はじめに
前回、将来の売上予測への挑戦:①時系列分析って何?では、将来の売上予測を実現する手段として、時系列分析を紹介しました。
紹介と言うより、(数学が全くわからない)自分なりの解釈でまとめてみたという感じで、しっかりと数式で理解されている方にとっては、「勘違いしているな~」という点もあったかもしれません。何かあれば、ぜひ、ご指摘いただけると幸いです。
さて、今回は実際に時系列分析のモデルを作っていきたいと思います。
モデルは、時系列データの予測ライブラリ--PyFlux--で紹介されていた、PyFluxを使ってARIMAモデルとARIMAXモデルを検証していきます。
(本当は、季節性を考慮したSARIMAもやりたかったのですが、PyFluxだとやり方が分からなかったので、今回は断念)
分析環境
Google Colaboratory
対象とするデータ
データは超シンプルに、日別の売上と説明変数として気温(平均・最高・最低)を用います。
| 日付 | 売上金額 | 平均気温 | 最高気温 | 最低気温 |
|---|---|---|---|---|
| 2018-01-01 | 7,400,000 | 4.9 | 7.3 | 2.2 |
| 2018-01-02 | 6,800,000 | 4.0 | 8.0 | 0.0 |
| 2018-01-03 | 5,000,000 | 3.6 | 4.5 | 2.7 |
| 2018-01-04 | 7,800,000 | 5.6 | 10.0 | 2.6 |
1.元データ作成
いつもの通り、BigQueryにある対象データをColaboratoryのPython環境にダウンロードします。
例のごとく、項目名は、和名ではつけられませんが、わかりやすくするためにここでは和名にしています。
import pandas as pd
query = """
SELECT *
FROM `myproject.mydataset.mytable`
WHERE CAST(日付 AS TIMESTAMP) between CAST("2018-01-01" AS TIMESTAMP) AND CAST("2018-12-31" AS TIMESTAMP) ORDER BY p_date'
"""
df = pd.io.gbq.read_gbq(query, project_id="myproject", dialect="standard")
# 欠損値はゼロに
df.fillna(0, inplace=True)
# 日付をDatetime型にして、dfのIndexに
df = df[1:].set_index('日付')
df.index=pd.to_datetime(df.index, utc=True).tz_convert('Asia/Tokyo')
df.index = df.index.tz_localize(None)
df= df.sort_index()
後々の処理のために、日付をDatetime型にしてIndex化することが必要です。
BQ→Pythonの連携には、なぜかBigQuery Storage APIを使ってみたで検証した際に、一番遅かったPandasのread_gbqを使ってますね。
元データがそんなに重くないときは、シンプルに書けて楽ですし。。。(言い訳)
ひとまず売上データを見てみましょう。
%matplotlib inline
import matplotlib.pyplot as plt
plt.figure()
df["売上金額"].plot(figsize=(12, 8))
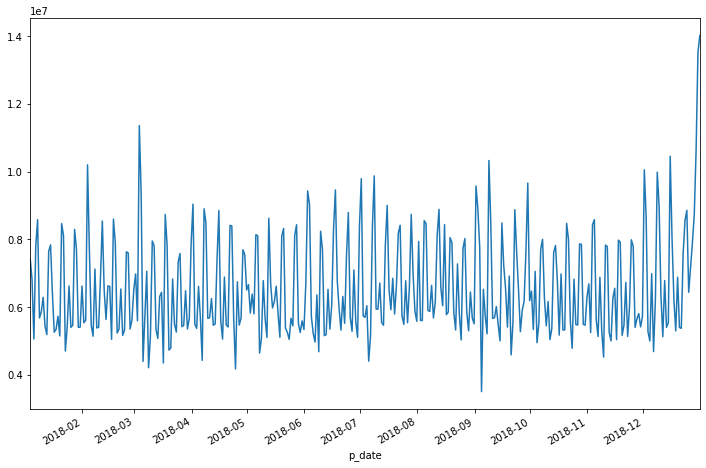
日別なのでかなり上がったり・下がったりしています。3月始めや年末は急に上がっていますね。
2.ARIMAモデルの構築
ここから、PyFluxを用いて時系列分析をしていきます。
とはいえ、ColaboratoryにはPyFluxが標準インストールされていないので、まずはインストールしましょう。
pip install pyflux
モデルのプログラミング自体は、超シンプル。ARIMAに渡される引数は次の5つです。
- ar : 自己回帰の次数
- ma : 移動平均の次数
- integ : 差分の階数
- target : 目的変数
- family : 確率分布
そして、MLE(最尤推定)でモデルを予測します。
import pyflux as pf
model = pf.ARIMA(data=df, ar=5, ma=5, integ=1, target='売上金額', family=pf.Normal())
x = model.fit('MLE')
とはいえ、arやma, integの値をいくつにするべきなのかは、予想もつかないので、まずは動かしてみるしかないですね。
x.summary()
そうすると出てくるサマリがこちら。
モデル自体の評価は、AIC(赤池情報量基準)やBIC(ベイズ情報量規準)を使えば、それが低いモデルが良いと言えそうです。
変数の評価は、P値(P>|z|)を使えばいいでしょうか?Constant(固定値)や、AR(3)・MA(5)はP値が高くて有意でなさそうですね。
AR・MAの1つが有意でないというのは、それぞれの次数を1つ減らせばいいということでしょうかね。
ただ、固定値が有意でないといわれてしまうと、そもそもこのデータはARIMAモデルに使うのは厳しいってことかな?
Normal ARIMA(5,1,5)
======================================================= ==================================================
Dependent Variable: Differenced kingaku Method: MLE
Start Date: 2018-01-09 03:00:00 Log Likelihood: -5401.3927
End Date: 2019-01-01 03:00:00 AIC: 10826.7854
Number of observations: 357 BIC: 10873.3182
==========================================================================================================
Latent Variable Estimate Std Error z P>|z| 95% C.I.
======================================== ========== ========== ======== ======== =========================
Constant 18212.1745 51000.329 0.3571 0.721 (-81748.4703 | 118172.819
AR(1) 0.2046 0.0583 3.507 0.0005 (0.0902 | 0.3189)
AR(2) -0.9284 0.0476 -19.4981 0.0 (-1.0217 | -0.8351)
AR(3) -0.0762 0.0807 -0.9438 0.3453 (-0.2343 | 0.082)
AR(4) -0.4864 0.0465 -10.4663 0.0 (-0.5774 | -0.3953)
AR(5) -0.5857 0.0555 -10.5508 0.0 (-0.6945 | -0.4769)
MA(1) -0.8716 0.0787 -11.0703 0.0 (-1.0259 | -0.7173)
MA(2) 0.9898 0.0905 10.9326 0.0 (0.8123 | 1.1672)
MA(3) -0.5321 0.1217 -4.3708 0.0 (-0.7707 | -0.2935)
MA(4) 0.4706 0.0945 4.9784 0.0 (0.2853 | 0.6558)
MA(5) 0.007 0.0725 0.0973 0.9225 (-0.135 | 0.1491)
Normal Scale 900768.835
==========================================================================================================
統計量的には、あまり良くない感じでしたが、グラフではどうなっているでしょう。
model.plot_fit(figsize=(15, 10))
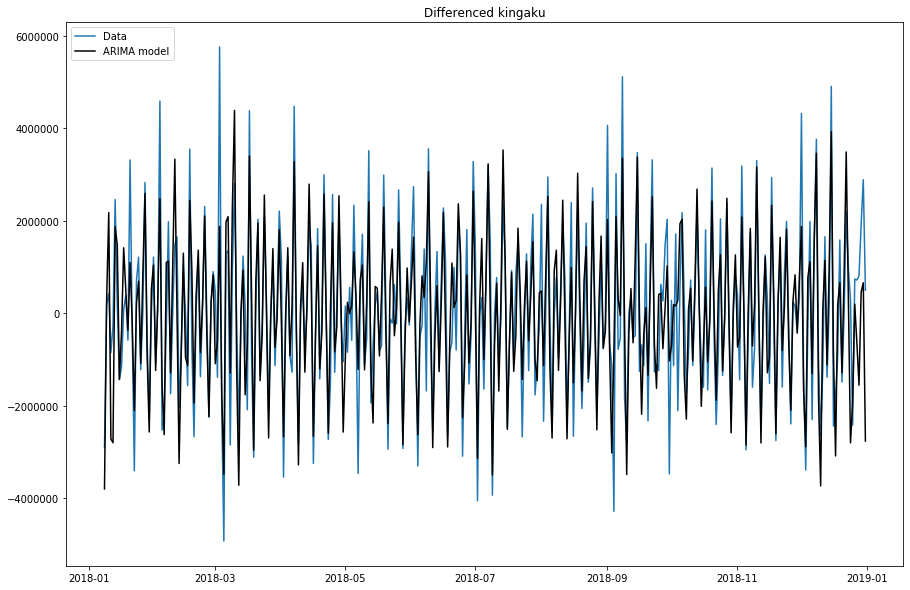
青が実数、黒がモデル値ですね。
上がったり、下がったりするタイミングは似ていますが、実数の振れ幅の大きさを予測しきれていないタイミングが多く見られますね。
3.ARIMAXモデルの構築
続いて、ARIMA+変数を使えるARIMAXモデルを構築してみましょう。
こちらもプログラムは超シンプルです。formulaという引数に、「目的変数~1+説明変数」と書くようです。(ちょっと直感的ではない書き方ですが)
import pyflux as pf
model = pf.ARIMA(data=df, formula='売上金額~1+平均気温+最高気温+最低気温', ar=5, ma=5, integ=1, target='売上金額', family=pf.Normal())
x = model.fit('MLE')
その後、ARIMAと同じ様にモデルを評価します。
x.summary()
AIC・BICともほぼ同じですね。説明変数として追加した気温の変数は、P値が1.0と全く駄目ですね。。。
Normal ARIMAX(5,1,5)
======================================================= ==================================================
Dependent Variable: Differenced kingaku Method: MLE
Start Date: 2018-01-09 03:00:00 Log Likelihood: -5401.6313
End Date: 2019-01-01 03:00:00 AIC: 10829.2627
Number of observations: 357 BIC: 10879.6732
==========================================================================================================
Latent Variable Estimate Std Error z P>|z| 95% C.I.
======================================== ========== ========== ======== ======== =========================
AR(1) 0.2036 0.0581 3.5023 0.0005 (0.0897 | 0.3175)
AR(2) -0.9277 0.0475 -19.5352 0.0 (-1.0208 | -0.8346)
AR(3) -0.0777 0.0804 -0.9658 0.3342 (-0.2353 | 0.08)
AR(4) -0.4857 0.0463 -10.4841 0.0 (-0.5765 | -0.3949)
AR(5) -0.5869 0.0552 -10.6292 0.0 (-0.6952 | -0.4787)
MA(1) -0.8687 0.0775 -11.2101 0.0 (-1.0205 | -0.7168)
MA(2) 0.989 0.0902 10.9702 0.0 (0.8123 | 1.1657)
MA(3) -0.5284 0.1211 -4.3651 0.0 (-0.7657 | -0.2912)
MA(4) 0.47 0.0942 4.9874 0.0 (0.2853 | 0.6547)
MA(5) 0.0097 0.0715 0.1353 0.8924 (-0.1305 | 0.1499)
Beta 1 0.0 59845.8347 0.0 1.0 (-117297.836 | 117297.836
Beta kion_min -0.0 755.0035 -0.0 1.0 (-1479.8069 | 1479.8068)
Normal Scale 901399.389
==========================================================================================================
最後にグラフ化します。
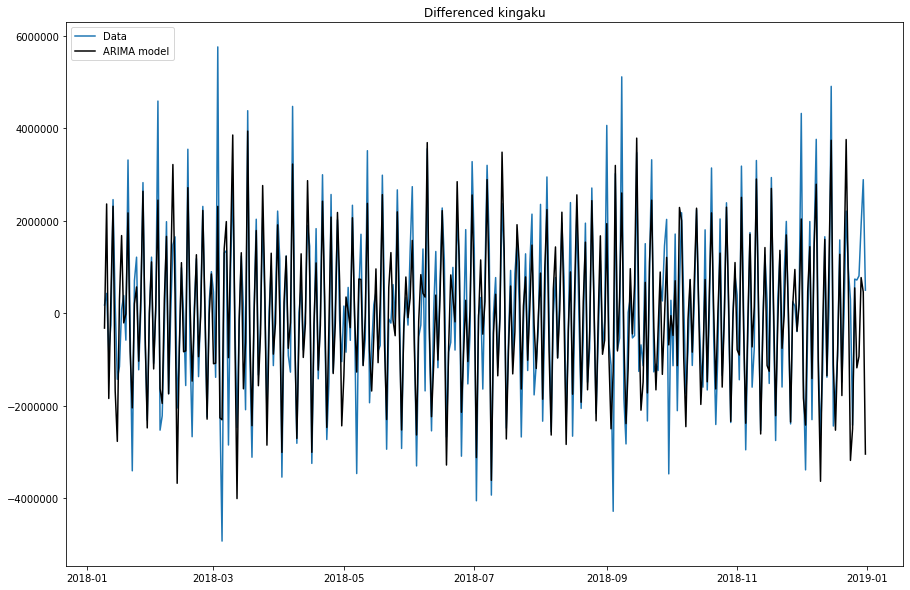
model.plot_fit(figsize=(15, 10))
ん~。ARIMAモデルと変わらない。
おわりに
PyFluxで時系列分析ぼプログラム自体は、非常に簡単につくることができました。
ただ、ARIMA、ARIMAXともに上がる・下がるの方向性はいいのですが、その幅が小さくてモデルの精度も上がらないですね。各パラメーターも、いくつを指定するのが最適かは難しいです。
あとは季節性があるのかもしれません。(PyFluxだと使えなかった、SARIMAか?)
また、今回は気温を使った説明変数が全く役立っていなかったので、ここも改善余地がありそうです。