はじめに
こんにちはDNA1980と申します。
最近GNN(Graph Neural Network)流行ってますよね。
私も流れに乗ってグラフを扱いたいのですが、世の中に存在するグラフデータってよく知らないものが多いじゃないですか。分類したところで何やってるかわからん、、、
別にネットワークのように最初からグラフ構造を取っていないものでもグラフに落とし込めるのであればGNNを適用できるんじゃないかと思い、みんな大好きMNISTに適用してみました。
GNNについてよくわからない方はQiita上でも詳しく書いている方がいらっしゃるのでこちらを読むことをおすすめします
GNNまとめ(1): GCNの導入
今回使用したコードや作成したデータセットはこちらのGithub上にて公開しています。
環境
Python 3.7.6
PyTorch 1.4.0
PyTorch geometric 1.4.2
今回はGNNを扱うライブラリとしてPyTorch geometricを用いました。
データセットの作成
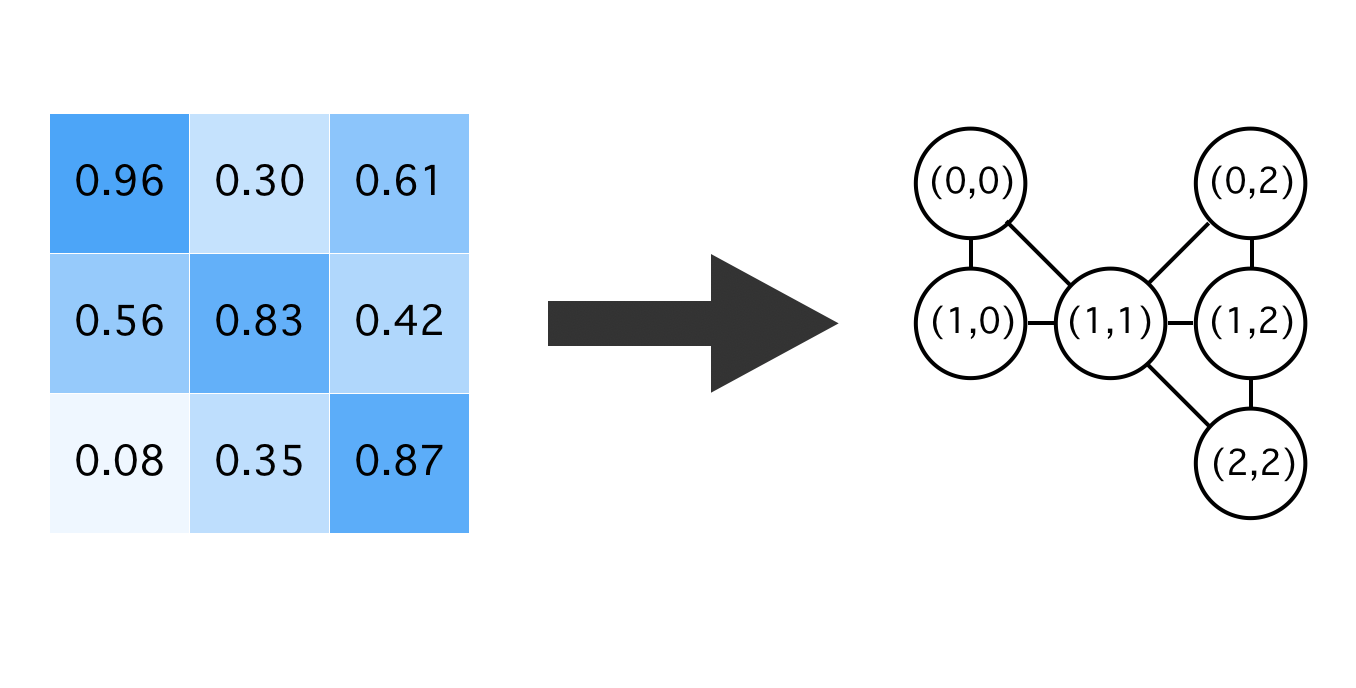
2次元画像であるMNISTにGNNを適用するにはグラフにする必要があります。
・0.4以上の明るい画素をすべてノードとする
・元の画像上で8近傍にノードが存在すれば辺を張る
・各ノード上の特徴量としてはx座標,y座標の2次元量を用いる
以上のルールの元、変換を行いました。
(作成が手間だったので今回はtrain用の60000データのみを用いています。)
イメージはこんな感じです
今回データセット作成に用いたコードはこちらです。(最初は24近傍に辺を張る予定だったので余計にパディングされていますが気にしないでください)
そんなに数もないので愚直に実装しましたが、bitboard等を使用すれば速くなりそうです。
# gzipファイルからMNISTデータを呼び出して2次元の形にする
data = 0
with gzip.open('./train-images-idx3-ubyte.gz', 'rb') as f:
data = np.frombuffer(f.read(), np.uint8, offset=16)
data = data.reshape([-1,28,28])
data = np.where(data < 102, -1, 1000)
for e,imgtmp in enumerate(data):
img = np.pad(imgtmp,[(2,2),(2,2)],"constant",constant_values=(-1))
cnt = 0
for i in range(2,30):
for j in range(2,30):
if img[i][j] == 1000:
img[i][j] = cnt
cnt+=1
edges = []
# y座標、x座標
npzahyou = np.zeros((cnt,2))
for i in range(2,30):
for j in range(2,30):
if img[i][j] == -1:
continue
#8近傍に該当する部分を抜き取る。
filter = img[i-2:i+3,j-2:j+3].flatten()
filter1 = filter[[6,7,8,11,13,16,17,18]]
npzahyou[filter[12]][0] = i-2
npzahyou[filter[12]][1] = j-2
for tmp in filter1:
if not tmp == -1:
edges.append([filter[12],tmp])
np.save("../dataset/graphs/"+str(e),edges)
np.save("../dataset/node_features/"+str(e),npzahyou)
分類にかける
今回は
・GCNを6層と全結合層を2層
・OptimizerはAdam(パラメータは全てデフォルト)
・ミニバッチサイズは100
・epoch数は150
・活性化関数にはReLUを使用
・全60,000データのうち50.000データをtrain用に、残りをtest用に使用
として学習を行いました。
モデル
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = GCNConv(2, 16)
self.conv2 = GCNConv(16, 32)
self.conv3 = GCNConv(32, 48)
self.conv4 = GCNConv(48, 64)
self.conv5 = GCNConv(64, 96)
self.conv6 = GCNConv(96, 128)
self.linear1 = torch.nn.Linear(128,64)
self.linear2 = torch.nn.Linear(64,10)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.conv1(x, edge_index)
x = F.relu(x)
x = self.conv2(x, edge_index)
x = F.relu(x)
x = self.conv3(x, edge_index)
x = F.relu(x)
x = self.conv4(x, edge_index)
x = F.relu(x)
x = self.conv5(x, edge_index)
x = F.relu(x)
x = self.conv6(x, edge_index)
x = F.relu(x)
x, _ = scatter_max(x, data.batch, dim=0)
x = self.linear1(x)
x = F.relu(x)
x = self.linear2(x)
return x
学習部分
data_size = 60000
train_size = 50000
batch_size = 100
epoch_num = 150
def main():
mnist_list = load_mnist_graph(data_size=data_size)
device = torch.device('cuda')
model = Net().to(device)
trainset = mnist_list[:train_size]
optimizer = torch.optim.Adam(model.parameters())
trainloader = DataLoader(trainset, batch_size=batch_size, shuffle=True)
testset = mnist_list[train_size:]
testloader = DataLoader(testset, batch_size=batch_size)
criterion = nn.CrossEntropyLoss()
history = {
"train_loss": [],
"test_loss": [],
"test_acc": []
}
print("Start Train")
model.train()
for epoch in range(epoch_num):
train_loss = 0.0
for i, batch in enumerate(trainloader):
batch = batch.to("cuda")
optimizer.zero_grad()
outputs = model(batch)
loss = criterion(outputs,batch.t)
loss.backward()
optimizer.step()
train_loss += loss.cpu().item()
if i % 10 == 9:
progress_bar = '['+('='*((i+1)//10))+(' '*((train_size//100-(i+1))//10))+']'
print('\repoch: {:d} loss: {:.3f} {}'
.format(epoch + 1, loss.cpu().item(), progress_bar), end=" ")
print('\repoch: {:d} loss: {:.3f}'
.format(epoch + 1, train_loss / (train_size / batch_size)), end=" ")
history["train_loss"].append(train_loss / (train_size / batch_size))
correct = 0
total = 0
batch_num = 0
loss = 0
with torch.no_grad():
for data in testloader:
data = data.to(device)
outputs = model(data)
loss += criterion(outputs,data.t)
_, predicted = torch.max(outputs, 1)
total += data.t.size(0)
batch_num += 1
correct += (predicted == data.t).sum().cpu().item()
history["test_acc"].append(correct/total)
history["test_loss"].append(loss.cpu().item()/batch_num)
endstr = ' '*max(1,(train_size//1000-39))+"\n"
print('Test Accuracy: {:.2f} %%'.format(100 * float(correct/total)), end=' ')
print(f'Test Loss: {loss.cpu().item()/batch_num:.3f}',end=endstr)
print('Finished Training')
# 最終結果出力
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
data = data.to(device)
outputs = model(data)
_, predicted = torch.max(outputs, 1)
total += data.t.size(0)
correct += (predicted == data.t).sum().cpu().item()
print('Accuracy: {:.2f} %%'.format(100 * float(correct/total)))
結果
なんと、**97.74%**という正解率(accuracy)になりました。
lossとtest accuracyの変化は以下。
最後少し過学習気味ですがきれいに学習が進んでいるのがわかります。
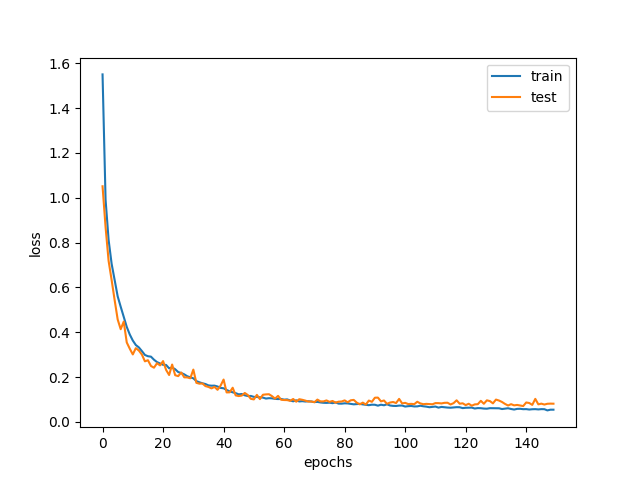
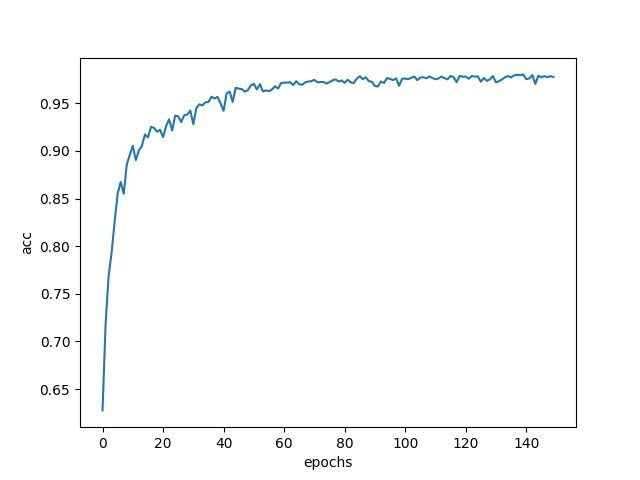
データ変形時に結構情報が落ちている気がしたのですが、MLP(参考)よりは良く分類ができていたので驚きです。
特徴量として画素の明るさではなく座標を用いただけでもこれだけ分類できているという点は興味深いですよね。
それではみなさんも良いGNNライフを!