torch.nn.TransformerEncoder (のサブモジュール) のイラストです。
[2026-04-09 追記] デコーダも含めた Transformer 全体のイラストは以下です。
Transformer のイラスト - Qiita
参考文献
- MultiheadAttention — PyTorch 2.10 documentation
- TransformerEncoderLayer — PyTorch 2.10 documentation
- TransformerEncoder — PyTorch 2.10 documentation
図
緑色の矢印: 学習パラメータをもつネットワーク
薄緑の矢印: 学習パラメータをもつネットワーク (オプショナル)
黄色の矢印: ハイパーパラメータで制御されるモジュール
torch.nn.MultiheadAttention
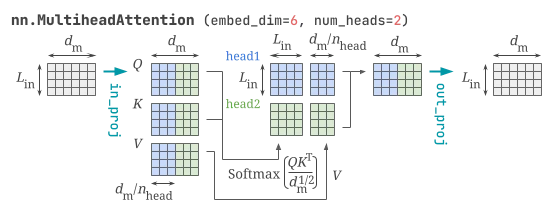
ドキュメントによると、torch.nn.MultiheadAttention はあくまで Attention is All You Need 版を実装したものであって、最新の機能はあまり取り込んでいないので、よりよいレイヤーを自作することやより高レベルのライブラリを使用することが推奨されています。
torch.nn.TransformerEncoderLayer
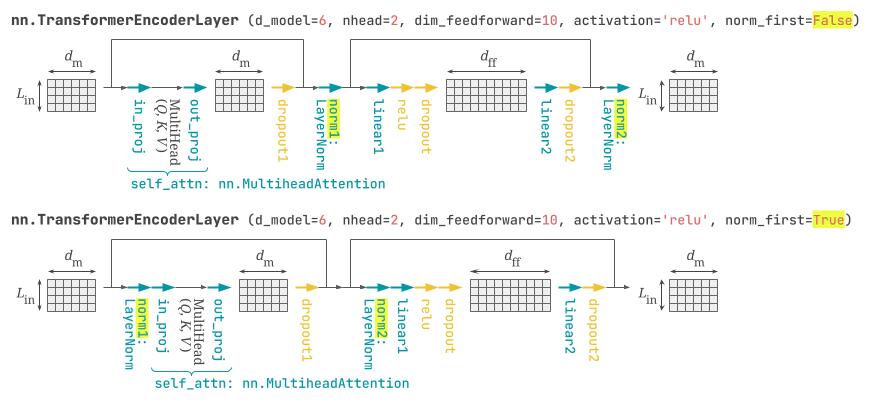
ドキュメントには torch.nn.MultiheadAttention 同様の注意書きがあります。
torch.nn.TransformerEncoderLayer はデフォルトではレイヤー正規化1層は残差接続後ですが (Post-LN)、フラグによって入力直後に移動できます (Pre-LN)。このフラグ設置は Pre-LN の方が安定という研究を受けています。
torch.nn.TransformerEncoder
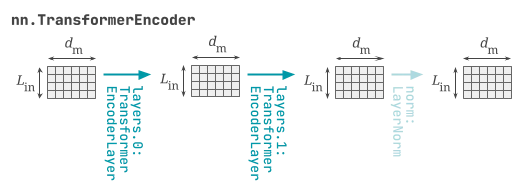
ドキュメントには torch.nn.MultiheadAttention 同様の注意書きがあります。
torch.nn.TransformerEncoder は torch.nn.TransformerEncoderLayer を繰り返します。が、すべてのレイヤーを同じパラメータで初期するので、インスタンス作成後に手動で改めて初期化することが推奨されています。
引数 norm にレイヤー正規化層を渡せば最後にレイヤー正規化を追加することもできます (Pre-LN にすると最終出力が正規化されていないので、そのための引数だと思います)。
補足
- 3 枚の図それぞれのパラメータ数は以下です。
(6 + 1) * 18 + (6 + 1) * 6 = 168168 + (6 + 6) + (6 + 1) * 10 + (10 + 1) * 6 + (6 + 6) = 328328 + 328 + (6 + 6) = 668
- 3 枚の図に対応するモデルを生成し、情報を表示するスクリプトは下記です。
- スクリプトの最後でオブジェクト ID を確認しているように、torch.nn.TransformerEncoder は引数に torch.nn.TransformerEncoderLayer のインスタンスを受け取って層数だけ複製しますが、受け取ったインスタンス自体は使用しません。レイヤー正規化層については受け取ったインスタンス自体を使用します。
import torch
def _print(model):
print('----- Architecture -----')
print(model)
print('----- Trainable Parameters -----')
for name, param in model.named_parameters():
print(f'{name}: {tuple(param.shape)}')
n = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(' -> total:', n, 'parameters')
# torch.nn.MultiheadAttention
attn = torch.nn.MultiheadAttention(embed_dim=6, num_heads=2)
_print(attn)
# torch.nn.TransformerEncoderLayer
layer = torch.nn.TransformerEncoderLayer(
d_model=6, nhead=2, dim_feedforward=10, batch_first=True,
)
_print(layer)
# torch.nn.TransformerEncoder
norm = torch.nn.LayerNorm(6)
model = torch.nn.TransformerEncoder(
encoder_layer=layer, num_layers=2, norm=norm,
)
_print(model)
assert id(layer) != id(model.layers[0])
assert id(norm) == id(model.norm)
-
レイヤー正規化は各特徴量ベクトルを正規化する操作です。入力が「私は、犬が、好き」なら「私は」ベクトルを正規化、「犬が」ベクトルを正規化、「好き」ベクトルを正規化します。 ↩