パイプラインの実行時間が長くなってきたとき、「全体的に遅い」という認識のまま改善に着手するケースは少なくありません。しかし実際には、ボトルネックはワークフロー内の特定の少数のジョブに集中していることがほとんどです。
CircleCI の Insights ダッシュボードを使うと、ワークフローやジョブの実行時間・成功率・クレジット消費量を時系列で確認できます。本記事では、Insights を使ってボトルネックジョブを特定し、1 つの改善施策を実行して効果を数値で確認するまでの手順を紹介します。
Insights はクレジットの正確な報告ツールではありません。正確なクレジット消費量を確認する場合は、CircleCI の Plan Overview ページを使用してください。
Insights でCIのパフォーマンスを調査する
Insights ページはCircleCIダッシュボードにあるサイドバーの「Insights」メニューから移動できます。
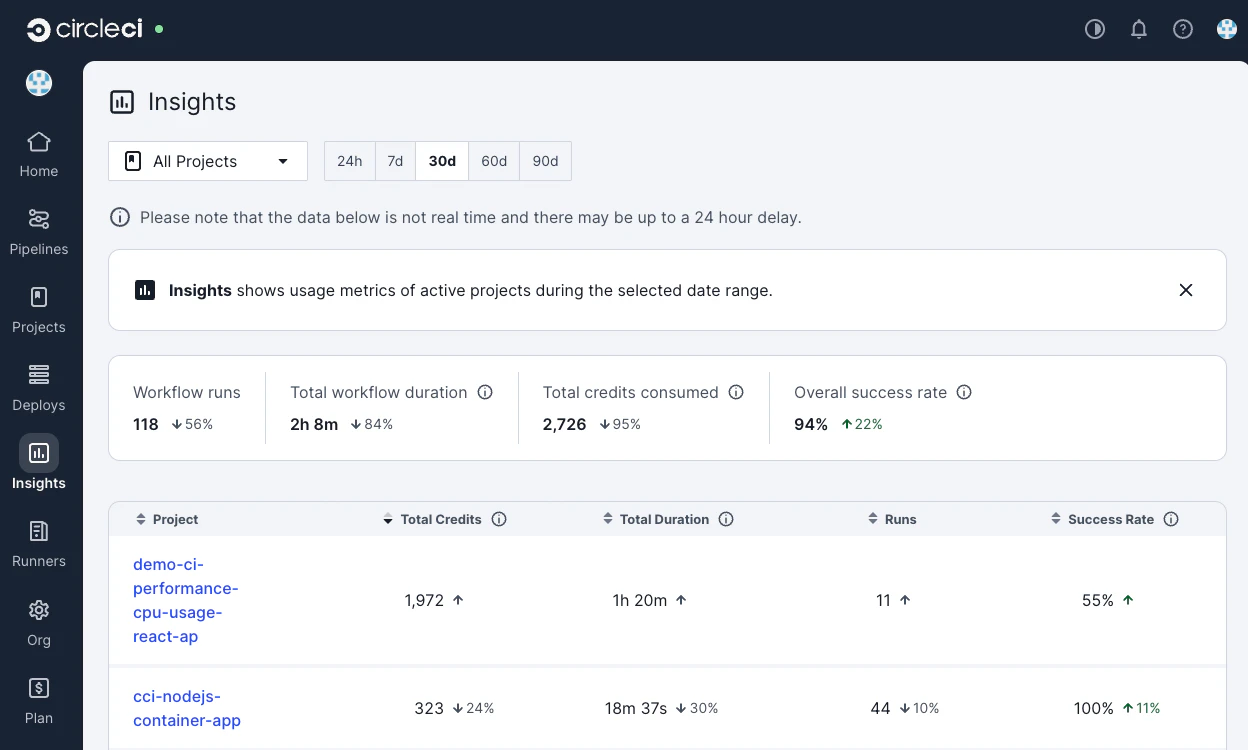
プロジェクトごとの実行時間や成功率などが記載されていますので、Total Durationの大きいものや、すでに「パイプラインが遅い」と問題視され始めているプロジェクトを見つけて詳細ページに移動しましょう。
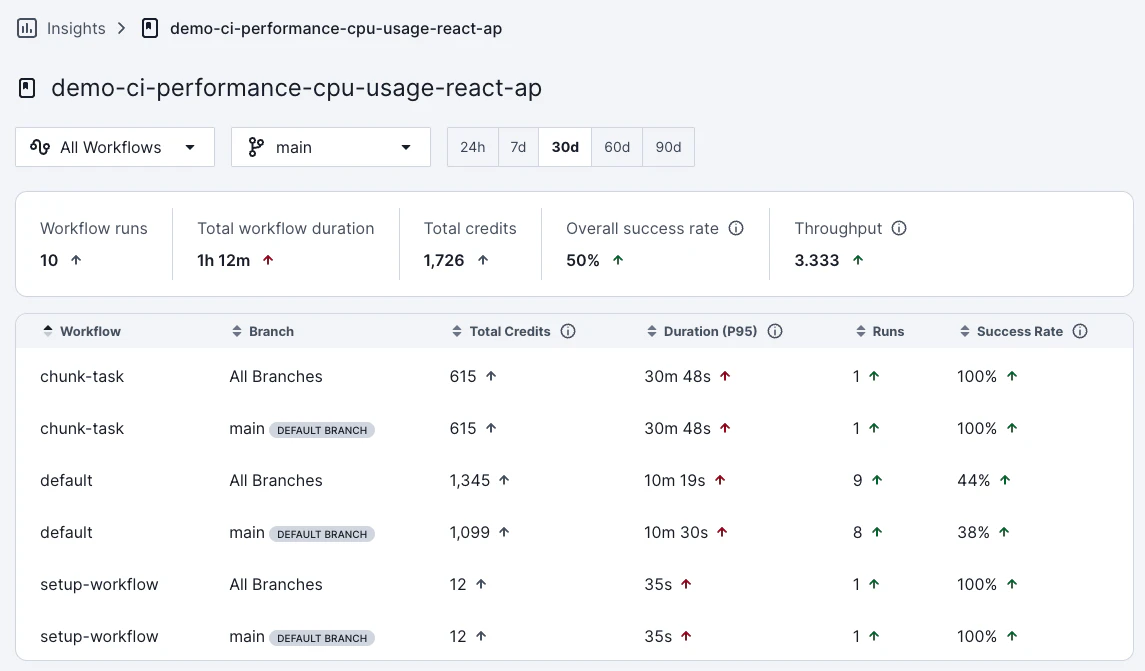
詳細ページではワークフローが一覧表示されています。ここでは各ワークフローの実行時間(P95)、成功率、クレジット消費量などが表示されています。時間範囲は 24 時間、7 日、30 日、60 日、90 日から選択できます。Insights のデータはリアルタイムではなく、最大 24 時間の遅延がある点に注意してください。
P95 duration で最も遅いワークフローを選ぶ
ワークフロー一覧を P95 duration で並べ替えてみましょう。P95 duration は、直近の実行のうち 95% がその時間以内に完了したことを意味する指標です。たとえば P95 が 12 分であれば、実行の 95% は 12 分以内に完了しており、残り 5% がそれより長くかかっています。
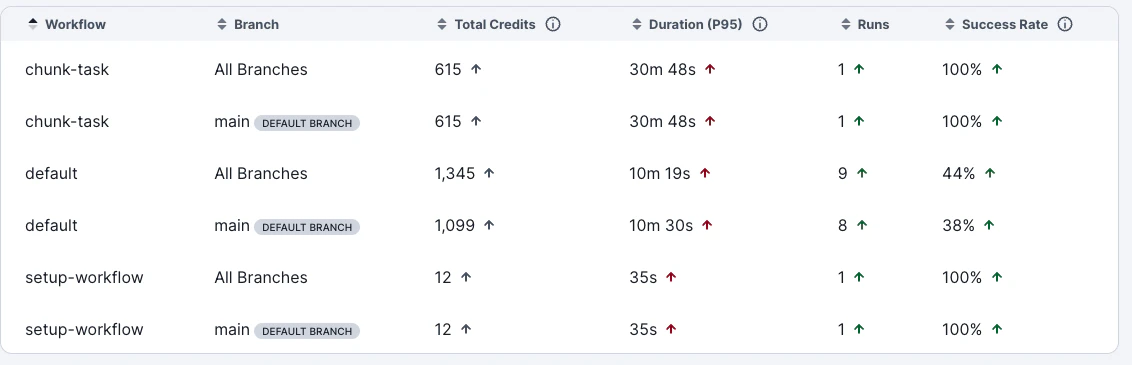
数字の右側に上向きまたは下向きの矢印が表示されています。これは前期間と比較して増加したか減少したかを表しています。つまり「数字が大きく、上向きの矢印が表示されているワークフロー」はテストなどの実行時間が増加傾向にある要注意なワークフローといえます。
また、デフォルトブランチと全ブランチの2つでワークフローを比較できます。これにより「開発フローの中で一時的な問題 or 本番リリース後に起こりうる問題」なのか「現在進行形でプロジェクトにて発生している問題」なのかの切り分けが可能です。
ジョブ単位に分解してボトルネックを特定する
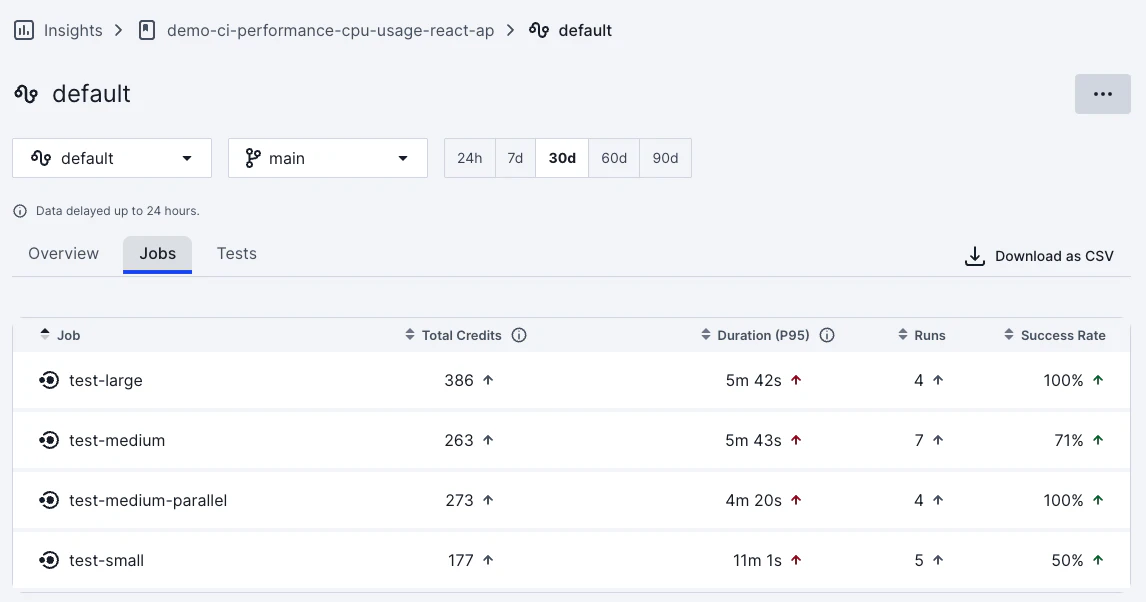
調査したいワークフローを特定し、詳細画面を開きましょう。Jobsタブをクリックすると、そのワークフローを構成する各ジョブの実行時間が表示されます。
ワークフロー全体の実行時間は、クリティカルパス上で最も長いジョブによって決まります。たとえば以下のようなワークフローがあるとします。
[lint] ← 30秒
↓
┌──┴──┐
↓ ↓
[test] [build] ← test: 8分 / build: 2分
↓ ↓
└──┬──┘
↓
[deploy] ← 1分
この場合、ワークフロー全体の実行時間は約 9 分 30 秒ですが、そのうち 8 分は test ジョブが占めています。build や deploy を高速化しても全体への効果は限定的であり、test ジョブの改善がワークフロー全体の短縮に直結します。
Insights のジョブ一覧で各ジョブの P95 duration を確認し、全体の実行時間に占める割合が大きいジョブを特定してください。
ボトルネックジョブの「なぜ遅いか」を診断する
ボトルネックジョブを特定したら、そのジョブの詳細画面で「なぜ遅いか」を診断します。診断を行うため、実際に実行されたワークフローの履歴をチェックしましょう。Overviewタブに移動すると、過去のワークフロー実行履歴が実行時間ベースの棒グラフで表示されています。
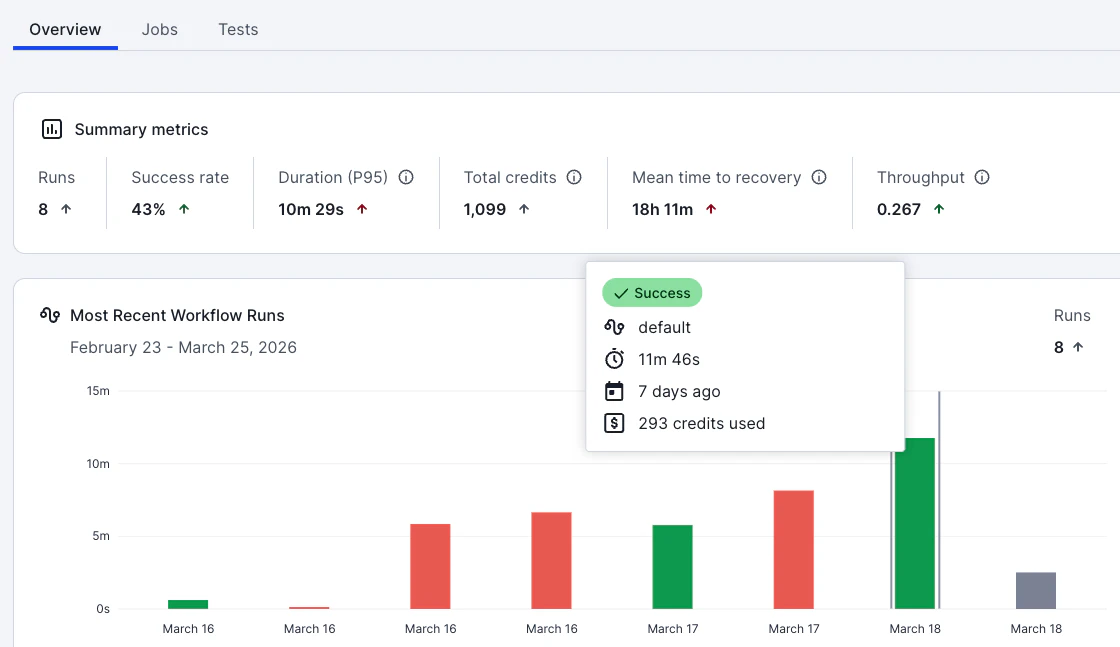
実行時間が長いジョブなどを特定し、グラフをクリックしましょう。クリックするとワークフローの実行結果詳細ページに移動します。
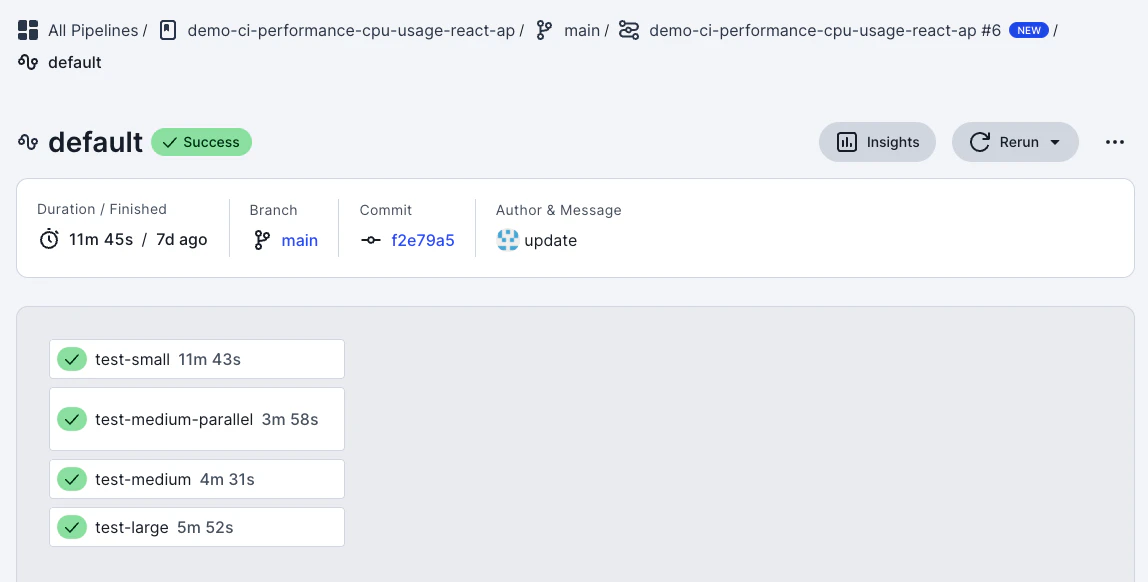
ここで先ほど調査対象に決めたジョブをクリックしましょう。ジョブの詳細画面に移動します。
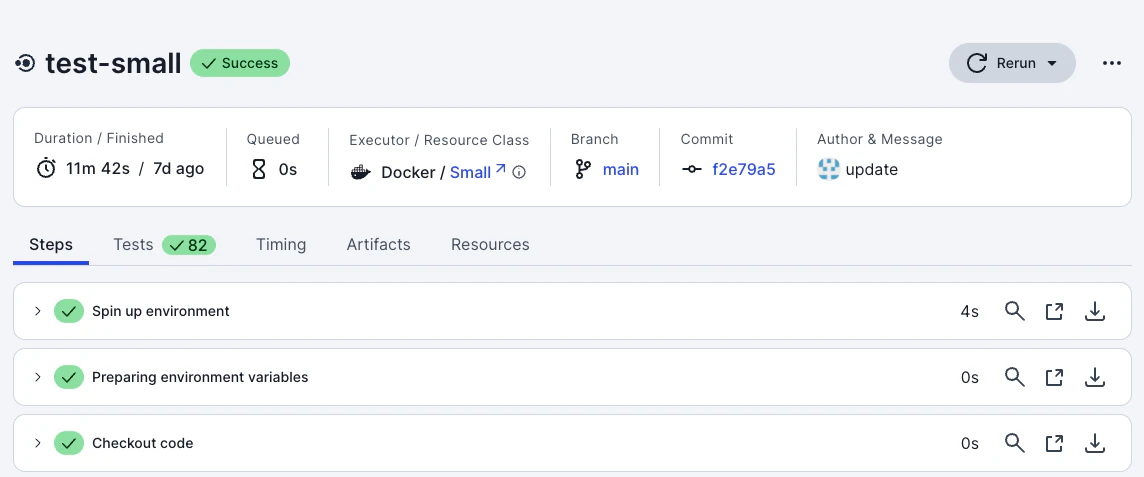
CircleCI のジョブ詳細画面では、ステップごとの実行時間や Resources タブでの CPU/メモリ利用率を確認できます。
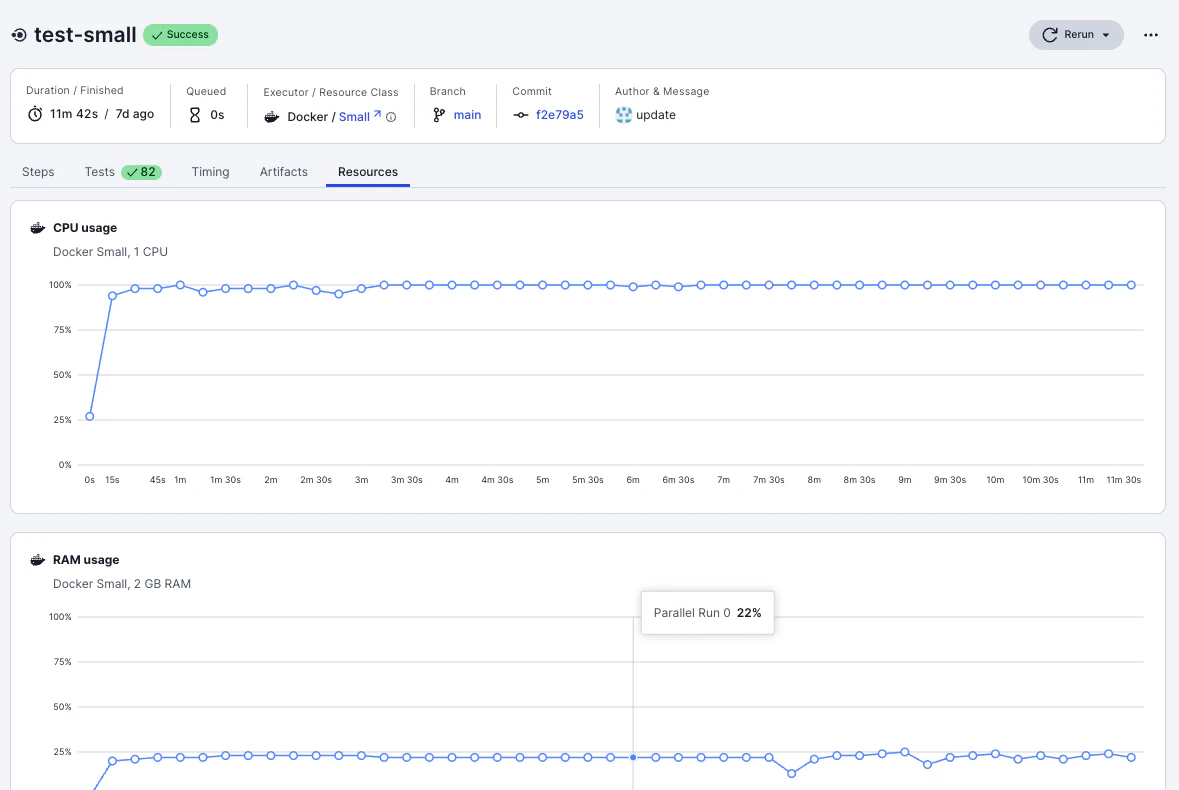
このスクリーンショットの例では、時間がかかっている理由は明白です。「CPU Usage」がほとんどの時間で100%に張り付いていることがわかります。つまりこのジョブを実行するランナー(Docker Small)がスペック不足であることで遅延につながっています。
このケースの対策はとてもシンプルです。.circleci/config.ymlを編集し、該当ジョブのresource_classを変更してください。
jobs:
build:
docker:
- image: cimg/node:20.11
+ resource_class: medium # smallから変更: CPU利用率100%のため
steps:
- checkout
- run:
name: Build
command: npm run build
small(1 CPU)から large(4 CPU)やmedium(2 CPU)に変更することでジョブを実行するに十分な環境を提供できる可能性があります。
実際にmediumへスケールアップした例がこちらです。CPU Usageはセットアップ時のみ100%ながらもほとんど50%前後に落ち着きました。また、実行時間も11分半から4分半へと短縮されています。
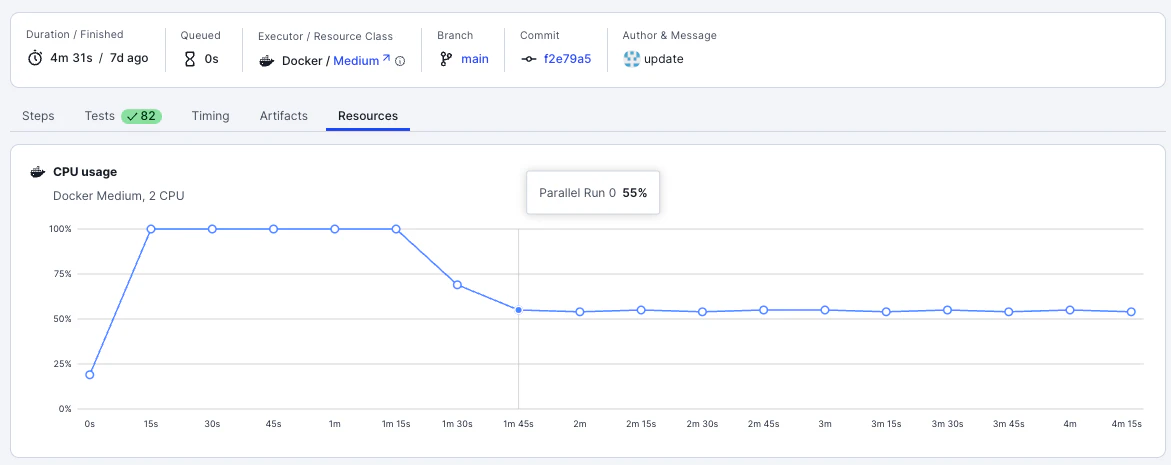
このように、CIジョブを実行するために必要十分な実行環境を提供できているかどうかをチェック・監視し最適化することが、快適なCI / CD環境を提供するためには欠かせません。
ジョブの Steps から更なる改善ポイントを特定する
「CPUやRAMに問題はないけれども、ジョブの実行時間が長い」というケースももちろん存在します。そんな時はジョブの Steps タブを調べてみましょう。
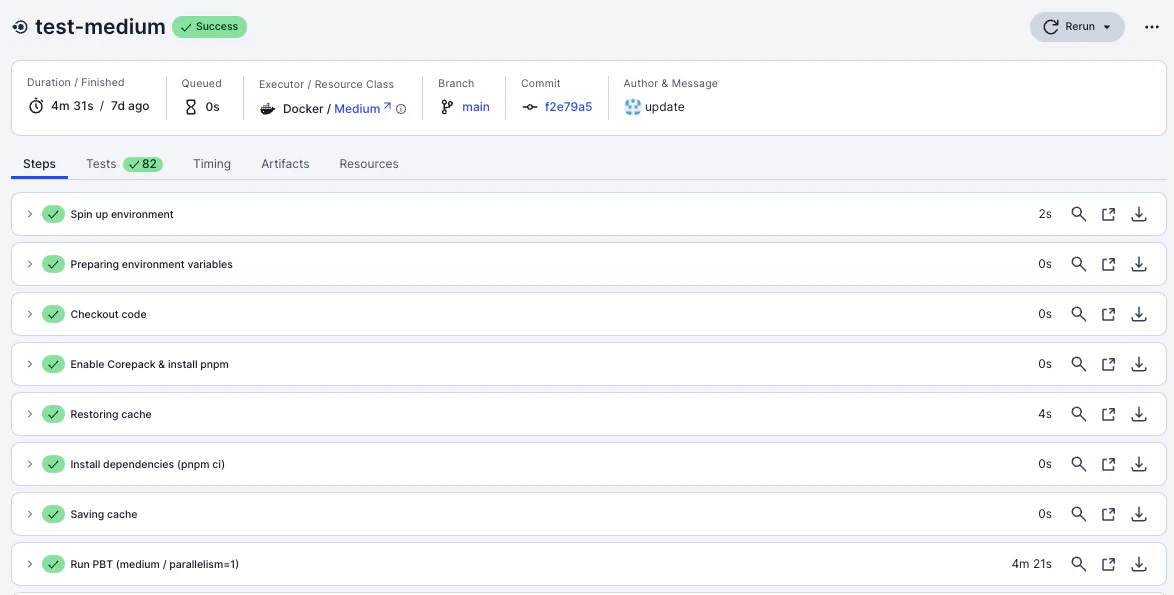
ここでは依存関係のダウンロードやテスト・リントなど、ステップごとの実行時間や標準出力されたログが記録されています。このステップを調査することで、例えば次のような改善案を見つけることができます。
1: テストの実行戦略を変更して高速化する
ステップごとの時間内訳で「Run tests」のようなテスト実行ステップが大部分を占めている場合、テストを並列実行することで大幅な短縮が見込めます。CircleCI の test splitting 機能を使うと、テストファイルを複数のコンテナに自動分割して並列実行できます。
jobs:
test:
docker:
- image: cimg/node:20.11
parallelism: 4 # 4コンテナで並列実行
steps:
- checkout
- run:
name: Install dependencies
command: npm ci
- run:
name: Run tests with splitting
command: |
mkdir -p test-results
circleci tests glob "src/**/*.test.ts" | circleci tests run --command="xargs npx vitest run --reporter=junit --outputFile=test-results/results.xml" --verbose --split-by=timings
- store_test_results:
path: test-results
circleci tests run は、テスト分割に加えて「失敗したテストのみを再実行する」機能にも対応しています。--command フラグにテスト実行コマンドを渡すことで、分割とテスト実行が 1 ステップで完了します。store_test_results を設定することで、各テストファイルの実行時間が CircleCI に記録され、2 回目以降は過去の実行時間に基づいて各コンテナの合計実行時間が均等になるよう最適化されます。
テスト分割の詳細な設定方法については、Test splitting and parallelism を参照してください。タイミングデータに基づく分割を正しく動作させるには、JUnit XML の <testcase> 要素に file 属性が含まれている必要があります。テストフレームワークの JUnit レポーター設定を確認してください(例: jest-junit の場合は JEST_JUNIT_ADD_FILE_ATTRIBUTE='true' が必要です)。
また、CircleCIのtest splitting 機能を使った場合、Timingタブを見ることで並列実行されたジョブごとの実行時間などもモニタリングできます。
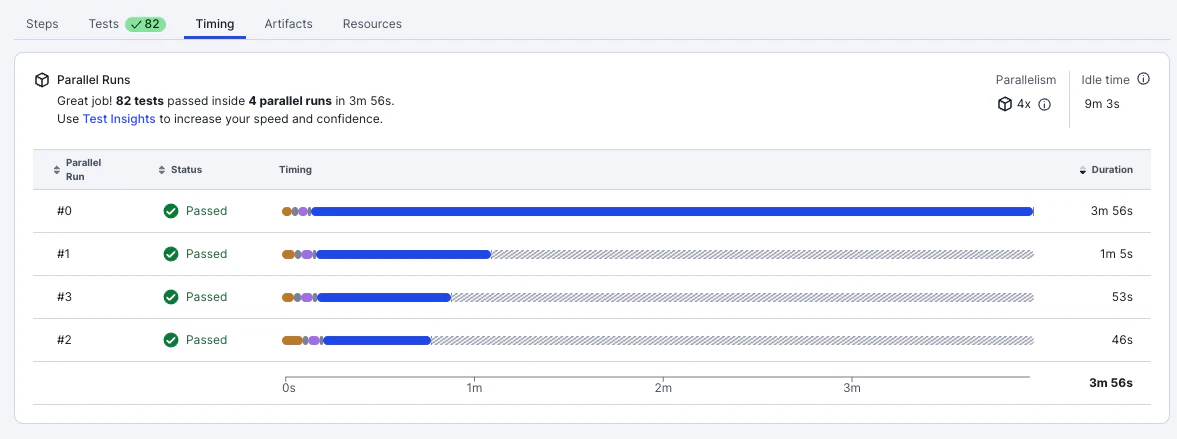
基本的には実行回数が増えるに従ってCircleCI側で最適化が行われます。しかし並列実行の数を増やすべきか減らすべきかなどの判断については、Timingタブの情報などをもとに検証を進めることをお勧めします。
2: キャッシュを活用して高速化する
ステップごとの時間内訳で「Install dependencies」のようなステップが数分を占めている場合、依存関係のキャッシュが設定されていない可能性があります。npm ci や pip install で毎回すべての依存関係をダウンロードしているのであれば、キャッシュを導入することで、2 回目以降の実行時間を大幅に短縮できます。
Node.jsでnpmを利用する場合の例は以下のとおりです。
jobs:
test:
docker:
- image: cimg/node:20.11
steps:
- checkout
+ - restore_cache:
+ keys:
+ - deps-v1-{{ checksum "package-lock.json" }}
+ - deps-v1- # 部分一致のフォールバック
- run:
name: Install dependencies
command: npm ci
+ - save_cache:
+ key: deps-v1-{{ checksum "package-lock.json" }}
+ paths:
+ - node_modules
- run:
name: Run tests
command: npm test
なお、CircleCIが公開している言語別のOrbを利用している場合、キャッシュ管理についてはOrb側に任せることができます。キャッシュキーやパッケージマネージャー別の考慮を開発チームが行わなくても良くなりますので、なるべくOrbを使うことをお勧めします。
version: 2.1
orbs:
node: circleci/node@7.2.1
jobs:
build_app:
executor: node/default
resource_class: small
steps:
- checkout
- node/install-packages:
pkg-manager: npm
- run:
name: Build app
command: npm run build
もしコンテナのビルドなどを行っている場合は、Docker Layer Caching(DLC)を使ってビルド時間を短縮することも可能です。
変更後の効果を測定する
config.yml の変更をプッシュした後、数回の実行が完了するのを待ってから Insights で効果を確認します。
Insights でワークフローまたはジョブの P95 duration を確認し、変更前の値と比較してください。Insights のデータは最大 24 時間の遅延がある場合があるため、変更直後ではなく翌日以降に確認することを推奨します。
確認すべき指標は以下の 3 つです。
- P95 duration: ジョブの実行時間が短縮されたか
- Success rate: 変更による副作用でテスト失敗率が増加していないか
- Credits: クレジット消費量が期待通りに変動しているか(resource_class 変更の場合)
まとめ
パイプラインの遅延を改善するには、「全体的に遅い」という認識から「このジョブのこのステップが遅い」という特定にまで解像度を上げることが出発点です。Insights ダッシュボードを使った「特定→診断→改善→効果測定」のサイクルを繰り返すことで、パイプライン全体のパフォーマンスを継続的に改善できます。
今回はジョブの実行時間に焦点を当てましたが、Insights では成功率やクレジット消費量のトレンドも確認できます。フレーキーテストによる成功率低下やリソースクラスの過剰割り当てによるコスト増加など、他の最適化ポイントもデータから発見できます。
次のステップ
Insights で自分のパイプラインを診断する手順は以下のとおりです。
- CircleCI Web App のサイドバーから Insights を開く
- P95 duration で最も遅いワークフローを 1 つ選択する
- ジョブ一覧でボトルネックジョブを特定する
- Resources タブとステップの時間内訳から原因パターンを診断する
- config.yml に 1 つだけ変更を加え、翌日以降に Insights で効果を確認する
より詳しく学ぶ場合は以下のリソースを参照してください。
- Insights metrics glossary: Insights で使用されるすべての指標の定義
- Optimization reference: キャッシュ、ワークフロー、並列実行など最適化手法の一覧
- Resource class overview: resource_class ごとの CPU・RAM・クレジット消費量