今北産業
RelGANという画像変換モデルがあるよ!
声質変換に応用するよ!
声質モーフィングができるよ!
序論
美少女になりたいという男性が増えています。逆に美少年になりたいという女性も多いでしょう。近年では特にバーチャルYouTuberの流行に伴いその傾向も顕著になっています。外見についてはCG技術のMMDやイラストを動かせるLive2Dなどが登場し徐々に自分のなりたい姿へと変身することができる時代になりつつありますが、可愛い女の子の声、または格好いい男の子の声になりたいというのも大きな課題の一つです。本稿ではRelGAN-VMというモデルによる複数話者間の声質変換および話者のうち二話者の中間の声を作る声質モーフィングを提案します。
本稿を読むにあたって
本稿では割と難しめの単語が飛び交います。最低限の補足はするつもりですがある程度の知識を要します。具体的には以下の知識を前提として書いています。
- 大学初級レベルの数学、統計学
- ディープラーニングの基本、敵対的生成ネットワーク(GAN)による画像の生成や変換
- 音声処理の基本、最低限のサウンドプログラミング能力、音声処理におけるMel尺度の存在
検索すれば本稿の著者が説明するよりわかりやすい記事がたくさんヒットすると思うので、わからない用語や単語があったらぜひ検索にかけてみてください(丸投げ)。
先行、関連研究もしくは記事
先行研究
- CycleGAN-VC Parallel-Data-Free Voice Conversion Using Cycle-Consistent Adversarial Networks
- CycleGAN-VC2: Improved CycleGAN-based Non-parallel Voice Conversion
- StarGAN-VC Non-parallel many-to-many voice conversion with star generative adversarial networks
- StarGAN-VC2: Rethinking Conditional Methods for StarGAN-Based Voice Conversion
CycleGAN-VCでは二話者間の声質変換を行いCycleGAN-VC2ではより性能を向上させています。
StarGAN-VCでは複数話者間の声質変換を行いStarGAN-VC2ではより性能を向上させ声質モーフィングの提案も行われています。
関連記事(外部リンク含む)
CycleGANベースの変換器を用いてバーチャルYouTuberの声質を変換しています。丁寧な手法によりスペクトログラムベースでありながら驚異的な変換性能を示しています。
pix2pixベースの手法により記事の著者の方の声を「VOICEROID 結月ゆかり」の声質に交換しています。こちらも高性能。
提案手法
本稿ではRelGAN: Multi-Domain Image-to-Image Translation via Relative Attributes(以下、RelGANと呼ぶ)とCycleGAN-VC2をベースとしたRelGAN-VMを提案します。RelGANやCycleGAN-VC2についての詳細な解説は非常に明快な記事を執筆されている方がいらっしゃるのでそちらをご参照ください(以下これらの記事の著者の方をLentoさんとお呼びすることにします)。
パラレル変換とノンパラレル変換
パラレル変換
同じ発音内容、音階情報、発声タイミングのデータセットを必要とします。これらはどうしても同じにならないのでアライメントをとる必要があります。変換元および変換先が声質以外同じ内容のデータを必要とするため、データセットの構築には膨大な労力を要しますがデータ量は比較的少なく済む印象です。「ディープラーニングの力で結月ゆかりの声になってみた」はパラレル変換を採用しているようです。
ノンパラレル変換
異なる発話内容、音階情報、発声タイミングをもったデータセットで学習します。アライメントを必要とせずただ文章を読み上げているようなデータであればいいのでデータセットの構築は比較的容易です。CycleGANやStarGANをベースとした手法はノンパラレル変換が採用されています。
また本実装及び本家RelGANもノンパラレル変換を用いています。
ネットワーク構造
RelGAN-VMのGenerator、およびDiscriminatorはCycleGAN-VC2をベースとしGeneratorはInputにRelative attributesをconcatenateしたものを、Discriminatorは最終層のConvolutionを取り除き$D_{real}$、$D_{interp}$、$D_{match}$の3つに分岐させています。詳しくは実装をご覧ください。
損失関数
ベースとなるRelGANの損失関数は以下のようになります。本実装ではorthogonal regularizationは使用しませんでした。
$$
{\min_{D}}L_{D}=-L_{adv}+{\lambda_1}L_{match}^D+{\lambda_2}L_{interp}^D
$$
$$
{\min_{G}}L_{G}=L_{adv}+{\lambda_1}L_{match}^G+{\lambda_2}L_{interp}^G+{\lambda_3}L_{cycle}+{\lambda_4}L_{self}
$$
この損失関数で学習させたときは30000steps程度でMode collapseを起こしたので本実装ではこれらに加えていくつかの制約を追加しています。
Triangle consistency loss
N個のドメインから3つ選びそれらをA,B,Cとします。ドメインをA→B→C→Aと変換したときの入力と出力の差を損失とします。ドメインAからBへの変換をするとき、入力画像を$x$, Relative attributesを$v_{ab}$, Generatorを$G(x, v_{ab})$と表記することにします。式で書くと以下のようになります。
$$
L_{tri}=||x - G(G(G(x, v_{ab}), v_{bc}), v_{ca})||_1
$$
Backward consistency loss
補間率${\alpha}$だけ変換させた出力に対してもCycle consistency loss的な損失をとります。式で書くと以下のようになります。
$$
L_{back}=||x - G(G(x, {\alpha}v_{ab}), -{\alpha}v_{ab})||_1
$$
Mode seeking loss
Mode Seeking Generative Adversarial Networks for Diverse Image Synthesisで提案された手法です。日本語解説を書かれている方がいらっしゃったので [最新論文/cGANs]モード崩壊を解決するかもしれない正則化項をご参照ください。
潜在変数$z_a$,$z_b$を変換した$I_a=G(z_a)$, $I_b=G(z_b)$に対し
$$
\frac{d_I(I_a, I_b)}{d_z(z_a, z_b)}
$$
を最大化する問題のようです($d_I(I_a,I_b)$は生成画像間の距離で$d_z(z_a,z_b)$は潜在変数間の距離)。
本実装はこれを元に以下の式を最小化するよう損失を加えました。
$$
L_{ms}=\frac{{||x_1-x_2||_ 1}}{||G(x_1,v_{ab})-G(x_2,v_{ab})||_1}
$$
これらの損失を足し合わせた結果Generator側のLossは次のようになります。
$$
{\min_{G}}L_{G}=L_{adv}+{\lambda_1}L_{match}^G+{\lambda_2}L_{interp}^G+{\lambda_3}L_{cycle}+{\lambda_4}L_{self}+{\lambda_5}L_{tri}+{\lambda_6}L_{back}+{\lambda_7}L_{ms}
$$
実験
実装はGithubにアップロードしています。
njellinasさんという方のCycleGAN-VC2の実装、GAN-Voice-Conversionをベースに改変しています。
RelGANライクに書き直す際には公式論文とLentoさんのRelGANの実装を参考にしました。
データセット
データセットとしてJVS (Japanese versatile speech) corpusをお借りしました。
学習用データとしてjvs010, jvs016, jvs042, jvs054のparallel100を使用しました。またvalidation用として各話者のnonpara30からそれぞれ5ファイルほど使用しました。
parallel100は発話内容、音階情報、発声タイミングがかなり保存されていますが(完璧ではない)今回はnonparallelなデータとして扱います。
各話者の印象を主観的に書きます。
- jvs010(女性、$f_o$が非常に高くアニメキャラクターのような声)
- jvs016(女性、$f_o$が低めでアナウンサーのような声)
- jvs042(男性、$f_o$が低めで筆者の声に類似)
- jvs054(男性、$f_o$が高めでナレーターのような声)
前処理
特徴量の抽出にはWorldのPythonラッパー、pyWorldを使用します。
ですが特徴量を抽出する前にひと手間加えます。
無音除去
学習データ内に無音が多いとそれ自体を特徴として学習してしまうことがあります。また特徴量抽出時にプログラムがエラーなしで終了することがあったので無音を除去することにしました(どこかで0除算か無限大への発散が発生している可能性がある、要原因究明)。無音除去の方法は色々ありますが今回はシンプルにlibrosaを使用しました。一旦$f_o$をとって$f_o>0$部分を取り出すという方法も考えられます。
音声データ長の整列
バッチの作成にはまず音声データをランダムに1つ選びそこから指定した長さの特徴データをランダムに切り出す、という操作を行います。ここで各音声データの長さが異なるとそれぞれのサンプルが等確率で選ばれなくなります。これを防ぐために一度すべての音声を結合した後等しい長さの音声データに切り分けるということを行っています。
特徴量の抽出
切り分けられた音声データに対してpyWorldで特徴量を抽出します。筆者も正直何をやっているか理解していないのですが(大問題)、$f_o$とMCEPs$sp$を求めそこから${\mu_{f_o}}$,${\sigma_{f_o}}$,${\mu_{sp}}$,${\sigma_{sp}}$を算出し$sp$を正規化したものを保存しているといったところでしょうか。
学習
ここまで来てようやくディープラーニングにかけることができます。使用するモデルやネットワークは前述のとおりです。
正規化したMCEPsは36次元で、それをランダムに128フレームを選んだものを入力します。さらに一定確率(0.0005%)で完全な無音をバッチに挿入します。またBatch sizeは8としました。したがって入力サイズは(8, 36, 128)となります(推論時は(1, 36, 128))。
GANはLSGANを使用しました。CycleGAN-VC2やStarGAN-VC2でも採用されているため王道を行きました。
オプティマイザはAdamを使用し、learning lateはGeneratorが0.0002, Discriminatorが0.0001で学習が始まり、1stepごとにそれぞれ0.99999倍に減衰させています。${\beta_1}$=0.5, ${\beta_2}$=0.999となっています。
損失関数の${\lambda}$はそれぞれ${\lambda_1}=1, {\lambda_2}=10, {\lambda_3}=10, {\lambda_4}=10, {\lambda_5}=5,{\lambda_6}=5, {\lambda_7}=1$ としています。また${\lambda_5}, {\lambda_6}$については10,000steps毎に0.9倍に減衰させています。
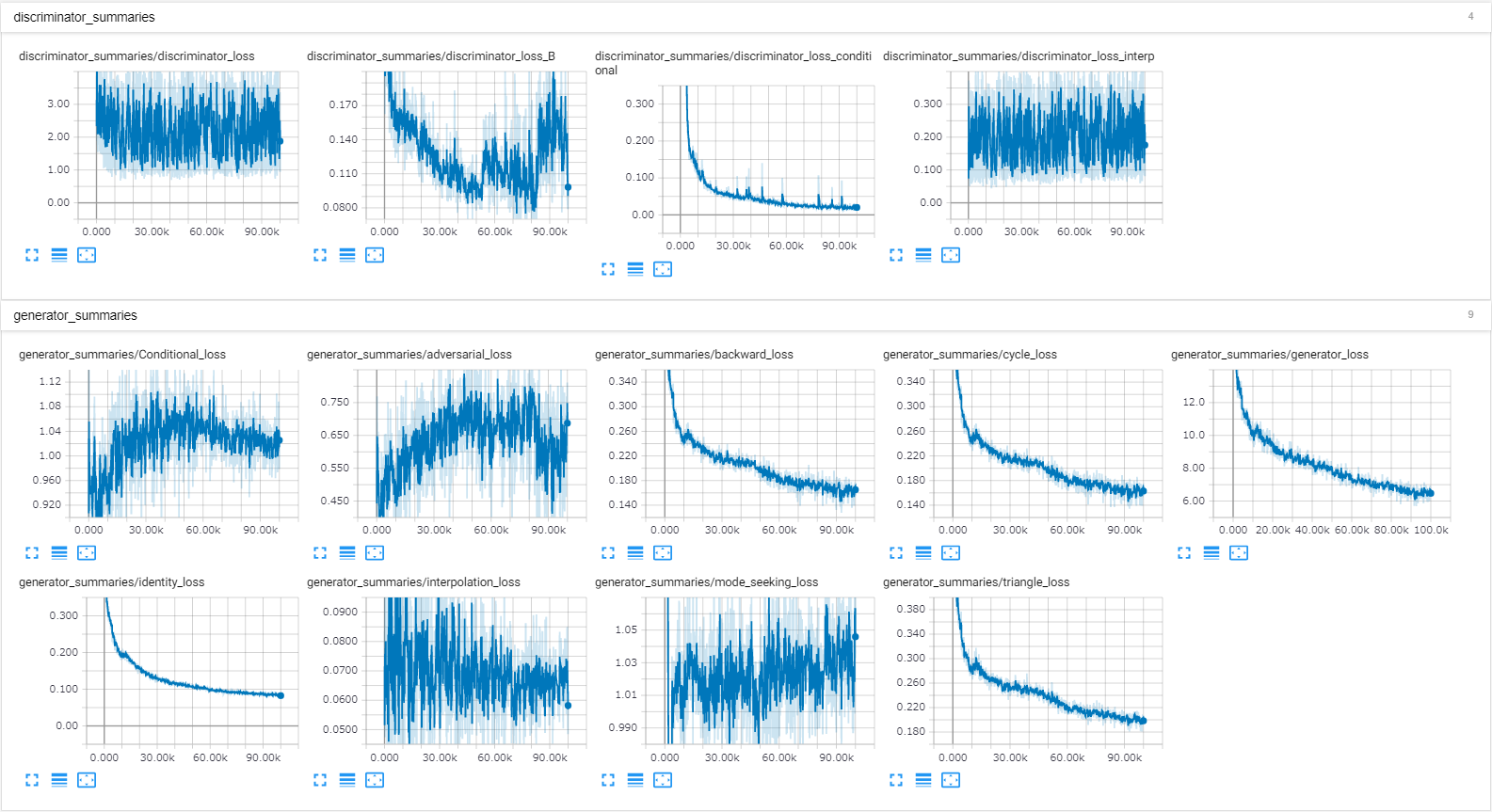
この条件のもと100,000steps学習させました(RTX2070で約62時間)。その結果80,000stepsを過ぎたあたりで変換が上手くいかなくなったため、本稿ではこれ以降80,000steps学習させたモデルを使用して評価を行います。下の図はTensorBoardによるLossのグラフです。80,000stepsあたりでDiscriminator側のAdversarial lossが急上昇(Generator側は急降下)しているのが分かります。
音声の生成と評価
生成された音声をGithub上に置きます。
YouTubeでも視聴できるようにしました。
音声の再構築
学習したニューラルネットは正規化されたMCEPsのみを変換するモデルとなっており、これとその他の統計量を用いてpyWorldによって再度音声へ変換しています。以下にドメインAからドメインBへ補間率${\alpha}$で変換するときの変換フローを記述します。
- wavを読み込む。
- 読み込んだwavからpyWorldによって$f_{o_A}$, $sp_A$, $ap_A$(非周期性指標)を求める。
- $f_{o_A}$を以下の式で変形する。$\mu_{f_{o_{\alpha}}}$や${\sigma_{f_{o_{\alpha}}}}$の算出は線形補間を用いる(標準偏差は一度分散に戻した方が良いか要検証)。
$$
\mu_{f_{o_{\alpha}}}=(1-{\alpha})\mu_{f_{o_A}}+{\alpha}\mu_{f_{o_B}}
$$
$$
{\sigma_{f_{o_{\alpha}}}}=(1-{\alpha})\sigma_{f_{o_A}}+{\alpha}\sigma_{f_{o_B}}
$$
$$
f_{o_\alpha}=\frac{f_{o_A}-\mu_{f_{o_A}}}{\sigma_{f_{o_A}}}{\sigma_{f_{o_{\alpha}}}}+\mu_{f_{o_{\alpha}}}
$$ - $sp_A$をノーマライズする。
$$
sp_{A_{norm}}=\frac{sp_A-\mu_{sp_A}}{\sigma_{sp_{A}}}
$$ - ニューラルネットに$sp_{A_{norm}}$を推論させる。
$$
sp_{{\alpha}_{norm}}=G({sp}_{A_{norm}}, {\alpha}v_{ab})
$$ - $sp_{{\alpha}_{norm}}$をデノーマライズする。例によって平均、標準偏差は線形補間を用いる。
$$
\mu_{sp_{{\alpha}}}=(1-{\alpha})\mu_{sp_{A}}+{\alpha}\mu_{sp_{B}}
$$
$$
{\sigma_{sp_{{\alpha}}}}=(1-{\alpha})\sigma_{sp_{A}}+{\alpha}\sigma_{sp_{B}}
$$
$$
{sp_{\alpha}}={\mu_{sp_{{\alpha}}}}+{\sigma_{sp_{{\alpha}}}}{sp_{{\alpha}_{norm}}}
$$
$$$$
7. 求められた$f_{o_\alpha}$,${sp_{\alpha}}$,$ap_A$からWorldによって音声を再合成する。非周期性指標$ap_A$は元の物を使うことに注意してください。
8. 必要に応じて音量を正規化し書き出す。
以上になります。
主観的評価
定量的評価のやり方が分からないので筆者の独断で評価を行います(問題)。
男性話者(jvs042, jvs054)への変換はどの話者からもある程度上手くいっていると思います。一方で女性話者(jvs010, jvs016)への変換は同性別間での変換はともかく異性別間での変換精度が低くjvs010への変換で特に顕著に表れています。またモーフィングについても結構微妙で$f_o$が変わってるだけじゃない?みたいな結果になっているものもあります。異性別間だとモーフィングしていることが分かりますが、自然性は低めに感じます。
まとめ
本稿ではRelGAN-VMを提案し声質変換及び声質モーフィングの実験を行いました。男性話者への変換は既存手法に対しても遜色ないものができたと自負していますが、男性話者から女性話者への変換、特に高い声への変換の精度はあまり高くなりませんでした。先行研究としてStarGAN-VC2で声質モーフィングが提案されており論文に書くには少し足りず、だからと言って捨てるのも勿体ないと思いQiitaに投稿する運びとなりました。美少女になるのは難しい。
Future works
本稿では話者間の声質のみを変換しました。例えば声優統計コーパスでは3人の話者が3種の感情によって読み上げられた9種類のデータセットが公開されています。これを学習させれば話者の声質のみならず感情もモーフィングさせたりとできるかもしれません。また、本実装のネットワーク構造や損失関数、ハイパパラメータもまだ完全なものとは言えず改良の余地があると思います。今後もより高性能な声質変換モデルについて検討していきたいと思います。
声質変換における注意
いい話題ではないですが個人の声にも権利があります。例えば声質変換を用いて他人の声になりすまし無断で商用利用や悪用をした場合、プライバシー侵害、著作権侵害として厳重に罰せられます。本実装を用いて他人の声になることはもちろん自由ですが、著作権的な処理がされていない音声データを使用する際には個人利用にとどめてください。非商用でも不特定多数の人が閲覧できる場合はグレーとなるので注意が必要です。たとえば本実験で使用したJVSコーパスは以下のように使用条件が記されています。
__ テキストデータはJSUTコーパスから来ており,そのライセンス情報はJSUTコーパスに記述されております.タグ情報は,CC-BY-SA 4.0 でライセンスされております.音声データは,以下の場合に限り使用可能です.
アカデミック機関での研究
非商用目的の研究(営利団体での研究も含む)
個人での利用(ブログなどを含む)
営利目的の利用を希望される場合,下記をご覧ください.この音声データの再配布は認められていませんが,あなたのウェブページやブログなどでコーパスの一部(例えば,10文程度)を公開することは可能です.__
また本実装を使用し、声質変換を行ったことによって発生した事故に対して筆者は一切の責任を負いません。
謝辞
本稿を投稿するにあたって助言をいただいた研究室の方々、特にるぎう君にはWorldに関する技術的な面で多くの意見をいただき、誤った情報を修正することができました。彼の要求レベルに到達するにはまだまだ精進が足りませんが良い勉強になりました。また明快な記事や論文、実装、そしてライブラリをアップロードされている方々、有用なデータセットを公開している研究室の方々に感謝の意を申し上げます。本稿に不備があるとすればそれはすべて私の責任です。
反省
卒論書かずに何やってんだ俺orz