1 はじめに
1.1 経緯
このまえまで、以下の記事で手書き数字(MNIST)を扱っていましたが、
https://qiita.com/Cyber_Hacnosuke/items/9b6f561632a56598bb56
https://qiita.com/Cyber_Hacnosuke/items/e4c62d90b776ea3debf7
数字は種類が少ないし、簡単だったのでやってみようかなぁ~ということでやっていきます。
1.2 やること
ETLはMNISTと違って、あらかじめ学習用データになっておらず、APIもなくてその上、ダウンロードしたファイルがバイナリデータということもあって解説用サイトも少ないです。ですが種類が多くて、カタカナ、ひらがな、漢字まであるというかなり夢の広がるものです。
今回はETL7のひらがなとETL8Bの漢字とひらがな合同を使っていきます。
ですが極力説明していきますので参考にしてみてください。
2 ETL7から学習用データへ
2.1 ダウンロード
http://etlcdb.db.aist.go.jp
こちらからDownloadをおして
- 名前
- メールアドレス
- 所属
- 国
- 使用目的
使用目的は、個人的な研究などとしとけばいいでしょう。特に厳しい審査があるわけでもないので、メールが送られてくるのを待ちましょう。しばらくするとメールが来てダウンロードパスワードとURLが送られてきます。開いて、パスワードを入力すればダウンロードページがでてきます。すぐさまブックマークにしてETL7をクリック。ダウンロードできます。zipを解凍して中を開いてください。5つほど拡張子のないファイルがあると思います。
2.1 バイナリから画像にする
さっきも言った通りこのままではINFOを除いた4つのファイルがバラバラですし、バイナリデータで理解不能です。まず、INFOを消しましょう。
AnacondaのVisual Studio Codeでもいいですし、Driveに入れてGoogleColaboratoryでもいいがソースコードを書きます。
# ETL1 ETL7用
import struct
from PIL import Image, ImageEnhance
import glob, os
RECORD_SIZE = 2052
# ひらがな画像集を保存するディレクトリ
outdir = "ETL7-img/"
if not os.path.exists(outdir): os.mkdir(outdir)
# ETL7ディレクトリ内部の4個の分割データを読み込む
files = glob.glob("ETL7/*")
fc = 0
for fname in files:
fc = fc + 1
print(fname) # ETL7の分割ファイル名
# ETL7の分割ファイル名を開く
f = open(fname, 'rb')
f.seek(0)
i = 0
while True:
i = i + 1
# あいうえおのラベルと画像データの組を一つずつ読む
s = f.read(RECORD_SIZE)
if not s: break
# バイナリデータなのでPythonが理解できるように
r = struct.unpack('>H2sH6BI4H4B4x2016s4x', s)
# ひらがなの画像として取り出す
iF = Image.frombytes('F', (64, 63), r[18], 'bit', 4)
iP = iF.convert('L')
code_jis = r[3]
dir = outdir + "/" + str(code_jis)
if not os.path.exists(dir): os.mkdir(dir)
fn = "{0:02x}-{1:02x}{2:04x}.png".format(code_jis, r[0], r[2])
fullpath = dir + "/" + fn
#if os.path.exists(fullpath): continue
enhancer = ImageEnhance.Brightness(iP)
iE = enhancer.enhance(16)
iE.save(fullpath, 'PNG')
print("ok")
okとでたら終了です。
実行前のファイルツリー↓
make_img.py(実行ファイル)
/ETL7
ETL7LC_1
ETL7LC_2
ETL7SC_1
ETL7SC_2
/ETL7-img(作っといて)
実行後のファイルツリー↓
make_img.py(実行ファイル)
/ETL7
ETL7LC_1
ETL7LC_2
ETL7SC_1
ETL7SC_2
/ETL7-img
/166
....
/177
....
/178
....
.......
/223
....
ETL7-img内に166、177~223までのディレクトリが生成されその中に画像が生成されています。
166、177~223は文字コードです。
なお、このソースコードはETL1にも対応しています。
2.1 画像からラベルの付いた学習用データにする(pickle化)
画像だけではラベル(y)が付いていないので学習できません。そこでCSVやdatasetなど様々な形式のうち、pickleという形式にします。
# 使用するライブラリを読み込む
import numpy as np
import cv2
import matplotlib.pyplot as plt
import glob
import pickle
# 保存ディレクトリと画像サイズの指定
out_dir = "./ETL7-img" # ひらがな画像集のディレクトリ
im_size = 32 # 画像サイズ
save_file = out_dir + "/JapaneseHiragana.pickle" # 保存ファイル名と保存先
plt.figure(figsize=(9, 17))
# 出力画像を大きくする
# ひらがな画像集のディレクトリから画像を読み込み開始(ETL7内のディレクトリの名前リスト)
hiraganadir = list(range(177, 223+1)) #あいうえお--わの順序
hiraganadir.append(166) # を
result = []
for i, code in enumerate(hiraganadir):
img_dir = out_dir + "/" + str(code)
fs = glob.glob(img_dir + "/*")
print("dir=", img_dir)
# 画像64X63を読み込んでグレイスケールに変換し32X32に整形
for j, f in enumerate(fs):
img = cv2.imread(f)
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img = cv2.resize(img_gray, (im_size, im_size))
result.append([i, img])
# ひらがな画像一覧表示 10行X5列
if j == 3:
plt.subplot(11, 5, i + 1)
plt.axis("off")
plt.title(str(i))
plt.imshow(img, cmap='gray')
# ひらがなの「画像とラベル」のデータセットを保存
pickle.dump(result, open(save_file, "wb"))
plt.show()
読み込んだディレクトリが表示され、ひらがなが表示されて終了です。番号のラベルがしっかりとついています。
画像は63 × 64からim_size × im_sizeに変わっています。(上の例だと32 × 32)
2.3 学習させる
import numpy as np
import cv2, pickle
from sklearn.model_selection import train_test_split
import keras
from keras.models import Sequential
from keras.optimizers import RMSprop
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.layers.normalization import BatchNormalization
from keras.layers import Conv2D, MaxPooling2D
import matplotlib.pyplot as plt
# データファイルと画像サイズの指定
data_file = "ETL7-img/JapaneseHiragana.pickle"
im_size = 32
out_size = 48 # アーンまでの文字の数
im_color = 1
in_shape = (im_size, im_size, im_color)
# 保存した画像データ一覧を読み込む
data = pickle.load(open(data_file, "rb"))
# 画像データを0-1の範囲に直す
y = []
x = []
for d in data:
(num, img) = d
img = img.astype('float').reshape(im_size, im_size, im_color) / 255
y.append(keras.utils.np_utils.to_categorical(num, out_size))
x.append(img)
x = np.array(x)
y = np.array(y)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8, shuffle=True)
# モデル構築
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=in_shape))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(out_size))
model.add(Activation('softmax'))
# コンパイル
model.compile(
loss='categorical_crossentropy',
optimizer= RMSprop(),
metrics=['accuracy'])
hist = model.fit(
x_train, y_train,
batch_size=64, epochs=50,verbose=1,
validation_data=(x_test, y_test))
score = model.evaluate(x_test, y_test, verbose=1)
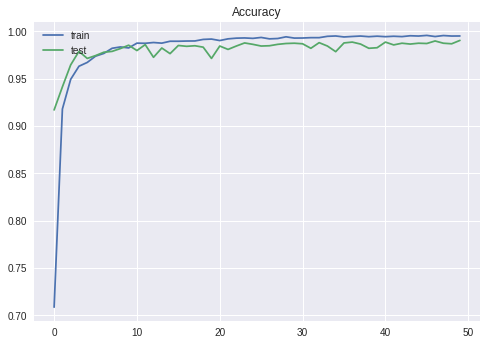
print("正解率 ", score[1], "loss ", score[0])
plt.plot(hist.history['acc'])
plt.plot(hist.history['val_acc'])
plt.title('Accuracy')
plt.legend(['train', 'test'], loc = 'upper left')
plt.show()
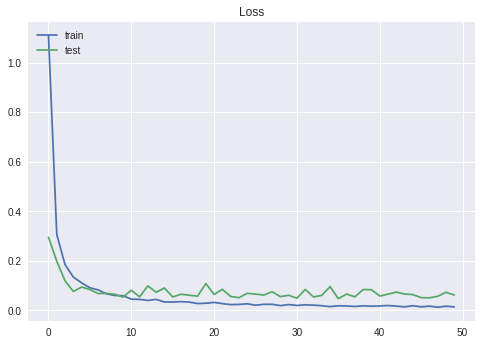
plt.plot(hist.history['loss'])
plt.plot(hist.history['val_loss'])
plt.title('Loss')
plt.legend(['train', 'test'], loc = 'upper left')
plt.show()
model.save('ETL7-model.h5')
model.save_weights('ETL7-weights.h5')
モデルはVGG like的な何かです。モデルを保存して終了です。
3. ETL8Bを用いてひらがな、漢字の両方を判定する(ETL8B版)
# ETL8B 用
import struct
from PIL import Image, ImageEnhance
import glob, os
RECORD_SIZE = 512
# 画像集を保存するディレクトリ
outdir = "ETL8B-img/"
if not os.path.exists(outdir): os.mkdir(outdir)
# ETL8Bディレクトリ内部の4個の分割データを読み込む
files = glob.glob("drive/My Drive/Colab Notebooks/ETL8B/*")
fc = 0
for fname in files:
fc = fc + 1
print(fname) # ETL8Bの分割ファイル名
# ETL7の分割ファイル名を開く
f = open(fname, 'rb')
f.seek(0)
i = 0
while True:
i = i + 1
# あいうえおのラベルと画像データの組をRECORD_SIZE byteずつ読む
s = f.read(RECORD_SIZE)
if not s: break
# バイナリデータなのでPythonが理解できるように
r = struct.unpack('>2H4s504s', s)
# 画像として取り出す
iF = Image.frombytes('1', (64, 63), r[3], 'raw')
iP = iF.convert('L')
code_jis = r[3]
dir = outdir + "/" + str(hex(r[1])[-4:])
if not os.path.exists(dir): os.mkdir(dir)
# fn = "{0:02x}-{1:02x}{2:04x}.png".format(code_jis, r[0], r[2])
fn = 'ETL9B_{}.png'.format((r[0]-1)%20+1)
fullpath = dir + "/" + fn
#if os.path.exists(fullpath): continue
enhancer = ImageEnhance.Brightness(iP)
iE = enhancer.enhance(16)
iE.save(fullpath, 'PNG')
print("ok")
ETL7と同じようにokと表示されたら終了です。
# 使用するライブラリを読み込む
import numpy as np
import cv2
import matplotlib.pyplot as plt
import glob
import pickle
# 保存ディレクトリと画像サイズの指定
out_dir = "./ETL8B-img" # ひらがな画像集のディレクトリ
im_size = 32 # 画像サイズ
save_file = out_dir + "/ETL8B.pickle" # 保存ファイル名と保存先
plt.figure(figsize=(9, 17)) # 出力画像を大きくする
# ひらがな画像集のディレクトリから画像を読み込み開始
files = os.listdir(out_dir)
files_dir = [f for f in files if os.path.isdir(os.path.join(out_dir, f))]
result = []
for i, code in enumerate(files_dir):
img_dir = out_dir + "/" + str(code)
fs = glob.glob(img_dir + "/*")
print("dir=", img_dir)
# 画像64X63を読み込んでグレイスケールに変換し32X32に整形
for j, f in enumerate(fs):
img = cv2.imread(f)
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img = cv2.resize(img_gray, (im_size, im_size))
result.append([i, img])
# ひらがな画像一覧表示 10行X5列
if j == 3:
plt.subplot(11, 5, i + 1)
plt.axis("off")
plt.title(str(i))
plt.imshow(img, cmap='gray')
# ひらがなの「画像とラベル」のデータセットを保存
pickle.dump(result, open(save_file, "wb"))
plt.show()
import keras
from keras.models import Sequential
from keras.optimizers import RMSprop
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.layers.normalization import BatchNormalization
from keras.layers import Conv2D, MaxPooling2D, Input
from keras.applications.vgg16 import VGG16
import matplotlib.pyplot as plt
# データファイルと画像サイズの指定
data_file = "ETL8B-img/ETL8B.pickle"
im_size = 32
out_size = 979 # アーンまでの文字の数
im_color = 1
in_shape = (im_size, im_size, im_color)
# 保存した画像データ一覧を読み込む
data = pickle.load(open(data_file, "rb"))
# 画像データを0-1の範囲に直す
y = []
x = []
for d in data:
(num, img) = d
img = img.astype('float').reshape(im_size, im_size, im_color) / 255
y.append(keras.utils.np_utils.to_categorical(num, out_size))
x.append(img)
x = np.array(x)
y = np.array(y)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, train_size=0.8, shuffle=True)
# モデル構築
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=in_shape))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(128, (3, 3)))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(Conv2D(128, (3, 3)))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(BatchNormalization())
model.add(Dropout(0.5))
model.add(Dense(out_size))
model.add(Activation('softmax'))
# コンパイル
model.compile(
loss='categorical_crossentropy',
optimizer= 'adam',
metrics=['accuracy'])
hist = model.fit(
x_train, y_train,
batch_size=2048, epochs=20000,verbose=1,
validation_data=(x_test, y_test))
score = model.evaluate(x_test, y_test, verbose=1)
print("正解率 ", score[1], "loss ", score[0])
plt.plot(hist.history['acc'])
plt.title('Accuracy')
plt.legend(['train', 'test'], loc = 'upper left')
plt.show()
plt.plot(hist.history['loss'])
plt.title('Loss')
plt.legend(['train', 'test'], loc = 'upper left')
plt.show()
model.save('ETL8-model.h5')
model.save_weights('ETL8-weights.h5')
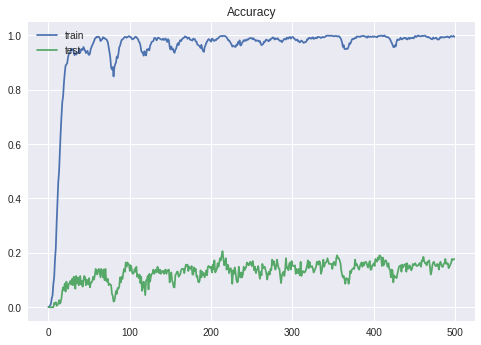
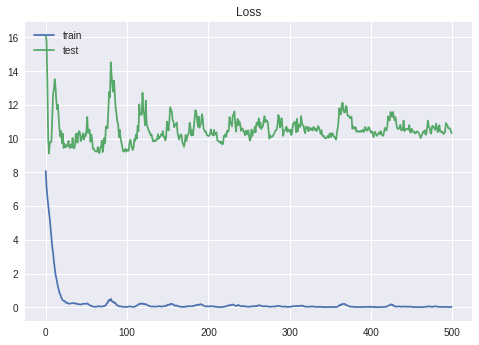
実はこれが問題で、ひらがなと漢字合わせて979文字あるため、出力次元数が979となってしまうのです。そうすると、trainでは100%出ているのにいざtestでやってみると10%前後ととても低い確率になってしまいます。20000回やればいけるそうですが、GoogleColaboratoryでは限界に達してしまいどうしようもない状態です。どなたか、高次元出力対応のモデル教えてくださるとありがたいです。
ちなみに限界↓