- 製造業出身のデータサイエンティストがお送りする記事
- 今回は多目的最適化手法の中で、NSGA-Ⅲを実装(サンプルコード使用)しました。
はじめに
先日、ご紹介した多目的最適化(NSGA-Ⅲ)を実装したのでご紹介します。
NSGA-Ⅲとは何か?と言うことについては上記の記事に書いておりますので、そちらをご参照ください。
使用するライブラリー(deap)
今回も遺伝的アルゴリズムライブラリdeapを使って実装したいと思います。
NSGA-Ⅲの実装
今回はdeapのチュートリアルにNSGA-Ⅲのサンプルがありましたので、そちらを活用しました。
pythonのコードは下記の通りです。
# 必要なライブラリーのインポート
from math import factorial
import random
import matplotlib.pyplot as plt
import numpy
import pymop.factory
from deap import algorithms
from deap import base
from deap.benchmarks.tools import igd
from deap import creator
from deap import tools
import matplotlib.pyplot as plt
import mpl_toolkits.mplot3d as Axes3d
最初に遺伝的アルゴリズムの設計を行っていきます。
# 問題設定
PROBLEM = "dtlz2"
NOBJ = 3
K = 10
NDIM = NOBJ + K - 1
P = 12
H = factorial(NOBJ + P - 1) / (factorial(P) * factorial(NOBJ - 1))
BOUND_LOW, BOUND_UP = 0.0, 1.0
problem = pymop.factory.get_problem(PROBLEM, n_var=NDIM, n_obj=NOBJ)
# アルゴリズムのパラメータ
MU = int(H + (4 - H % 4))
NGEN = 400
CXPB = 1.0
MUTPB = 1.0
# reference point
ref_points = tools.uniform_reference_points(NOBJ, P)
# 適合度を最小化することで最適化されるような適合度クラスの作成
creator.create("FitnessMin", base.Fitness, weights=(-1.0,) * NOBJ)
# 個体クラスIndividualを作成
creator.create("Individual", list, fitness=creator.FitnessMin)
# 遺伝子生成の関数
def uniform(low, up, size=None):
try:
return [random.uniform(a, b) for a, b in zip(low, up)]
except TypeError:
return [random.uniform(a, b) for a, b in zip([low] * size, [up] * size)]
# Toolboxの作成
toolbox = base.Toolbox()
# 遺伝子を生成する関数"attr_gene"を登録
toolbox.register("attr_float", uniform, BOUND_LOW, BOUND_UP, NDIM)
# 個体を生成する関数”individual"を登録
toolbox.register("individual", tools.initIterate, creator.Individual, toolbox.attr_float)
# 個体集団を生成する関数"population"を登録
toolbox.register("population", tools.initRepeat, list, toolbox.individual)
# 評価関数"evaluate"を登録
toolbox.register("evaluate", problem.evaluate, return_values_of=["F"])
# 交叉を行う関数"mate"を登録
toolbox.register("mate", tools.cxSimulatedBinaryBounded, low=BOUND_LOW, up=BOUND_UP, eta=30.0)
# 変異を行う関数"mutate"を登録
toolbox.register("mutate", tools.mutPolynomialBounded, low=BOUND_LOW, up=BOUND_UP, eta=20.0, indpb=1.0/NDIM)
# 個体選択法"select"を登録
toolbox.register("select", tools.selNSGA3, ref_points=ref_points)
各コードで何を実施しているのかはコメント文で分かるように記載しているため、コード全体が見にくくなっている部分はご容赦願います。
今回は、DTLZ2問題(ベンチマーク関数)を使用しています。
次に実際の進化計算部分になります。
def main(seed=None):
random.seed(1)
# 世代ループ中のログに何を出力するかの設定
stats = tools.Statistics(lambda ind: ind.fitness.values)
stats.register("avg", numpy.mean, axis=0)
stats.register("std", numpy.std, axis=0)
stats.register("min", numpy.min, axis=0)
stats.register("max", numpy.max, axis=0)
logbook = tools.Logbook()
logbook.header = "gen", "evals", "std", "min", "avg", "max"
# 第一世代の生成
pop = toolbox.population(n=MU)
pop_init = pop[:]
invalid_ind = [ind for ind in pop if not ind.fitness.valid]
fitnesses = toolbox.map(toolbox.evaluate, invalid_ind)
for ind, fit in zip(invalid_ind, fitnesses):
ind.fitness.values = fit
record = stats.compile(pop)
logbook.record(gen=0, evals=len(invalid_ind), **record)
print(logbook.stream)
# 最適計算の実行
for gen in range(1, NGEN):
# 子母集団生成
offspring = algorithms.varAnd(pop, toolbox, CXPB, MUTPB)
invalid_ind = [ind for ind in offspring if not ind.fitness.valid]
# 適合度計算
fitnesses = toolbox.map(toolbox.evaluate, invalid_ind)
for ind, fit in zip(invalid_ind, fitnesses):
ind.fitness.values = fit
# 次世代選択
pop = toolbox.select(pop + offspring, MU)
record = stats.compile(pop)
logbook.record(gen=gen, evals=len(invalid_ind), **record)
print(logbook.stream)
return pop, pop_init, logbook
あとは、このmain関数を呼び出します。
if __name__ == "__main__":
pop, pop_init, stats = main()
pop_fit = numpy.array([ind.fitness.values for ind in pop])
pf = problem.pareto_front(ref_points)
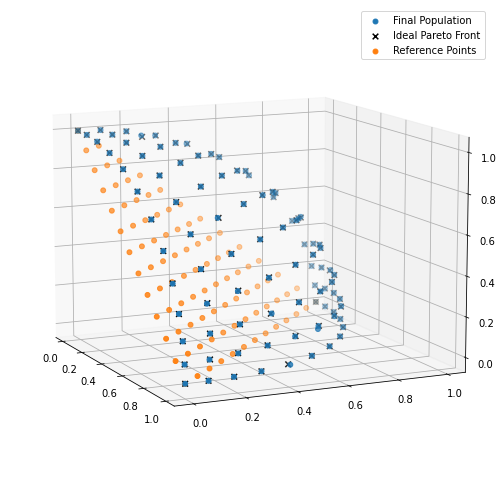
今回は、Reference Pointsと最終世代の結果を可視化してみたいと思います。
fig = plt.figure(figsize=(7, 7))
ax = fig.add_subplot(111, projection="3d")
p = numpy.array([ind.fitness.values for ind in pop])
ax.scatter(p[:, 0], p[:, 1], p[:, 2], marker="o", s=24, label="Final Population")
ax.scatter(pf[:, 0], pf[:, 1], pf[:, 2], marker="x", c="k", s=32, label="Ideal Pareto Front")
ref_points = tools.uniform_reference_points(NOBJ, P)
ax.scatter(ref_points[:, 0], ref_points[:, 1], ref_points[:, 2], marker="o", s=24, label="Reference Points")
ax.view_init(elev=11, azim=-25)
ax.autoscale(tight=True)
plt.legend()
plt.tight_layout()
さいごに
最後まで読んで頂き、ありがとうございました。
今回は、多目的最適化のNSGA-Ⅲについてサンプルコードを確認しました。
実際の業務で使う際は、NSGA-Ⅱ、NSGA-Ⅲともに制約条件を業務実態に合わせた形で細かく整理する部分が大変になるのかなと思います。
また、目的変数が4つ以上でパレート解を求めようと思うと可視化できないため、その部分も工夫する必要がありそうです。
訂正要望がありましたら、ご連絡頂けますと幸いです。