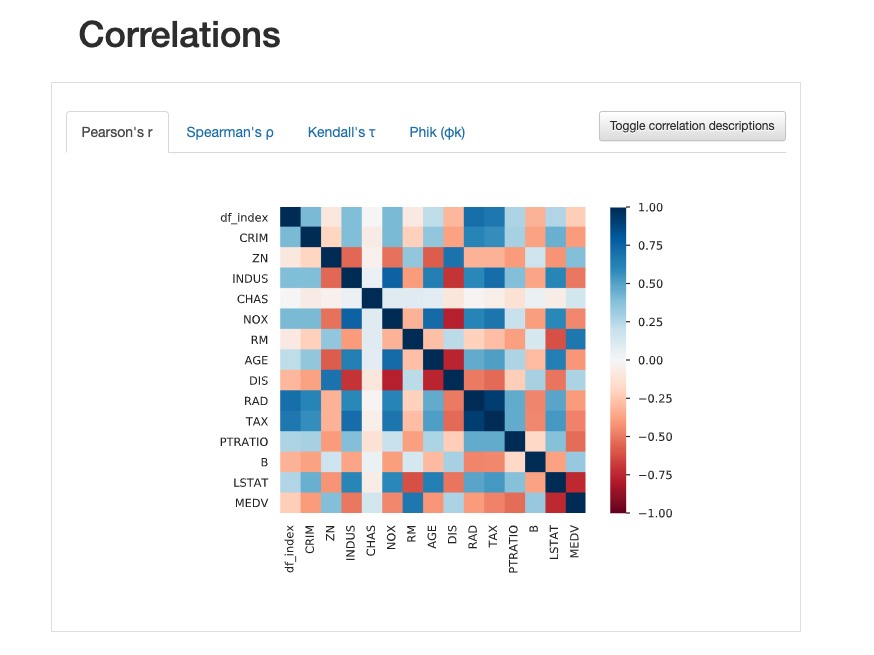
各変数同士の相関関係も分かります。
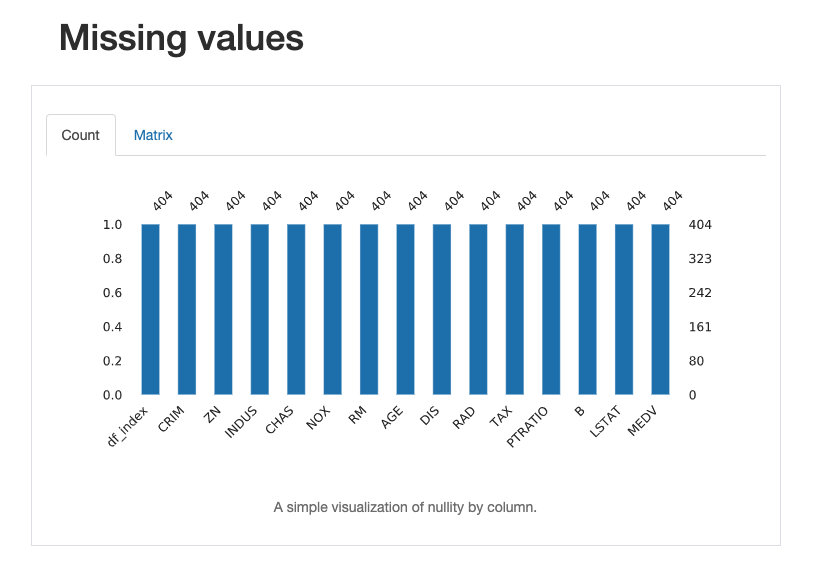
欠損率もカラム別に分かれております。
さいごに
最後まで読んで頂き、ありがとうございました。
探索的データ解析をこんなに簡単にできるのは非常に便利だと思いました。また、htmlファイルに出力されるので、関係者へ結果を共有する際にも便利だと思いました。
訂正要望がありましたら、ご連絡頂けますと幸いです。