- 製造業出身のデータサイエンティストがお送りする記事
- 今回は、探索的データ解析(EDA)の一つであるsweetvizを試してみた。
はじめに
探索的データ解析(EDA:Exploratory data analysis)は、機械学習などのデータ分析業務を実施する際に、データの理解を目的として実施する作業を指します。
つまり、現場の問題を解決する際に、どのようなデータセットを扱っているのか、どのような状況にあるのかを、しっかりと理解するのが重要であり、探索的データ解析は上記を目的とした作業です。
過去には下記ライブラリーを使用した方法を整理しておりますので、参考にしてください。
sweetviz実行例
今回は、探索的データ解析ツールの一つである「sweetviz」を使ってみようと思います。
今回もUCI Machine Learning Repositoryで公開されているボストン住宅の価格データを用いてPandas-profilingを実装します。
pythonのコードは下記の通りです。
# 必要なライブラリーのインポート
import pandas as pd
import numpy as np
import sweetviz as sv
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
次にデータを読み込みます。
# データセットの読込み
boston = load_boston()
# データフレームの作成
# 説明変数の格納
df = pd.DataFrame(boston.data, columns = boston.feature_names)
# 目的変数の追加
df['MEDV'] = boston.target
# データの中身を確認
df.head()
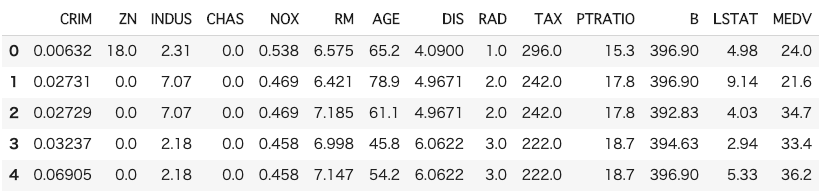
今回は、学習データと評価データを分けておくと効率的に分析できますので、分けます。
# 学習データと評価データを作成
x_train, x_test, y_train, y_test = train_test_split(df.iloc[:, 0:13], df.iloc[:, 13],
test_size=0.2, random_state=1)
df_train = pd.concat([x_train, y_train], axis=1)
df_test = pd.concat([x_test, y_test], axis=1)
次にsweetvizを実装します。
my_report = sv.compare([df_train, "Train"], [df_test, "Test"], "MEDV")
# 直接ブラウザに表示
my_report.show_html("sweetviz_report_2col.html")
これで実装は終了です。
後は、出力されたhtmlファイルを使って分析をしていきます。
sweetvizで分析できる内容
最初に表示される全体像を確認します。
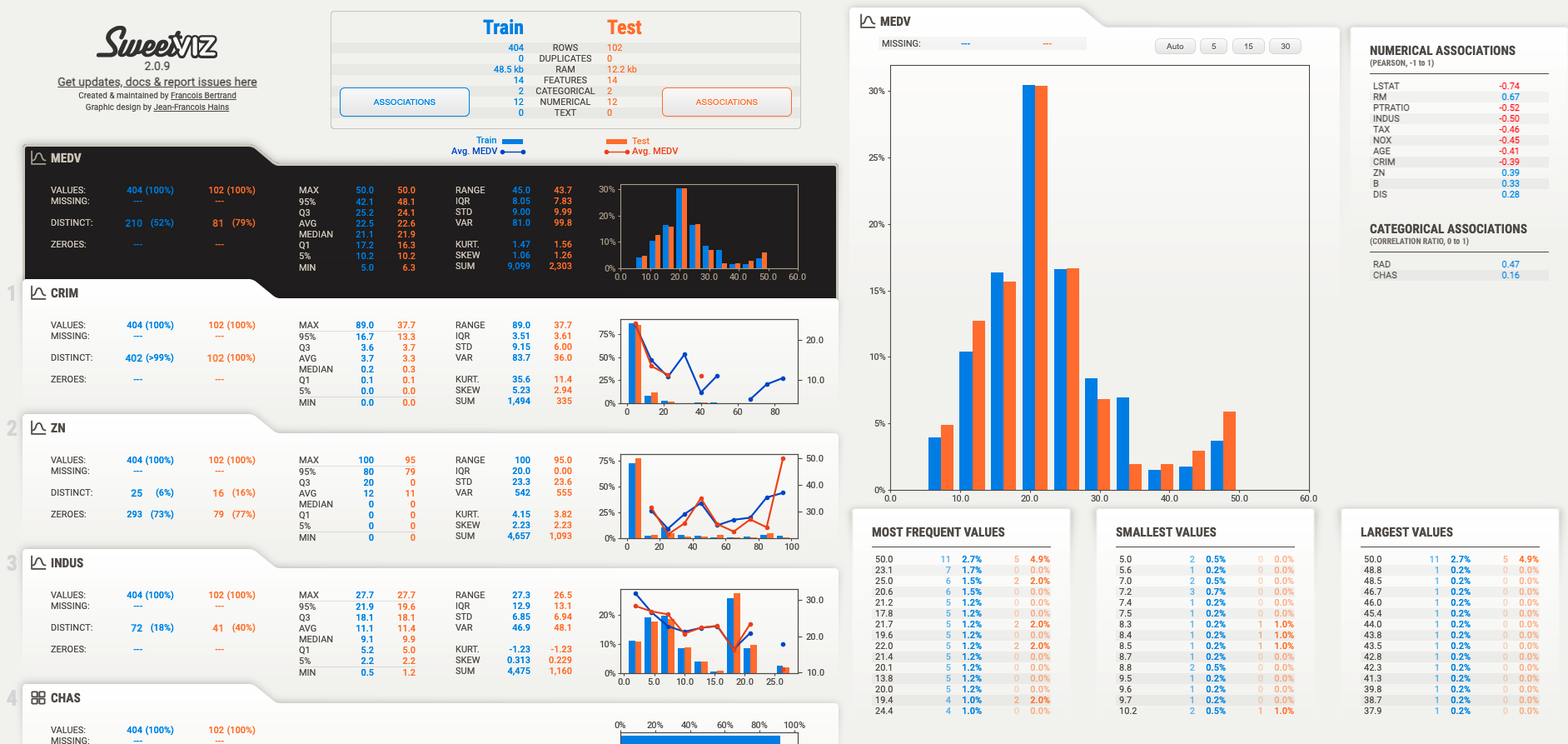
相当細部までデータの概要を把握できそうです。
全体の概要は下記画面で確認できます。
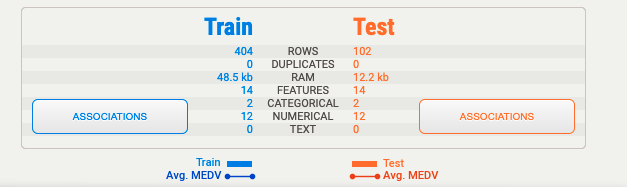
確認できる内容は下記の通りとなっております。
- 行数
- 重複有無
- メモリ使用量
- 特徴量の数
- カテゴリ列の数
- 数値列の数
- テキスト列の数
これだけの情報を学習データと評価データでぱっと分かるように表示されているのは便利ですね。
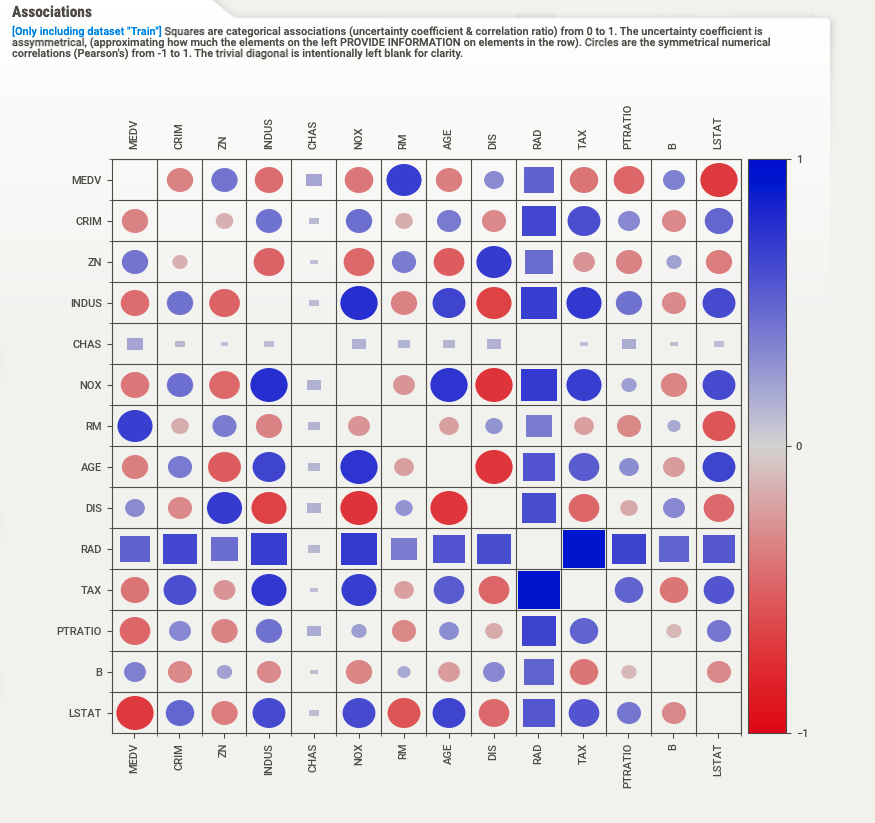
また、「ASSOCIATIONS」のボタンを押すことで相関係数も確認できます。
各特徴量の概要は下段に整理されております。
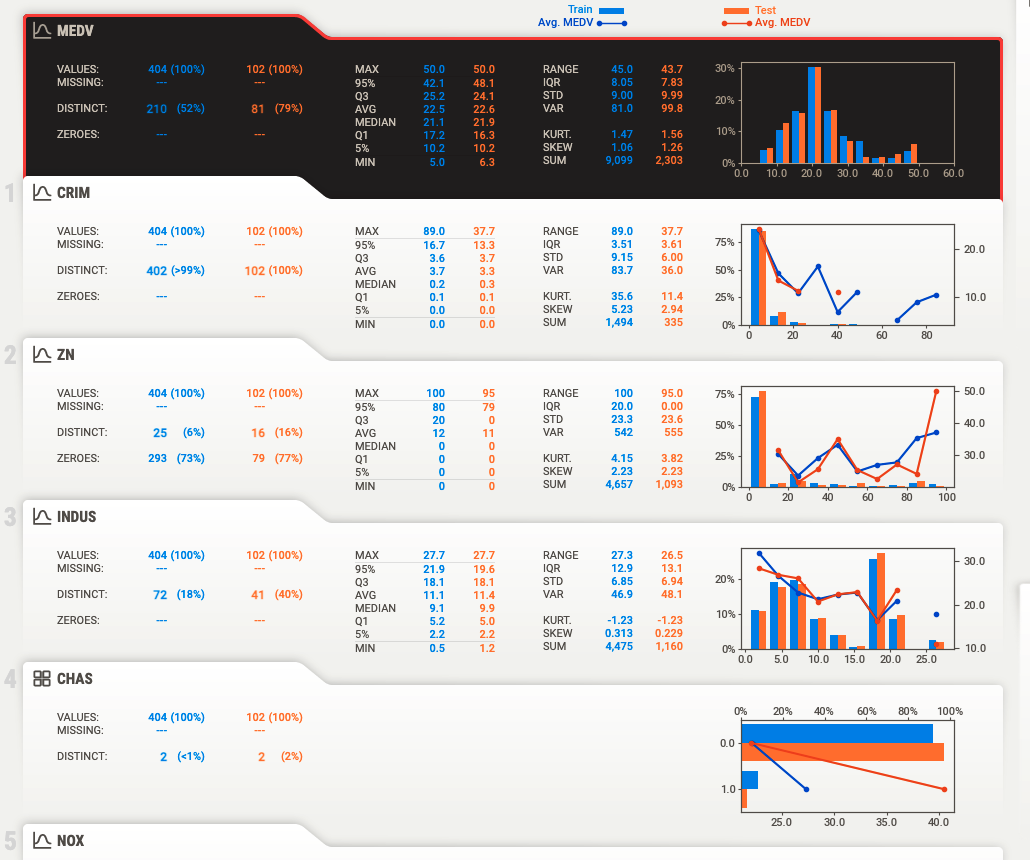
全て、学習データと評価データを対比して見れるのが便利ですね。
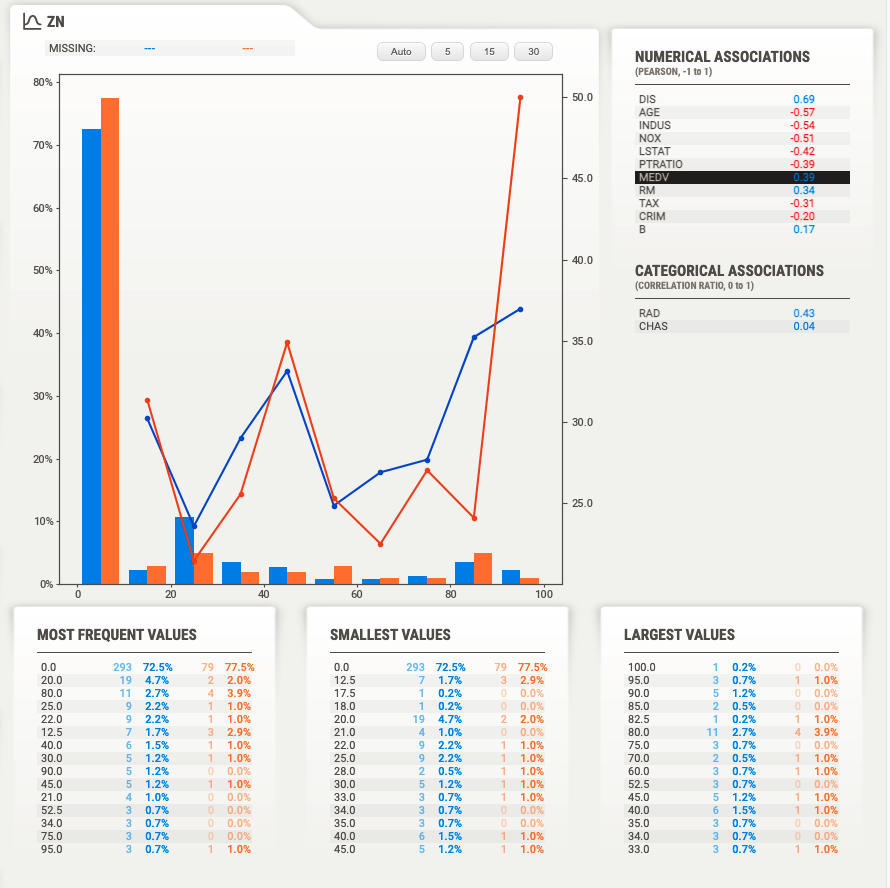
各カラムの詳細は対象のカラムをクリックすると更に細かく見れます。
さいごに
最後まで読んで頂き、ありがとうございました。
前回のPandas-profilingと言い、sweetivizも含めて探索的データ解析をこんなに簡単にできるのは非常に便利だと思いました。
訂正要望がありましたら、ご連絡頂けますと幸いです。