はじめに
こんにちは。機械学習初心者の恐竜です。
勉強したことのアウトプットとして何かやらないとな~と思いつつもなかなか手が出なかったときに、このイベントが開催されていたので投稿してみました。
初めての投稿記事&英語論文解説なので、至らぬ点が多くあると思います。ミスリード等あればご指摘いただけると幸いです。
この記事の目的
この記事ではSPADE~PaDiM~PatchCoreと続く異常検知手法の原点とされる論文「Deep Nearest Neighbor Anomaly Detection」の内容紹介をします。
DN2とは
・論文:Deep Nearest Neighbor Anomaly Detection[2020/02]
シンプルな異常検知手法としての最近傍法(K-NN)と、特徴量の抽出器として事前学習モデルを利用した手法。
従来の転移学習や自己教師あり学習と比較して、少ない学習枚数で精度・学習時間の短縮・データノイズに対する高いロバスト性を得ています。
結論
結果として、比較している従来手法の精度が62~90%に対して、92.5%の精度を達成しています。(データセットはCifar10)
画像の特徴量を上手く分けることで、高い精度が得られるとのこと。
利点
驚きなのはこの精度を追加学習無で達成しているということです。
少ない学習データでも高い汎化性能が得られていることを下記図で示しています。
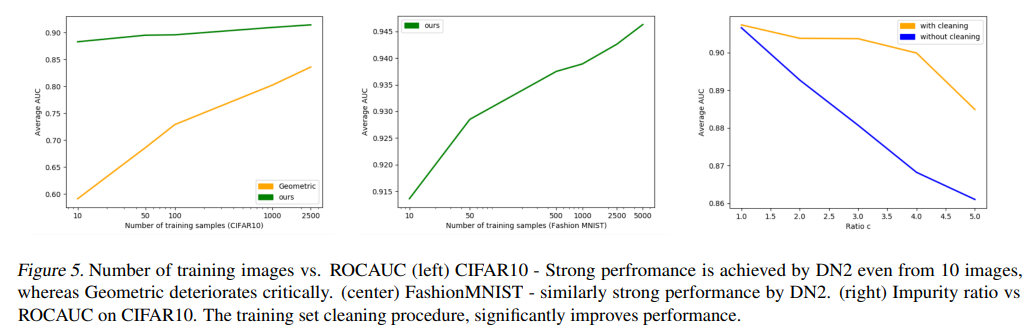
左図の緑色が提案手法のDN2です。学習画像数が10枚でもかなり高い精度となっています。
また事前学習モデルと類似性の無い画像でも応用が可能とのことで、論文中では顕微鏡画像や航空写真に対しても異常検知できることを実験で検証しています。
手法のキモ
なぜDN2は高い精度が得られるのかを説明するために、CIFAR10の画像データの特徴量を可視化した図を用いています。上が飛行機、下が自動車のデータです。
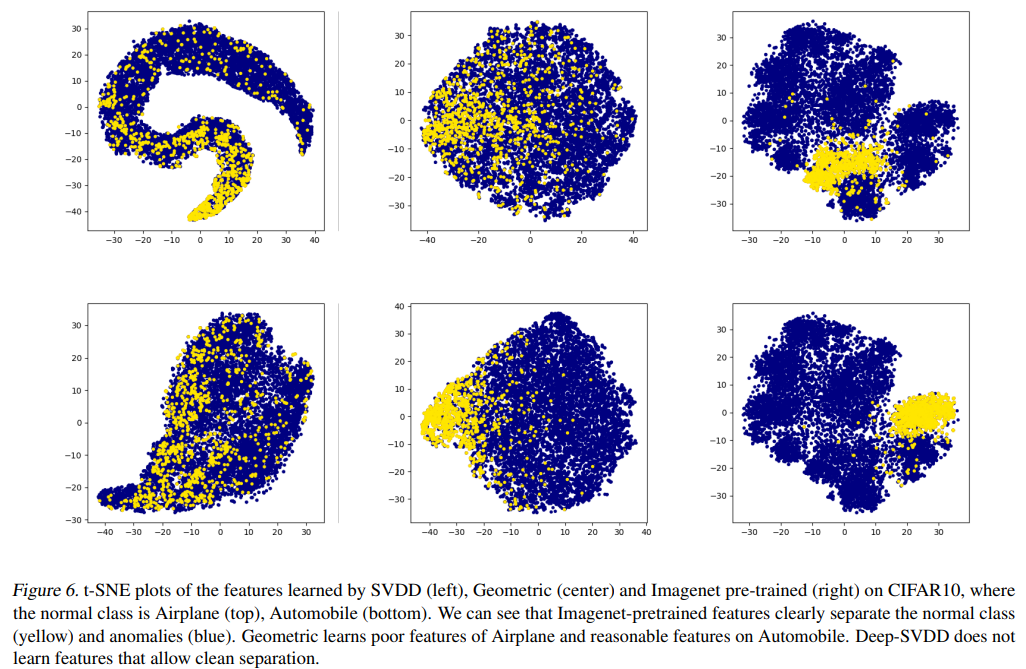
一番右の上下2つがDN2の結果です。正常データは黄色、異常データは青色で表示されています。
見てわかるように、DN2は正常データが固まっていて特徴量が上手く抽出されています。
この正常データの密度が高いことがK-NNの精度向上の理由だと論文で述べています。
おわりに
SPADE系の出発点ともいえる「Deep Nearest Neighbor Anomaly Detection」について解説しました。
ここから引用されていく論文の紹介記事も書いていければと思います。