ソフトウェア開発を安全かつ効率的に進める上で、CIサービスでの自動テストやビルドなどのチェックはもはや欠かせません。しかしCIが失敗した時の対応法や体制作りが十分であるケースは多くありません。
例えばこんなシナリオを考えてみましょう。作業がひと段落し、コミットをpushします。PRを作成してマネージャーにマージをリクエストして別のチケットに着手する。よくあるソフトウェア開発の1場面です。もしCIが失敗した場合、どのように調査や対応を進めているでしょうか?
この記事では、CIでパイプラインが失敗した時の対応を効率的に進めるためのジョブ設計について紹介します。
CIエラーはソフトウェアの安全装置が機能している証拠
CIエラーが発生し、エラーの通知メールやSlackが届く時、多くの開発者はあまりいい気分ではないでしょう。自分が書いたコードに問題があると開発メンバーから見える場所で指摘されているように感じる人もいるでしょう。しかしCIが解決するものを考えると、本来CIエラーはポジティブなイベントです。
CircleCIは「開発チームが高品質な製品をより迅速かつ安全に出荷できるよう支援します」をミッションの一つに掲げています。これはコードが抱える問題をリリース前に検知することで、本番での問題発生を抑止する、いわば安全装置や品質ゲートを目指しているとも言えます。
もちろんコードレビューや手動テストで問題を見つけることも重要です。しかしコードレビューは設計の意図や可読性・将来の保守性といった長期的な視点に集中すべきですし、手動テストもユーザー体験やビジネス的な目的を達成できているかなどにフォーカスすべきです。自動テストやCIはレビュワーが本来やるべきことに集中するため、「テストしようとしたが、画面が真っ白になった」のようなブロッカーを除去する目的で導入するものです。
CIの「シグナル」を正しく迅速に発見する
CIエラーに不安を感じる理由の1つは、「どうすれば良いかがわからない状況へのストレス」です。CIサービスのダッシュボードに移動して失敗したジョブを特定し、その中にある数百行数千行のログから問題を発見する。CIエラーの通知が届く前に着手していた仕事からのコンテキスト切り替えも踏まえると、気持ちよく取り組める作業と言える人は多くないでしょう。
ポイントは、「どこで何が起きているかを、素早く見つけることができるか」です。例えば次のCI定義を見てみましょう。このYAMLファイルはリント・テスト・ビルドを順番に実行しており、どれかが失敗するとCIエラーが発生します。
version: 2.1
orbs:
node: circleci/node@7.2.1
jobs:
run-ci:
executor:
name: node/default
resource_class: small
steps:
- checkout
- node/install-packages:
pkg-manager: npm
- run:
name: Check
command: |
npm run lint
npm run test
npm run build
workflows:
test:
jobs:
- run-ci
一見シンプルなワークフローに見えますが、ここには1つの問題があります。それは「このCIエラーはどこで何が起きたか」を見つけることが困難です。実際に実行した結果をスクリーンショットでチェックしてみましょう。

「Checkというタスクが失敗した」ことはわかりますが、「lint / test / buildどのコマンドが失敗したか」についてはログを見るまで分かりません。そのため「CIエラーの調査タスク」は必ず「ログの分析」から始まることになります。
では、このYAMLを次のように編集するとどうでしょうか?
version: 2.1
orbs:
node: circleci/node@7.2.1
jobs:
run-ci:
executor:
name: node/default
resource_class: small
steps:
- checkout
- node/install-packages:
pkg-manager: npm
- run:
name: Lint
command: npm run lint
- run:
name: Test
command: npm run test
- run:
name: Build
command: npm run build
workflows:
test:
jobs:
- run-ci
jobs.stepsを分割しただけで、実行するタスクは全く同じです。しかし実行結果を見てみると、状況が少し変わります。

今度はログをみるまでもなく「リントが失敗している」ことがわかるようになりました。このようにCIジョブを適切に分割することで、ログを見る前に「どんな問題・シグナルが出ているのか?」を把握できるようになり、どのような視点・コンテキストでログを見るべきかを開発者が理解できるようになります。
このような考え方について、入門 継続的デリバリーでは次のように説明されています。
パイプラインから得たい個々のシグナルごとに、それぞれタスクを切り分けていく
大切なのは、得たいフィードバックの種類ごとにタスクを切り分けることです。Lint、ユニットテスト、インテグレーションテストなどを個別のジョブとして独立させましょう。これによってエラーの解像度が高まり、『どこを直せばいいか』がダッシュボードを見た瞬間にわかることができます。
軽いチェックを先に、重いチェックを後に
より早く問題に気づき、修正作業を完了させるためには、少なくとももうひと工夫が必要です。CIの設定を次のように変更してみましょう。
version: 2.1
orbs:
node: circleci/node@7.2.1
jobs:
lint:
executor:
name: node/default
resource_class: small
steps:
- checkout
- node/install-packages:
pkg-manager: npm
- run:
name: Lint
command: npm run lint
test:
executor:
name: node/default
resource_class: small
steps:
- checkout
- node/install-packages:
pkg-manager: npm
- run:
name: Test
command: npm run test
build:
executor:
name: node/default
resource_class: small
steps:
- checkout
- node/install-packages:
pkg-manager: npm
- run:
name: Build
command: npm run build
workflows:
test:
jobs:
- lint
- test
- build
これまでと比較すると、かなり長くなりました。実行したいチェックごとにjobを定義し、workflowsに並べる形でパイプラインを定義しています。
CircleCIのパイプライン実行履歴を一覧表示するページを見ると、この変更の効果が一目でわかります。
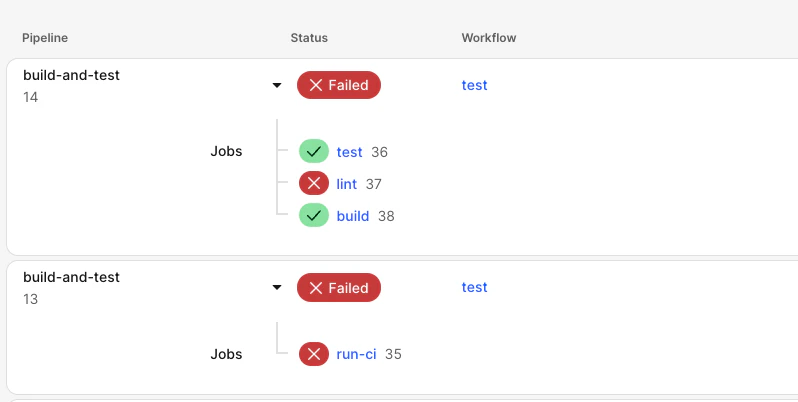
1つ目が今回変更した定義によるもので、2つ目はそれまでの設定です。実行されたワークフローの詳細ページを見ることなく、リントエラーへ気づけるようになりました。また、テストやビルドが並列実行されるようになったため、「ロジックに問題はないが、コードの書き方にルール違反が発生している」という状況までこのページで察することができます。
このように複数の依存しない視点からチェックを並列実行することで、ログを見る前に問題の種類や詳細について理解できるようになります。依存関係のない、直行性のあるタスクについては並列で同時にチェックを実行しましょう。そして「ビルドしたアプリへE2Eテストを実施する」といった依存関係のあるチェックや、AWS環境へのコードデプロイのようなコスト・時間の消費が大きいものについては、軽量なタスクが完了してから実行するようにします。
例えば以下の例では、2種類のテストを実行した後にそれぞれのカバレッジレポートを収集しています。ビルドに時間のかかるアプリケーションなどでは、テストを実行した後で実行する設計にすることで、テストが失敗した時の通知を素早く受け取れるようになります。
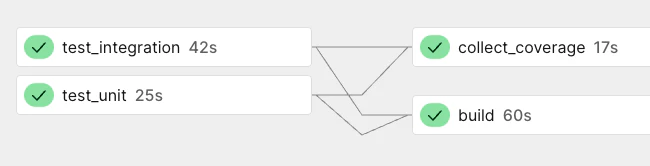
テストやビルドの実行時間が長くなってきたら、軽量なリント・型チェックを先行実行し、通過後にテストやビルドを実行するfan-outパターンも検討しましょう。
CIは「どんなフィードバックが欲しいか」で設計しよう
このようにCIの定義ファイルを少し書き換えるだけで、エラーが起きた時の原因調査や修正作業の開始地点が大きく変わります。「CIで実行したいタスクはどれか?」の整理だけでなく、「CIでエラーが起きた時、どんな情報・フィードバックがあると嬉しいか」についても考えてみましょう。
もしCIの実行履歴を見て「CIが失敗した」ことしかわからない場合、今回の記事を参考に「どのコマンドが失敗したかを見るようにできないか?」を考えてみましょう。また、依存関係のない(直行性のある)ジョブを並列実行することで、フィードバックの視点や種類を増やすことにも挑戦してみましょう。