
論文紹介・画像引用
2019.3.13提出
https://arxiv.org/pdf/1903.05628v1.pdf
本研究の成果
・モード崩壊に対処するための正則化項(本研究提案・後述)を目的関数に追加することで、
conditional GANs(cGANs)での多様な画像生成を可能にした
・正則化項は潜在変数間の距離に対する生成画像間の距離の比率を最大化することを目的としたもの
(「Mode collapseとMode seeking」の章の図と「Mode Seeking GANs」の章の図を見れば直感的な理解ができるはず)
・正則化項は様々なcGANに適用できる
・カテゴリ生成・image-to-image・text-to-imageの3つの条件付き画像生成を行ったが、
どのタスクでも画像の質を落とすことなく多様性の向上を実現した
これまでのconditional GANの問題点と改善
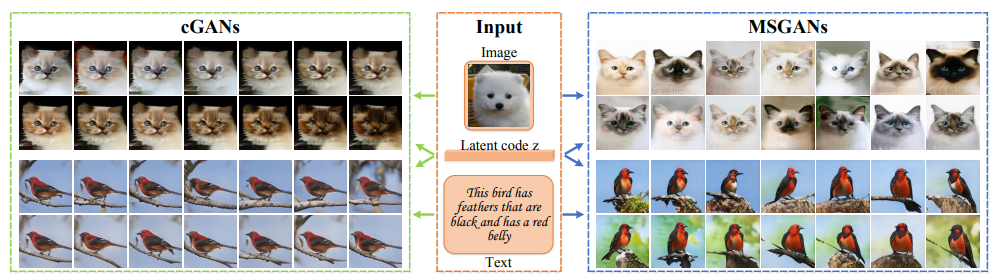
(左図:cGANs)
これまでのcGANsはcondition情報(ラベル・画像・テキスト)を重視する一方で、多様性を出す役割のある潜在変数z(ノイズベクトル)を無視していたため、同じような画像を生成してしまう傾向があった
condition情報は出力画像に関しての構造的な事前情報が多く、潜在変数よりも高次元のため重視されやすい
(右図:MSGANs(Mode-Seeking GANs))
これまでのcGANsに本研究提案の正則化項を目的関数に追加したものをMSGANsと呼ぶ
多様な画像を生成することができている
Mode collapseとMode seeking
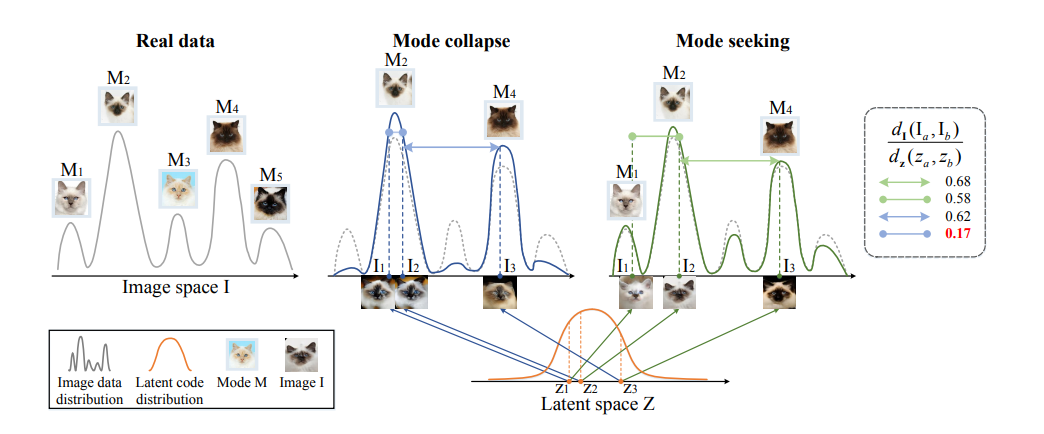
画像の分布(左1:Real data)には多様な画像(モード)があるが、モード崩壊(左2:Mode collapse)が起こるとGeneratorは多様性のない生成をしてしまう
Mode collapse
z1とz2という近いけれど異なる潜在変数を使っているにも関わらず、生成される画像は同じモード(似た画像)になってしまっている
Mode seeking
z1とz2という近いけれど異なる潜在変数を使っていることを上手く反映しているため、異なるモードの画像を生成できている
=潜在変数の変化に対応して生成画像も変化している
多様性評価のための比率
$$\frac{d_I(I_a,I_b)}{d_z(z_a,z_b)}$$
上図の1番右にある分数について
$d_I(I_a,I_b)$:生成画像$I_a$と生成画像$I_b$の間の距離
$d_z(z_a,z_b)$:潜在変数$z_a$と潜在変数$z_b$の間の距離
距離の比率を計算することによって
潜在変数の距離の変化が生成画像のモードの変化に対応しているかがわかる
・Mode collapse(青線)は低い値になっている(0.17)
これは潜在変数を変化させても画像のモードが変化していないことを意味している
潜在変数間の距離に対して画像のモードが変化していない=画像間の距離が近い=上記の分子が小さい値になる
・Mode Seeking(緑線)は青線よりも大きい値になっている(0.58)
潜在変数間の距離に対して画像のモードが変化している=画像間の距離が遠い=上記の分子が大きい値になる
Mode Seeking GANs
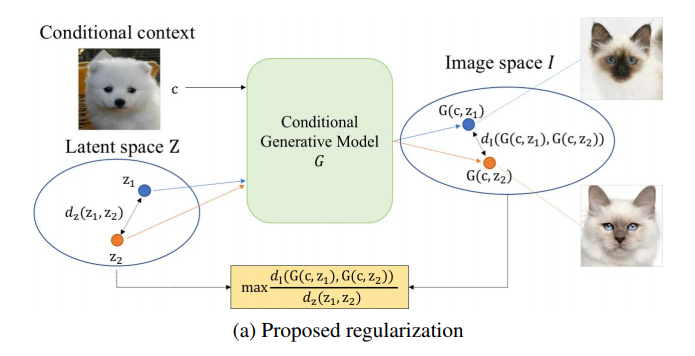
モード崩壊を軽減するために以下のmode seeking正則化項をこれまで通りのcGANsの目的関数に加える
$$L_{ms}=\max_G(\frac{d_I(G(c,z_1),G(c,z_2))}{d_z(z_1,z_2)})$$
潜在変数間の距離に対する生成画像間の距離の比率を最大化することを目的としている
「Mode collapseとMode seeking」の章で紹介した分数よりも文字が多くなっているが、内容は全く同じ
分子:生成画像①(condition情報$c$と潜在変数$z_1$から生成)と生成画像②(condition情報$c$と潜在変数$z_2$から生成)の距離
分母:潜在変数$z_1$と潜在変数$z_2$の距離
MSGANsの目的関数
$$L_{new}=L_{ori}+\lambda_{ms}L_{ms}$$
MSGANsの目的関数は上記のようになる
$L_{ori}$:元々cGANsで使っていた目的関数(下記詳細)
$\lambda_{ms}$:項のバランスをとるためのもの・どれほど正則化を強くするかを調整する
$L_{ms}$:上述したもの
①カテゴリ情報を条件にした画像生成の場合
例)犬の画像を生成
$$L_{ori}=E_{c,y}[\log{D(c,y)}]+E_{c,z}[\log{(1-D(c,G(c,z)))}]$$
$C$:クラスラベル
$y$:本物画像
$z$:潜在変数
第1項
本物画像を正しく本物と識別できるか
第2項
クラスラベルと潜在変数からできた生成画像を正しく偽物と識別できるか
②image-to-imageの場合
例)グレイスケール→カラーの画像変換(ペア画像がある場合)
$$L_{ori}=L_{GAN}+E_{x,y,z}[||y-G(x,z)||_1]$$
$x$:入力画像
$y$:目的ドメインの画像
$z$:潜在変数
第1項
$L_{GAN}$:普通のGANの目的関数
・discriminatorは本物は本物、偽物は偽物として識別できればいい
・生成された画像が本物っぽい画像として成り立っているかを評価
$L_{GAN}=E_{x,y}[\log{D(x,y)}]+E_{x,z}[\log{(1-D(x,G(x,z)))}]$
第2項
・生成された画像が目的通りに変換されているかを評価
正則化項の適用
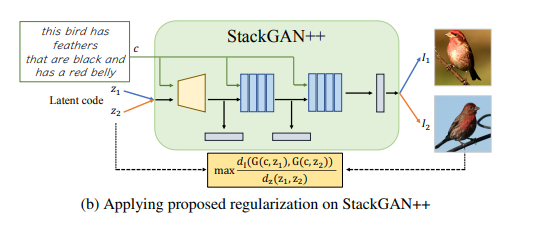
・どんなcGANsにも適用することができる
・text-to-imageで使われるStackGAN++のような木構造があるモデルに対しても適用できる
上図が示すように、モデルの構造が変わっているだけで
潜在変数間の距離に対する生成画像間の距離の比率を最大化することを目的としていることは変わらない
正則化項の効果を検証
距離の指標($d_I,d_z$)として$L_1$ノームを使う
$\lambda_{ms}=1$に設定
評価指標
FID
・生成画像の質を評価
・生成画像分布と本物画像分布の距離を計測
・小さい値=高品質画像
LPIPS
・生成画像の多様性を評価
・生成画像間の平均特徴距離を計測
・大きい値=生成画像に多様性がある
NDB・JSD
・生成画像分布と本物画像分布の類似性を計測
・生成モデルが多様な画像を生成しているかを評価する指標
①本物画像(訓練画像)に対してK-meansをすることで、本物画像の分布をビンとして表す
②生成画像を同じようなモードを表している本物画像のビンに割り当てる
③本物画像と生成画像のビン比率を計算して、生成画像と本物画像の分布の違いを評価する
NDBとJSDが小さい値=多様なモードを生成できているため、生成画像分布が本物画像分布に近い
カテゴリ生成
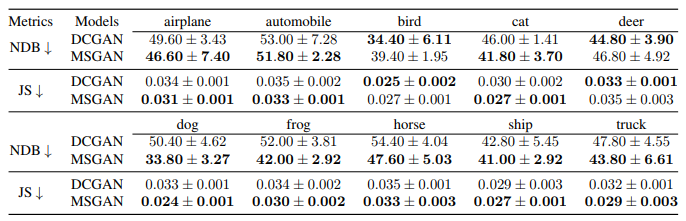

・クラスラベルを条件として様々なカテゴリの画像を生成する
・CIFAR-10データセット
・正則化項をDCGANに適用
・MSGANは画像の質を落とすことなく(FIDが小さくなっている)ほとんどのクラスでモード崩壊を軽減することができている(NDBとJSが小さくなっている)
image-to-image
・ある画像を他のドメインの画像に転換する
例)犬→猫 冬→夏
・これまでは1対1の変換(ある犬を変換しても限られたモードの猫のみ)になっていたがMSGANを使うことで1つの画像に対して多様な変換ができるかがポイント
ペア画像があるとき

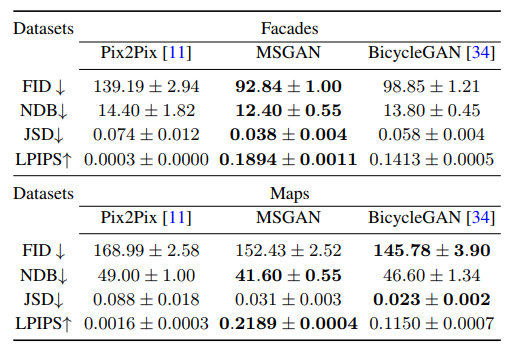
Pix2Pixをベースラインに、BicycleGANを比較対象とする
generatorとdiscriminatorのアーキテクチャはBicycleGANのものを使う
正則化項を加えたこと(MSGAN)で多様な画像が生成できている
ペア画像がないとき
多様な画像を生成できるDRITをベースラインとする
形状保存が求められる季節変化のデータセットと形状変化が求められる犬猫のデータセットを使う
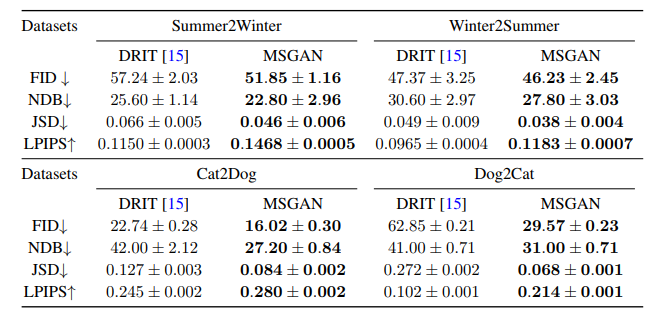
・どちらのデータセットでもすべての指標でDRITを上回ることができている
・特に犬猫の変換では、MSGANが多様性を大きく改善していることが数値からわかる
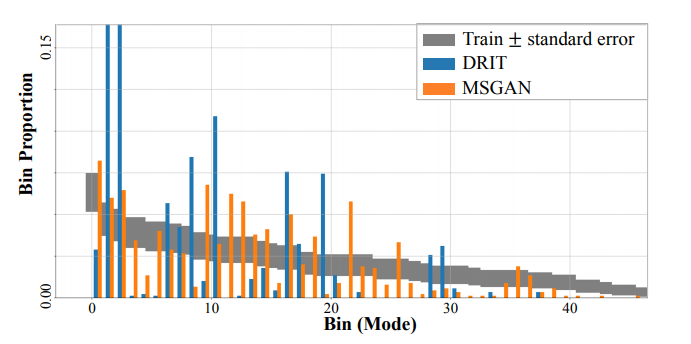
・上図は犬から猫への変換のビン比率を可視化したもの
・DRITは限られたモード(1・2・8・10・16・19)の比率が大きいが、MSGANは様々なモードを生成することができている
=MSGANの方が本物画像の分布に上手く近似した生成

MSGANは画像の質を落とすことなく多様な画像を生成することができていることが上図からわかる
text-to-image
・文章を入力として条件付けて、その文章を表す画像を生成する
・StackGAN++に正則化項を加える
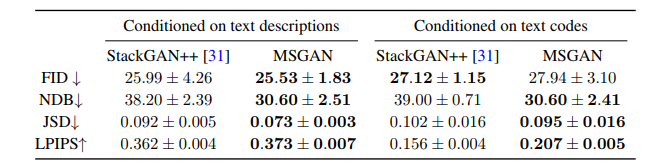
2つの状況でStackGAN++とMSGANを比較する
①Conditioned on text descriptions
テキストを表すテキストコードを固定しないで生成する
この場合、テキストコードも出力画像の多様性に影響を与える
②Conditioned on text codes
テキストコードを固定して生成する
この場合、テキストコードによる出力画像への影響はなくなる
・MSGANは画像の質を保ちながら多様性を向上させることができている
・Conditioned on text codesではテキストコードの影響がないため、数値の向上は潜在変数がちゃんと生成に使われていることを意味している

StackGAN++では文章に対して同じような画像を生成しているが
MSGANでは潜在変数が上手く使われているため、鳥の見た目・向き・背景が多様に表現されている
MSGANの潜在空間でinterpolation

ある2つの潜在変数間でinterpolationをして、それに対応する画像を生成した結果
生成モデルがちゃんと潜在変数を画像生成に使えているかを確認することができる
潜在変数を動かしても同じモードの画像が生成されていたらモード崩壊と考えられる
上図のように、MSGANでは潜在変数の変化とともに画像も徐々に変化している
まとめ
・cGANsでのモード崩壊に対処するためのmode seeking正則化項を提案
・generatorが多様なモードを生成できるようにするために、潜在変数間の距離に対する生成画像間の距離の比率を最大化することを目的とした正則化項を加える
・正則化はネットワーク構造を変えたりすることなく簡単に既存のcGANsに適用することができる
・既存のcGANsに正則化項を加えることで、すべてのタスク(カテゴリ生成・image-to-image・text-to-image)において画像の質を落とすことなく多様性を向上させることができる
参考・関連論文
conditional GAN
https://www.foldl.me/uploads/2015/conditional-gans-face-generation/paper.pdf
image-to-image, pix2pix
https://arxiv.org/pdf/1611.07004v3.pdf
BicycleGAN
https://arxiv.org/pdf/1711.11586.pdf
DRIT
https://arxiv.org/pdf/1808.00948.pdf
StackGAN++
https://arxiv.org/pdf/1710.10916v3.pdf