1.初めに
1.1
GoogleColaboratoryはさらっと流してメインはMNISTとGPUのすごさについて解説していきます。
2.GoogleColaboratoryについて
2.1勧める理由
これは神です。(異論認める)なぜそんなに勧めるのかというと、理由は主にしたの三つです。
- GoogleDriveと連携しているのでいつでもアクセスできる!
- 高性能GPUが無料!
- エラーは調べてくれる!
本当にそのままです。大きいのは二つ目。GPUが使用できればVGG likeもお手の物!すぐに実用化できます。
しかし制約もあるので、詳しくはほかを参考にしてください。
2.2使い方
簡単です。GoogleColaboratoryのサイトにアクセスしてください。
ログインして、ファイル→Python3の新しいノートブックで自動生成されます。自分のGoogleのMyDriveに以下のようなフォルダが生成されているとおもうですが、この中にファイルは保存されます。

セルごとに実行ができ、importは一個目のセル、ダウンロードは二つ目のセル...などと分けることができます。しかし、セルを編集したのち実行しなければ無効になります。変更したのにimportされない!ってこともしばしばあるので気を付けてください。また、これはGoogleのくせにドキュメントとは違って自動保存はされません。ctrl+cで保存してあげてください。またセルに!とかいてpipコマンドなどを実行できます。
2.3GPUはわずか4ステップ!
編集→ノートブックの設定→ハードウェア アクセラレータをNoneからGPUへ→保存
たったこれだけ。(GPUを使わなくても早い処理はGPUをオフにすることをお勧めしまふw)
ノートブックごとに決められているので、新しいノートブックを作ったら再設定してください。
3.【本題】MNISTをVGG likeで贅沢に
おまちかねのMNIST。MNISTのデータ確認は他を調べてください。モデル構築前までをずらぁ~っと。
import tensorflow as tf
from keras.datasets import mnist
from keras.utils import to_categorical
# 下のはあとで使うから置いといてあげて
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten, Conv2D, MaxPooling2D
# データセットのロード(トレーニング用とテスト用で分かれている)
(X_train, Y_train), (X_test,Y_test) = mnist.load_data()
image_rows = 28
image_cols = 28
image_color = 1 #グレースケールのこと
input_shape = (image_rows, image_cols, image_color)
out_size = 10
# データ整形
X_train = X_train.reshape(-1, image_rows, image_cols, image_color) / 255
X_test = X_test.reshape(-1, image_rows, image_cols, image_color) / 255
Y_train = to_categorical(Y_train,out_size)
Y_test = to_categorical(Y_test,out_size)
MNISTのデータセットの取り方、データの整形の仕方には個人差がありますが、僕はこれですね。
.astype('float32')とかする場合もありますけど、なんか省いてもよかったんでそうしてますw 次はモデルの構築と保存です。モデルはILSVRC-2014のVGGチームが使ったモデルに似せたの有名なVGG likeを使っていきます。GPUないときついものだったんですけど、これが載ってる参考書(後述)もびっくり、一回10秒で学習しちゃうんです。
(参考書では60000枚の画像を**「一回」**学習するのに350秒かかっております。)
# 前のは省いてます。
# モデル構築
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=input_shape))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(out_size))
model.add(Activation('softmax'))
model.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy']
)
model.fit(
X_train, Y_train,
batch_size=128, epochs=20,verbose=1,
validation_data=(X_test, Y_test)
)
コンパイルもフィットもしちゃったけどいいやってことでさらに発展させるため、モデルデータと学習済みデータ(重みデータ)を保存します。
# モデルを保存
model.save('MNIST-model.h5')
# 重みデータを保存
model.save_weights('MNIST-weights.h5')
これで一つ目のセルはできました。機能としては学習して保存。まだこれはテストしていないので正答率がわかりません。テストしたいのであれば、model.fitの下にこうかきます。
score = model.evaluate(X_test, Y_test, verbose=1)
print('正解率...', score[1], 'loss=', score[0])
テスト自体に時間はかからないのでテストしたのちにモデルなどを保存してもオッケーです。
全体ではこう。(これだけコピペしてもいいけどまだ続きあるから読んでください!)
import tensorflow as tf
from keras.datasets import mnist
from keras.utils import to_categorical
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten, Conv2D, MaxPooling2D
# データセットのロード(トレーニング用とテスト用で分かれている)
(X_train, Y_train), (X_test,Y_test) = mnist.load_data()
# データの形を変数に
image_rows = 28
image_cols = 28
image_color = 1 #グレースケールのこと
input_shape = (image_rows, image_cols, image_color)
out_size = 10
# データ整形
X_train = X_train.reshape(-1, image_rows, image_cols, image_color) / 255
X_test = X_test.reshape(-1, image_rows, image_cols, image_color) / 255
Y_train = to_categorical(Y_train,out_size)
Y_test = to_categorical(Y_test,out_size)
# モデル構築
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=input_shape))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(out_size))
model.add(Activation('softmax'))
# コンパイル
model.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy']
)
# 学習
model.fit(
X_train, Y_train,
batch_size=128, epochs=20,verbose=1,
validation_data=(X_test, Y_test)
)
# テスト
score = model.evaluate(X_test, Y_test, verbose=1)
print('正解率...', score[1], 'loss=', score[0])
# 保存
model.save('MNIST-model.h5')
model.save_weights('MNIST-weights.h5')
結果は以下。(あくまで一例)
Train on 60000 samples, validate on 10000 samples
Epoch 1/20
60000/60000 [==============================] - 15s 256us/step - loss: 0.2207 - acc: 0.9303 - val_loss: 0.0516 - val_acc: 0.9837
Epoch 2/20
60000/60000 [==============================] - 12s 207us/step - loss: 0.0635 - acc: 0.9806 - val_loss: 0.0274 - val_acc: 0.9905
Epoch 3/20
60000/60000 [==============================] - 12s 205us/step - loss: 0.0482 - acc: 0.9852 - val_loss: 0.0238 - val_acc: 0.9928
Epoch 4/20
60000/60000 [==============================] - 13s 213us/step - loss: 0.0382 - acc: 0.9882 - val_loss: 0.0263 - val_acc: 0.9916
Epoch 5/20
60000/60000 [==============================] - 13s 223us/step - loss: 0.0335 - acc: 0.9896 - val_loss: 0.0211 - val_acc: 0.9935
Epoch 6/20
60000/60000 [==============================] - 13s 224us/step - loss: 0.0287 - acc: 0.9906 - val_loss: 0.0220 - val_acc: 0.9938
Epoch 7/20
60000/60000 [==============================] - 14s 232us/step - loss: 0.0268 - acc: 0.9916 - val_loss: 0.0196 - val_acc: 0.9935
Epoch 8/20
60000/60000 [==============================] - 13s 220us/step - loss: 0.0250 - acc: 0.9922 - val_loss: 0.0174 - val_acc: 0.9944
Epoch 9/20
60000/60000 [==============================] - 12s 208us/step - loss: 0.0236 - acc: 0.9927 - val_loss: 0.0214 - val_acc: 0.9942
Epoch 10/20
60000/60000 [==============================] - 13s 216us/step - loss: 0.0208 - acc: 0.9936 - val_loss: 0.0179 - val_acc: 0.9941
Epoch 11/20
60000/60000 [==============================] - 13s 215us/step - loss: 0.0180 - acc: 0.9941 - val_loss: 0.0205 - val_acc: 0.9939
Epoch 12/20
60000/60000 [==============================] - 13s 224us/step - loss: 0.0159 - acc: 0.9947 - val_loss: 0.0228 - val_acc: 0.9936
Epoch 13/20
60000/60000 [==============================] - 14s 230us/step - loss: 0.0176 - acc: 0.9944 - val_loss: 0.0181 - val_acc: 0.9949
Epoch 14/20
60000/60000 [==============================] - 14s 227us/step - loss: 0.0158 - acc: 0.9951 - val_loss: 0.0205 - val_acc: 0.9945
Epoch 15/20
60000/60000 [==============================] - 13s 221us/step - loss: 0.0143 - acc: 0.9953 - val_loss: 0.0222 - val_acc: 0.9945
Epoch 16/20
60000/60000 [==============================] - 13s 209us/step - loss: 0.0154 - acc: 0.9952 - val_loss: 0.0241 - val_acc: 0.9940
Epoch 17/20
60000/60000 [==============================] - 12s 205us/step - loss: 0.0139 - acc: 0.9952 - val_loss: 0.0177 - val_acc: 0.9950
Epoch 18/20
60000/60000 [==============================] - 12s 207us/step - loss: 0.0136 - acc: 0.9959 - val_loss: 0.0233 - val_acc: 0.9939
Epoch 19/20
60000/60000 [==============================] - 13s 214us/step - loss: 0.0130 - acc: 0.9960 - val_loss: 0.0186 - val_acc: 0.9944
Epoch 20/20
60000/60000 [==============================] - 13s 213us/step - loss: 0.0116 - acc: 0.9963 - val_loss: 0.0190 - val_acc: 0.9945
10000/10000 [==============================] - 2s 171us/step
正解率... 0.9945 loss= 0.019046870391342646
(あれ…おかしいな?ChromeBookの時はもっと早かったのになぁ)
ネットとの通信によって早さが変わるらしいです。なので、レンダリングとかダウンロード中にやると焼き切れる可能性もあるようです。(物理的にではなく)
それにしても正解率=0.99越えはかなりの実力です。(100%が1となるので、99.45%に相当)
さすがVGG like。
ちなみに、epochs=10にしても結果は全く同じでした。(時と場合によって変わる)
そして、epochsは学習回数を表しているので、それを変えることで学習にかかる時間を調整できます。回数が少なすぎると、正解率が落ちますが。
4.【本題2】PythonからGoogleDriveにアクセスできるようにしよう(マウント)
+コードを押して新しいセルを作ります。
次はDriveからとってきた自分の手書き数字の画像を入れてできるようにするための準備です。
Colabratoryは仮想Ubuntu上に構築されているそうなのでpipコマンドやlsコマンドを使うことができます。普通にlsを実行するとUbuntu内のファイルが表示されますが、Pythonからパスを指定するとUbuntu内のファイルしか扱えません。ローカルファイルを使いたい場合は、uploadというのを行います。DriveからとるときはDriveをマウントし、それをUbuntu内に取り込まなくてはなりません。
まずは、以下のコマンドを実行してください。
!ls drive/"My Drive"/"Colab Notebooks"
エラーを吐かれ、そんなもんはないといわれるでしょう。
次はしっかりUbuntuに取り込みます。
(Driveを確認し、Colabratory関連のファイルがちゃんとColab Notebooksに保存されているか確認してから実行してください。初期設定の場合大丈夫です。)
from google.colab import drive
drive.mount('/content/drive')
途中、以下のようになるので、出てきたサイトに新しいタブでアクセスします。
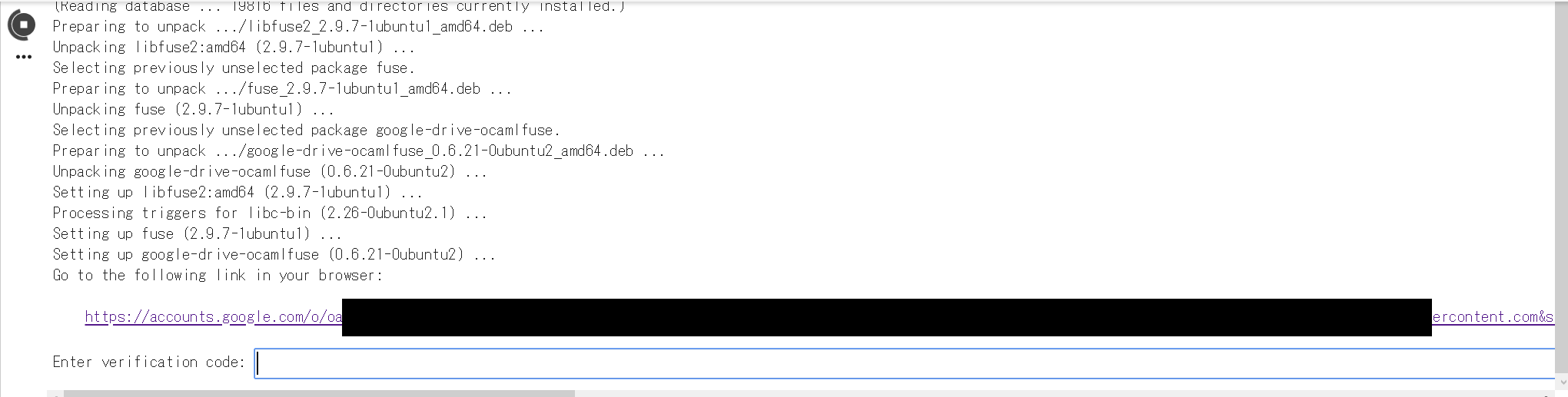
アカウントを選択し、ログインします。(Colaboratoryでログインしているアカウントでログインすることをお勧めします)

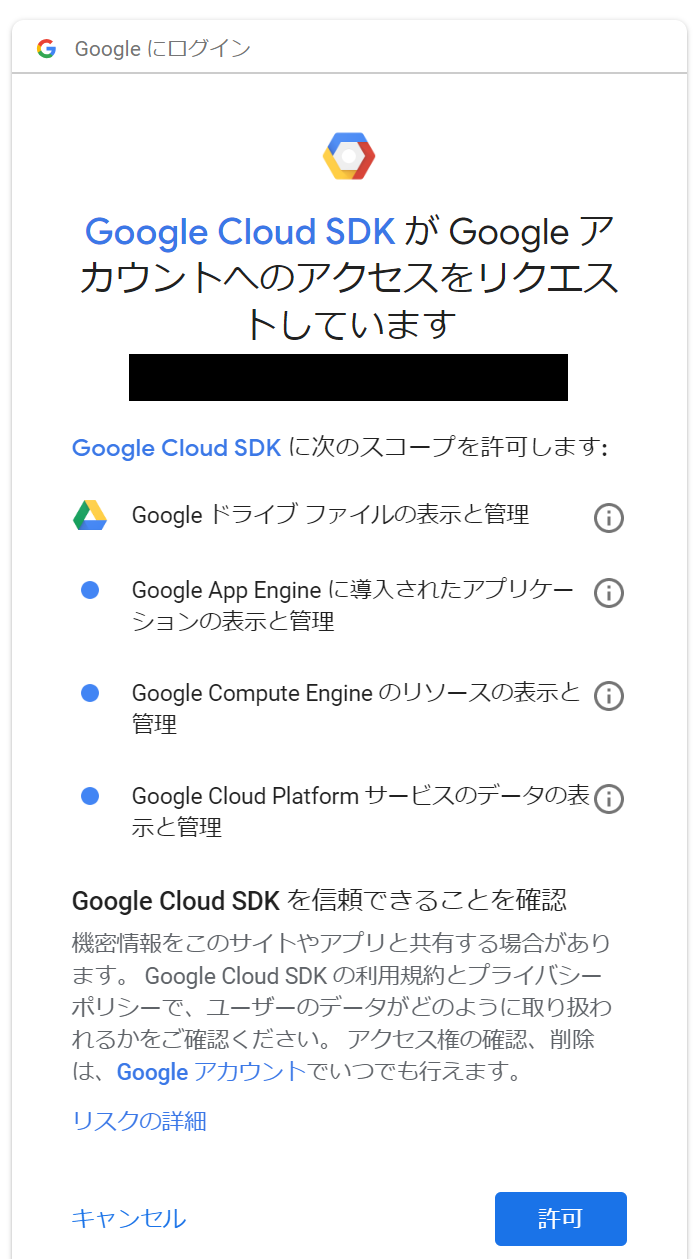
権限などを許可し
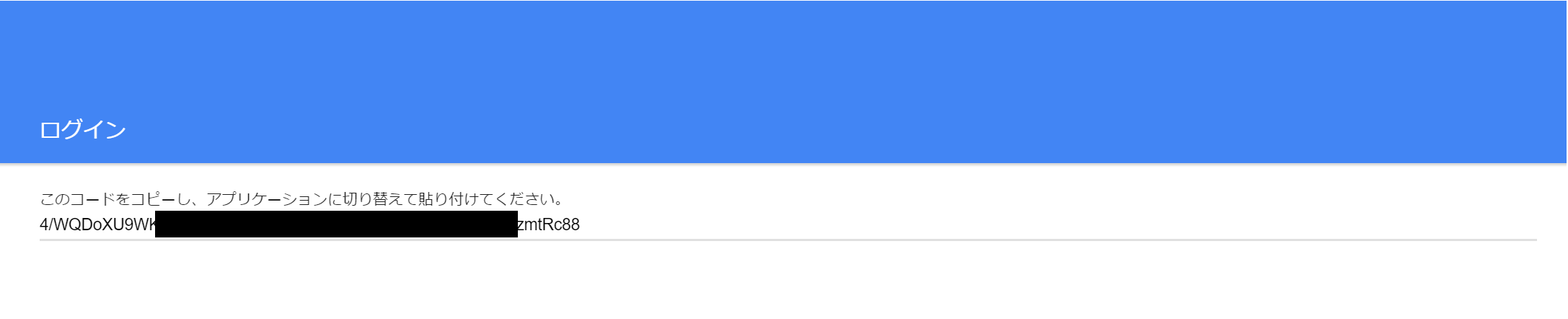
画面にある文字列をコピーします。(以下の場合だと4/Wから88まで)
Colabratoryに戻って、さっきコピーした文字列を枠内にペーストしてEnterキーを、押します。
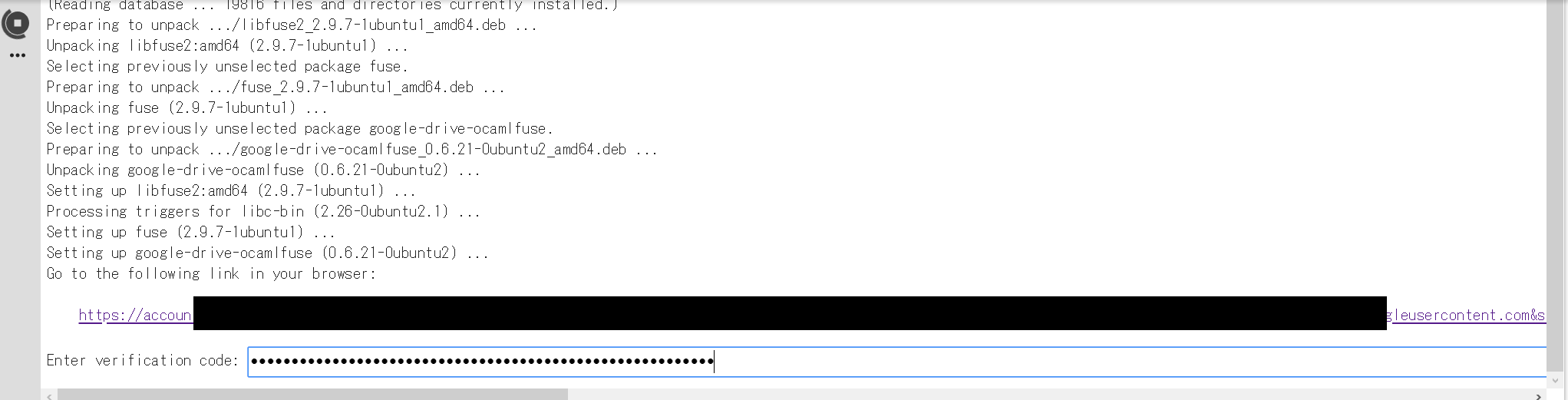
以上の作業の画像は少し本物と違いますが、ほぼ同じです。
もう一回、最初にエラーを起こしたコマンドを実行しましょう。
!ls drive/"My Drive"/"Colab Notebooks"
そうすれば、DriveにあるColab Notebooksの中が、表示されるでしょう。
さらに、一連のコマンドを実行後Driveからファイルを追加したり削除したりして再度lsコマンドを実行するとしっかり反映しています!なのでDriveに変更があってもいちいち実行しなくてもいいようです。
ここで注意!Colaboratoryにも制限がある(余談)
ColabratoryではUbuntu側のファイル、ダウンロードしたり実行したコードやコマンドの効力が12時間経つと初期化されます。なので、12時間経ったら(90分の場合もあり、とにかくランタイムが切れたら終わってしまう。)必要なコードやコマンド等はもう一回実行しましょう。この記事の場合、Mnistロード、モデルの作成、モデルの保存からマインドまですべてのコマンドを実行することをお勧めします。
これでいつでもDriveからファイルを取り出すことができました。つぎは本題をまとめて手書き数字の判定を行います。
5.【本題3】自分の書いた文字を判別しよう
まずは、どのペイントツールでもいいので自分が書いた数字を画像ファイルにして保存しましょう。PNGファイルをお勧めします。ただし、この時必ず縦と横の長さを同じにしてください。データは2828ですが、100100でも1000*1000でも大丈夫です。
from keras.models import load_model
from google.colab import files
from PIL import Image
import cv2
import numpy as np
from PIL import Image
from google.colab import files
# データの形を変数に
image_rows = 28
image_cols = 28
image_color = 1 #グレースケールのこと
input_shape = (image_rows, image_cols, image_color)
img = Image.open('drive/My Drive/Colab Notebooks/(自分で書いた数字のファイル名).png').convert('L')
# 画像を28x28に変換
img.thumbnail((image_rows, image_cols))
# フロート型の行列に変換
img = np.array(img, dtype=np.float32)
img = img.reshape(-1, image_rows, image_cols, image_color)
# 黒0~255白の画像データをMNISTのデータと同じ白0~1黒に変える
img = 1 - np.array(img / 255)
model = load_model('MNIST-model.h5')
model.load_weights('MNIST-weights.h5')
answer = model.predict_classes(np.array(img))
print("The computer guesses that this figure is \"", answer[0], "\"!")
Colaboratoryでやる場合にはimportは要らないのですが、.pyで保存したとき困るので一応。
下のようにファイルは置いてください。
このように置けば、
img = Image.open('drive/My Drive/Colab Notebooks/test_3.png').convert('L')
と変えて実行できます。ちなみにその時の結果は以下。
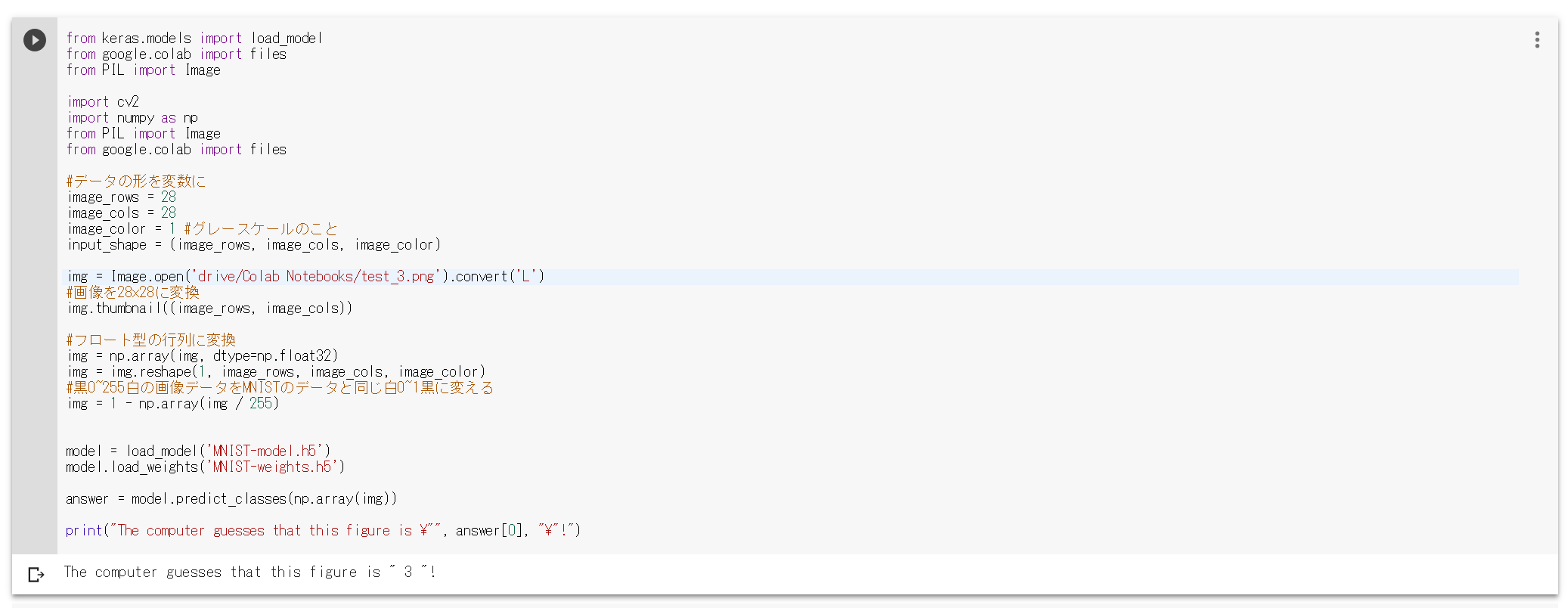
The computer guesses that this figure is " 3 "!
となって無事判別できます。友達に書いてもらった画像でも判定できなかったものはなかったです。(ふざけて書いたもの以外)
恐るべしVGG like!
以上。
今回はここまでです。質問がありましたらこちらのTwitterまで...https://twitter.com/Cyber_Hacnosuke
フォロー是非是非!