はじめに
前回、「将来の売上予測への挑戦:②PyFluxを用いた時系列分析」で、PyFluxを用いたARIMA, ARIMAXのモデル構築を行いました。
ただ、あまり良い精度が出ませんでした。
パラメーターである、ARやMAの次元数などを手探りで行っていったのですが、そこがイマイチだったのでしょうか。
とはいえ、「統計的に見てこれがいい!」というのは、私には中々ハードルが高いもの(汗
そこで、scikit-learnのGridSearchみたいなものがないかと調べてみました。
すると、「TV朝日の視聴率推移をSARIMAモデルで予測してみる」というページで、StatsModelsを用いた時系列分析のパラメーターチューニングを実装されていたので、そちらを参考に作ってみました。
分析環境
Google Colaboratory
対象とするデータ
前回同様に、データは日別の売上と説明変数として気温(平均・最高・最低)を用います。
| 日付 | 売上金額 | 平均気温 | 最高気温 | 最低気温 |
|---|---|---|---|---|
| 2018-01-01 | 7,400,000 | 4.9 | 7.3 | 2.2 |
| 2018-01-02 | 6,800,000 | 4.0 | 8.0 | 0.0 |
| 2018-01-03 | 5,000,000 | 3.6 | 4.5 | 2.7 |
| 2018-01-04 | 7,800,000 | 5.6 | 10.0 | 2.6 |
パラメーターチューニング
下記が、前回のプログラムです。
ar, ma, integがパラメーターです。
import pyflux as pf
model = pf.ARIMA(data=df, ar=5, ma=5, integ=1, target='売上金額', family=pf.Normal())
x = model.fit('MLE')
と、ここまでパラメーターチューニングと偉そうに申してきましたが、基本的には各パラメーターともに整数を取るので、数値をループでグルグル回しています。
def optimisation_arima(df, target):
import pyflux as pf
df_optimisations = pd.DataFrame(columns=['p','d','q','aic'])
max_p=4
max_d=4
max_q=4
for p in range(0, max_p):
for d in range(0, max_d):
for q in range(0, max_q):
model = pf.ARIMA(data=df, ar=p, ma=q, integ=d, target=target, family=pf.Normal())
x = model.fit('MLE')
print("AR:",p, " I:",d, " MA:",q, " AIC:", x.aic)
tmp = pd.Series([p,d,q,x.aic],index=df_optimisations.columns)
df_optimisations = df_optimisations.append( tmp, ignore_index=True )
return df_optimisations
これで、次のように呼び出すと
df_output = optimisation_arima(df, "売上金額")
結果が表示されます。PyFluxの評価基準はいくつかありますが、AIC(小さい方がいいモデル)を用いています。
AR: 0 I: 0 MA: 0 AIC: 11356.163772323638
AR: 0 I: 0 MA: 1 AIC: 11262.28357561013
AR: 0 I: 0 MA: 2 AIC: 11218.453940684196
AR: 0 I: 0 MA: 3 AIC: 11171.121950637687
AR: 0 I: 1 MA: 0 AIC: 11462.586538415879
それで、最もAICが小さかったAR/I/MAの組み合わせを、最適なパラメーターとして選択することができます。
df_optimisations[df_optimisations.aic == min(df_optimisations.aic)]
おわりに
前回の精度が惨敗だったため、総当りのパラメーターチューニングを、行いました。
とはいえ、出てきた結果は、中々精度は上昇せず。
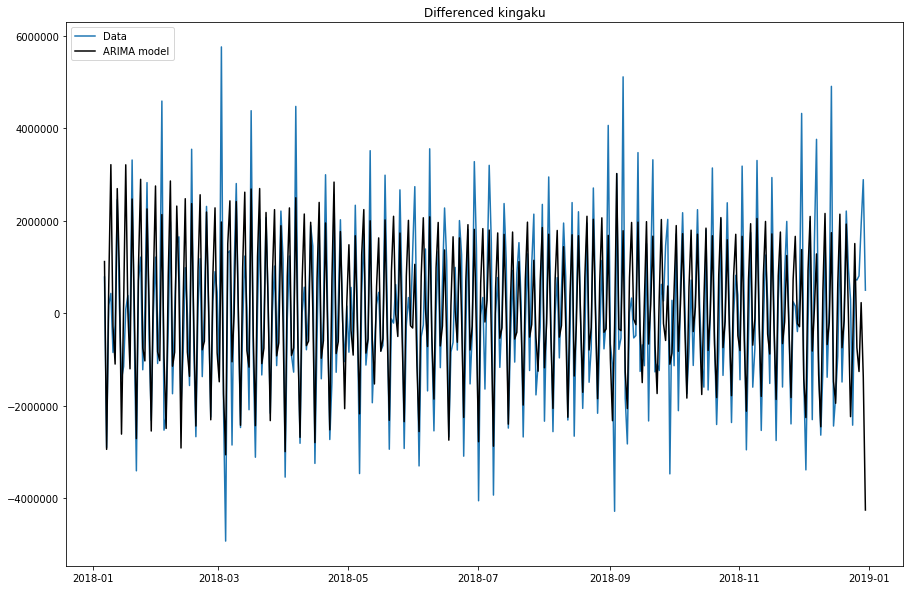
次なる改善策を考えないといけないですね。