サマリー
・映像解析による交通量調査の手法について
・解析結果の映像サンプルはこちら:https://youtu.be/kgjG6_hejE8
・映像によっては誤認識しやすいエリアがある
・マスク機能について
映像解析による交通量調査の手法について
ここではディープラーニングによる映像解析精度を上げるためには「解析しないこと」が早道だよ、という話をします。ディープラーニングそのもののチューニングによる解決ではなく、実装方法の工夫による回避なので、ディープラーニングの勉強にはならないかも。
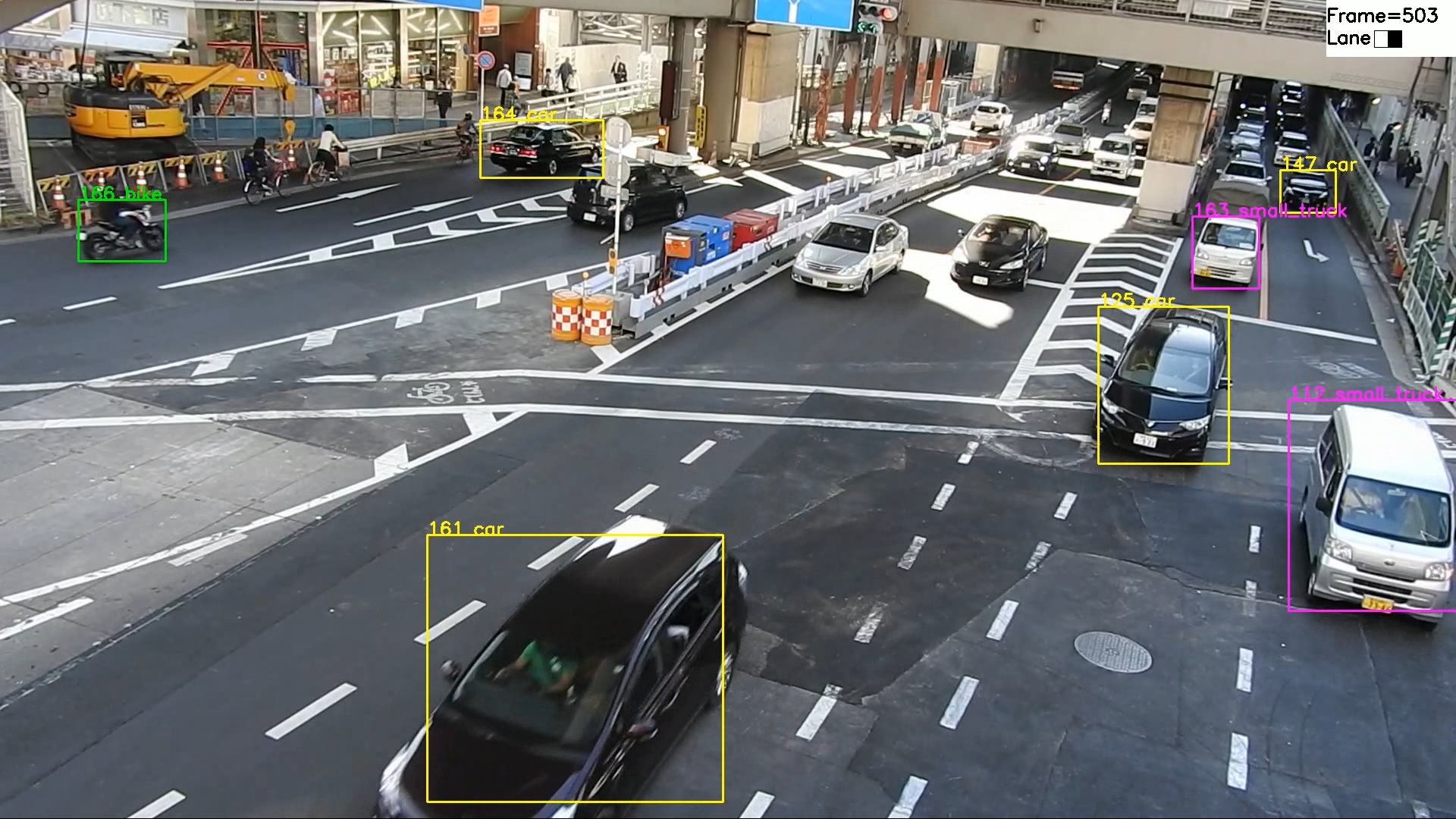
あ、トップ画像ですが「small_truck」として軽貨物が判別できているのがちょっと自慢。ピンクの枠です。
・やっぱり映像解析は簡単ではない
前の記事でも書いてますが、SSDにしてもMask R-CNNにしてもYOLO V3にしても物体検出は「静止画」に対して行います。動画をinputに選択できたとしても、それは連続した静止画に対して行うものであり、前後の静止画で類似点を見つけたり特徴量を検出したりしてトラッキングを行ってくれるわけではありません。つまり静止画ではなく、映像(動画)を解析しようと思ったらいろいろ頑張る必要があります。
・映像による交通量調査について
交通量調査は、映像内に何台の車がいて、それぞれがどの分類で(普通車・大型貨物・小型貨物・バスなど)、どの車線を走っているかを調べるのが目的です。
調べ方としては、画像内に映っている車両全てをカウントするのが手っ取り早そうですが、カメラから離れた車両は小さく映っていたり他の車に隠れていたり、そもそも車種が分からなかったりして人間でも苦労します。
「じゃあ、画面内にラインを引いて、それを越えた移動体をカウントすればいいんじゃない?」と思いましたが(実際にCD社はOpenCVっぽい技術でそれをやってそう)、車がずっと流れる高速道路ならともかく信号待ちとかで車が動かない場合はカウントできません。
そこで画面に映っている車両をすべて検出し、その動きをトラッキングしてカウントすることにしました。この決断は、その後に車両の速度や車間距離を算出する際に役立ちました。
・そういえば車種判定は?
YOLO V3やSSDは検出した物体を分類するクラスを持ってます(正確には学習モデルを持っている)。ただビックリするのは、画面の端からちょっとだけ出ている車両もちゃんと「検出」すること。検出に「」をつけたのは、「検出はするけどたまに間違ったクラス分けをする」からです。
まあ人間でもそうですが、画面からちょっと出ている車の部分を見て、「普通車かな?」と思っていたら車が動いて全体が画面に入り、「なんだトラックかあ」という事はよくあります。特に角度がついてボンネットが見えにくいアングルの映像の場合。
ディープラーニングによる物体検出でも物体の一部画像からクラスを検出してくれますが、やっぱり分類が間違ってることがある。その場合は、「その車両が登場して画面から消えるまで、どのクラスとするか?」という車両判定の問題があります。最初に分類したクラスが間違えていることがあるのですが、「じゃあ最後に判定したクラスならいいの?」という問題にもなります。これは長くなりそうなので、別記事で書きます。
※物体検出では静止画単位でしか検出&クラス分けしないので、映像の最初と最後でクラスが違うことがよくある。
映像によっては誤認識しやすいエリアがある
・共通設定で画面全体くまなく検出するのはムリ
YOLO V3では検出した対象にスコアをつけて報告してくれます。スコアは「自信度」みたいなもので、1が最高で数が大きいほど「判定に自信があります」となる。「スコア1だけ報告しろ」とすると、全体の5%くらいしか検出してくれないし(検出洩れがある)、「スコア0.1以上はすべて報告しろ」すると道路に描かれたマークまで「これ車かもしれません。ぜんぜん自信ないですけど」と誤検出の嵐となる。
で、このスコアは0.6とか0.8くらいにするのが普通なんだけど、そうすると映像の場所によって誤検出が起きる。

今回の映像ではピンクの枠で囲った部分の誤検出がひどかった。カメラ(iPhone)の性能もあるのだけど、一部分だけ(しかもストライプ状に)陽が当たっているとコントラストの差が大きくなりすぎて白い車は見えなくなり(検出洩れ)、黒い車はグレイの別車両としてカウントされてしまう(多重カウント)。しかも直後に黒の車両として別カウントされたりして、要するに検出洩れや多重カウントがこのエリアで多数発生してしまった。
NG検出例はこちら:https://youtu.be/2_2QPwRMglg
他にも柱とか部分的な遮蔽物があるエリアではさすがのカルマンフィルタでもトラッキングできなくて、画面から消える直前に別車両として認識されたりして無駄にカウンターを回してしまう。
そもそもカルマンフィルタやパーティクルフィルタは「対象物がすべてが検出されていることを前提に、見えたり見えなかったりした対象物の同一性を推論します」というものなので、ディープラーニング側で物体検出をミスったら必要な情報がカルマンフィルタにわたらず、トラッキングもできなくなるのは当然ですね。
私も最初は検出スコアの閾値を変更したりカルマンフィルタのパラメータをいじることでなんとか画面内をくまなく検出してかつ検出精度をあげようとしたのだけど、最終的にあきらめました。そこで解決策としてマスク機能を実装することにしました。
マスク機能について
ここでは検出に影響を与えるエリアを映像上に指定できることをマスク機能と呼んでます。「検出に影響を与える」としているのは、当初は除外(検出対象外)だけだったのですが、後ほど拡張して車線の指定ができるようにしたからです。
当初の要件としては以下の通り。
・ムービーと同じ縦横サイズの画像(PNGファイル。マスク画像と呼ぶ)1枚で指定する。
・マスク画像はでグレイ(R=100 G=100 B=100)で塗りつぶした部分を除外エリアとする。
・除外エリアでは物体検出しても無視する(カウント処理やトラッキング処理に渡さない)。
・物体が除外エリアにいるかどうかの判定は、検出したバウンディングボックスの中心点を算出し、それのXY座標とマスク画像の対応したピクセルがグレイの場合は「除外エリアにいる」と判定する。
ただこれにより誤検出が多発するエリアを除外して検出精度を上げることはできましたが、新たに「車は上り・下り車線ごとにカウントしたい」という要件が発生しました。これによりマスクで使用するRGBをグレイのほか白・黒を追加して、中心点が白と黒のエリアにいた場合は、ログにそれぞれ
W,Bとフラグを立てるようにしました。実際に使用するマスクは次のような感じです。

またマスクが有効かどうか確認しやすいよう、解析したビデオにマスク画像をオーバーレイする機能を追加しました。オーバーレイしたイメージはこんな感じです。グレイ部分は透明にしています。
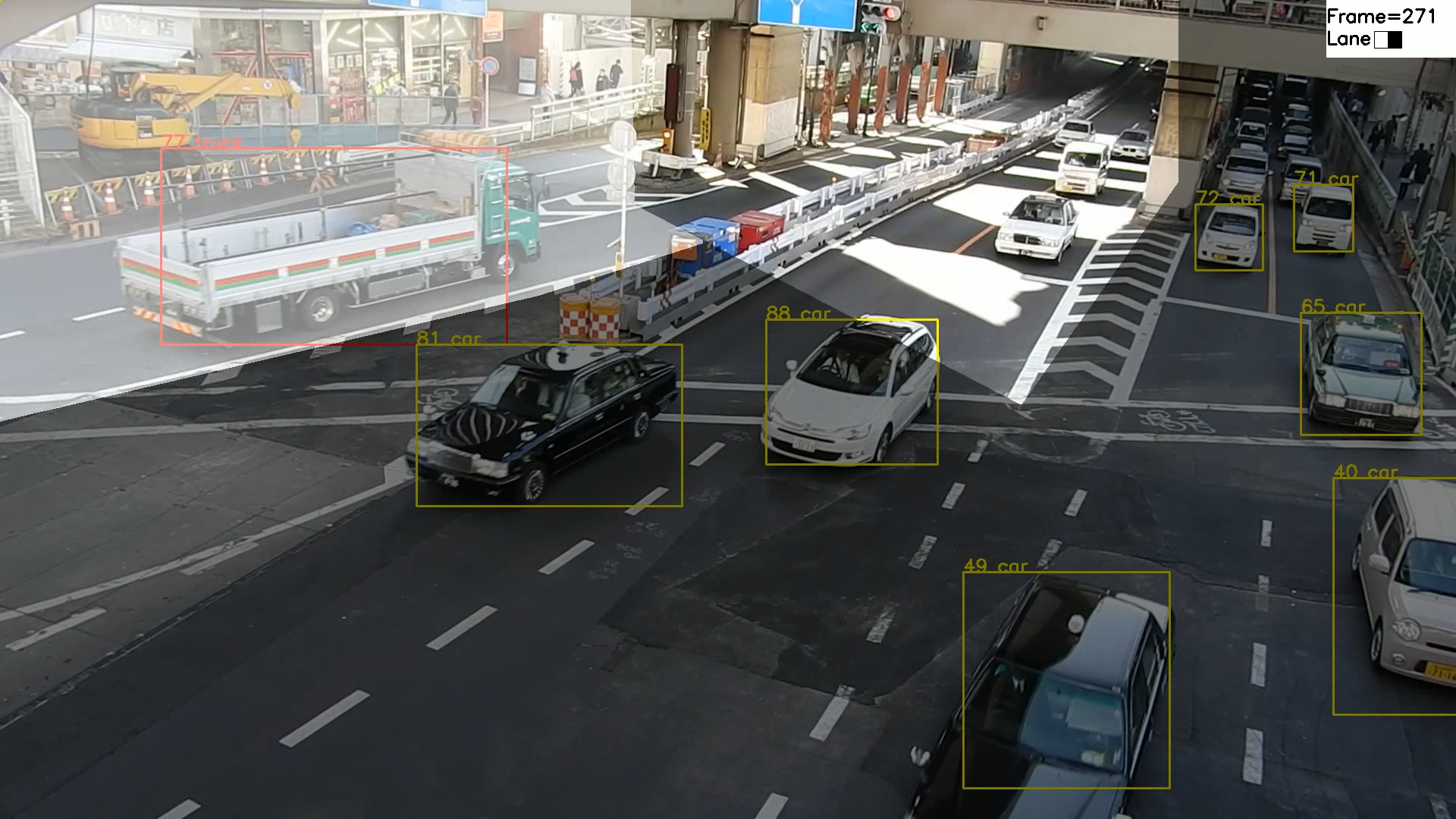
映像サンプルはこちら:https://youtu.be/hP93ONKZjwc
またその後、速度と車間距離を算出するために白黒だけではなく任意の色が追加できるようにしました。皆さんの実装のご参考になれば幸いです。
関連記事
・2022年:YOLOXの映像解析で車両の速度をAIで算出して渋滞を判定するのに苦労した~その1:リアルタイム処理編
・2022年:YOLOXの映像解析で車両の速度をAIで算出して渋滞を判定するのに苦労した~その2:速度算出手法編
・[ディープラーニングで故障車両を発見するのに苦労した]
(https://qiita.com/ComputerVision/items/4f377bc3eb5e601676ac)
・[ディープラーニングで映像から速度を正確に算出するのに苦労した]
(https://qiita.com/ComputerVision/items/d5358632209c67dab325)
・[ディープラーニングによる映像解析で車両をトラッキングするのに苦労した]
(https://qiita.com/ComputerVision/items/d865f084c98a59349910)
・[SSD_KerasをWindowsで使って交通量調査できるか試してみた]
(https://qiita.com/ComputerVision/items/0f87b35f5941b7c3c06b)
・[YOLO V3を使った交通量調査ソフトを作って苦労した]
(https://qiita.com/ComputerVision/items/bdbf5c237004195a4fbc)