ソフトウェア開発において、リリース作業に伴うリスクは多くのチームが直面する課題です。デプロイ後の障害発生、テストやチェックの網羅性、リリース作業の属人化など、リリースの信頼性に関わる懸念は尽きません。
この記事では、CI/CD の基本的な考え方と、それがリリースのリスクを低減する手段になる理由を解説します。すでに簡単な CI や CD を動かしている方も、改めて「なぜ必要なのか」を理解することで、自分のプロジェクトにおける障害やデグレリスクへの向き合い方が変わるはずです。
「頻度を減らせば安心」という誤解
リリースによる障害を避けるために、リリースの頻度を減らすというアプローチは直感的には理解できます。しかし、実際には逆効果です。
『入門 継続的デリバリー』(オライリー・ジャパン)では、このアプローチの問題点を次のように指摘しています。
1つ目は、このアプローチでは...最後のリリースから多くの変更が溜まると、意図しない重大な不具合が発生し、大幅なリリース遅延を発生させることに繋がる点です。

低頻度のリリースでは、1回のデプロイに含まれる変更が多くなります。変更量が増えるとバグ混入リスクも増加し、「どのコミットでバグが混ざったか」の特定や修正のための調査が困難になります。
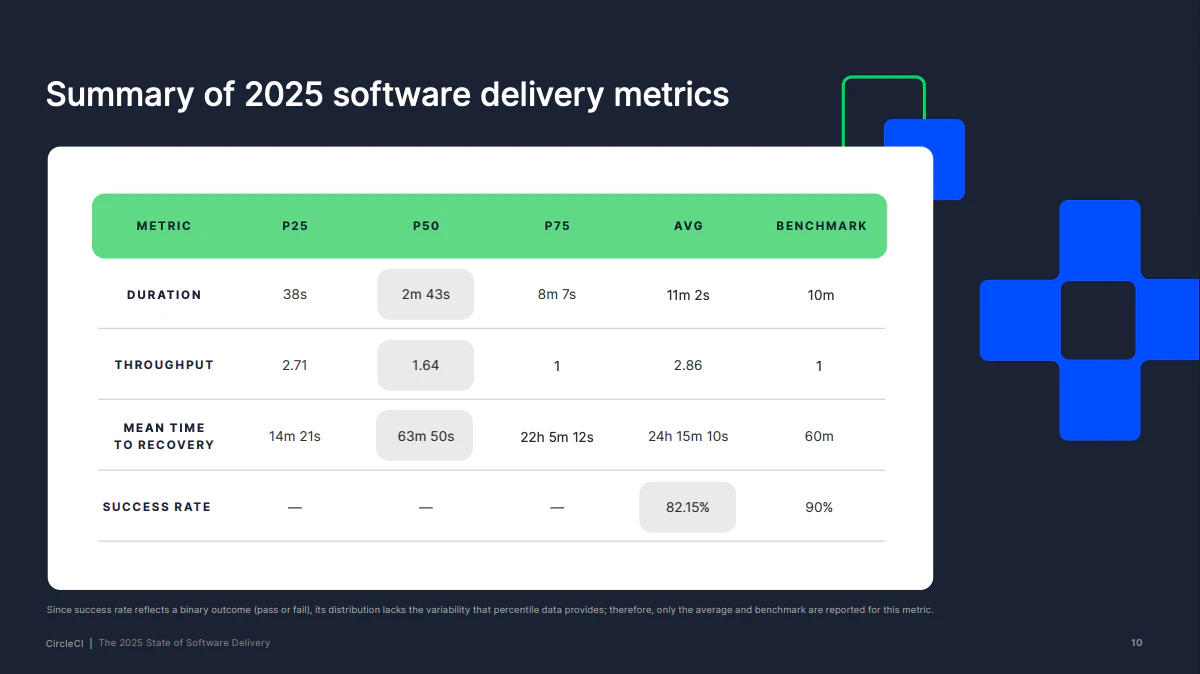
CircleCI の 2025 State of Software Delivery は、約 1,500 万のワークフローを分析した実測データに基づくレポートです。このレポートによると、高パフォーマンスチーム(上位 25%)は下位チームの 3 倍の速度でリリースし、ワークフロー完了速度は 5 倍速いという結果が出ています。さらに、障害からの復旧時間(MTTR)の中央値は約 64 分で、上位 25% のチームは 15 分未満で復旧できています。一方、下位 25% のチームでは MTTR が 22 時間超にまで膨らんでおり、パフォーマンス格差が顕著です。
頻度を減らすことで安心を得ようとするアプローチは、実際には問題を先送りし、より大きなリスクを抱え込むことになります。
リスクを低減してデプロイするための3つのアプローチ
リリースに伴うリスクを低減するアプローチは 3 つあります。
Feature Flag によるデプロイと機能リリースの分離
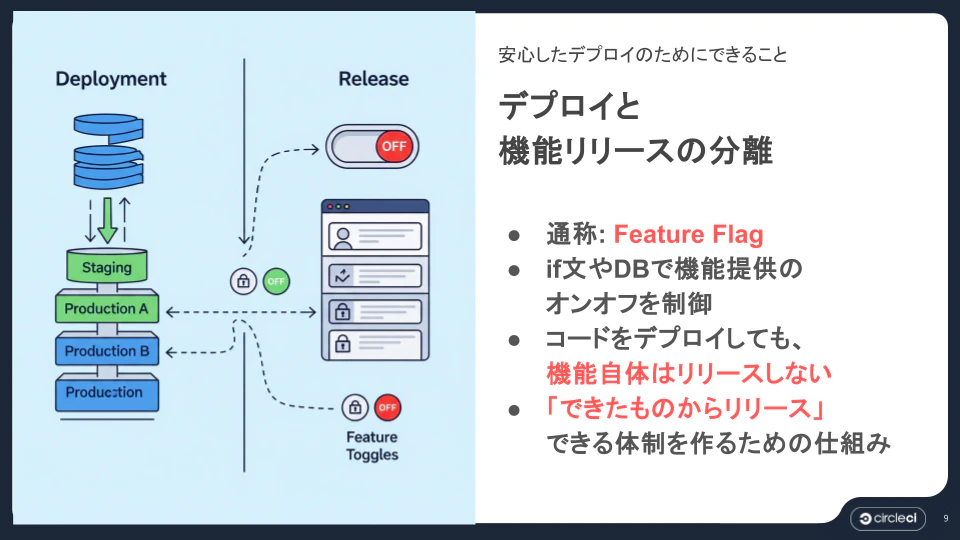
Feature Flag(フィーチャーフラグ)は、if 文や DB で機能提供のオンオフを制御する仕組みです。コードをデプロイしても、機能自体はリリースしないという状態を作れます。これにより「できたものからリリース」できる体制が整います。コードはあるが機能は OFF という状態でマージすることで、挙動を変えずに変更を本番環境に届けられます。
小さなマージ
土台となるリファクタリングや型定義から先に統合していくことで、巨大なプルリクエストやコンフリクトを回避できます。1 回のマージに含まれる変更が小さければ、問題が起きたときの原因特定も容易です。
自動検証(CI)
Push のたびに機械がチェックを実行し、常に動く状態をキープします。これが CI(継続的インテグレーション)の役割です。
これら 3 つのアプローチを組み合わせることで、細かく頻繁にコードをデプロイできる体制が整います。
CI/CD の役割 ― 機械的なミスをレビュアーに届けない
デプロイ頻度を上げると、プルリクエストの数が増えます。レビュアーの数が増えずにレビューの量だけ増えると、見落としリスクが増加し、障害発生につながります。
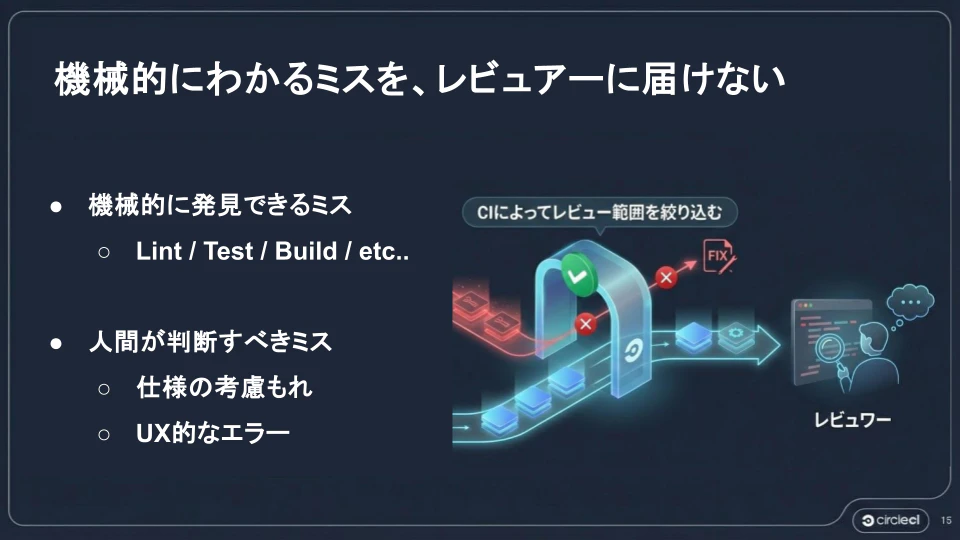
ここで重要なのは、レビューをボトルネックにしないことです。そのために、機械的に発見できるミスと人間が判断すべきミスを分離します。
Lint、Test、Build といった機械的に発見できるミスは、CI によって自動でチェックされます。仕様の考慮漏れや UX 的なエラーといった人間が判断すべきミスだけが、レビュアーの手元に届く形になります。
CI は「常に動く状態をキープする」ためのシグナルを提供する仕組みです。CD は「ボタン 1 つでリリース可能な状態を維持する」ことを目指すプラクティスです。この 2 つが整備されることで、頻繁にリリースできる体制が実現します。
CircleCI で始める CI/CD
CircleCI はクラウドベースの CI/CD プラットフォームです。GitHub や Bitbucket、GitLab など複数のリポジトリサービスに対応し、タスクの条件や定義を YAML で管理できます。
CircleCI の構造は 3 つの階層で成り立っています。Pipeline は 1 回の Git Push で起動する全体の実行単位です。Workflow は Job の実行順序(直列・並列)を定義します。Job はビルドやテストなど、実際の作業単位です。
設定ファイルの 5 つの要素
CircleCI の設定ファイル(.circleci/config.yml)は、5 つの要素から始めます。以下に最小構成の例を示します。
version: 2.1
jobs:
build:
docker:
- image: cimg/node:22.0
steps:
- checkout
- run: npm install
- run: npm test
workflows:
build-and-test:
jobs:
- build
このコード例の各要素について説明します。
- version: 設定ファイルの形式を指定します。現在は 2.1 で固定です。
-
jobs: 実行する作業を定義します。
buildやtestといった名前を付けて、それぞれの作業内容を記述します。 -
docker + image: 実行環境を指定します。
cimg/node:22.0と指定すれば、Node.js 22 がインストールされた環境でジョブが実行されます。 -
steps: 実行するコマンドを順番に記述します。
checkoutでコードを取得し、runでコマンドを実行します。 - workflows: ジョブの実行順序を定義します。上記の例ではジョブが 1 つだけですが、複数のジョブを定義した場合に直列・並列の実行順序を制御できます。
version は現在 2.1 で固定です。新規作成の場合は version: 2.1 を指定してください。
上記の例では、checkout でリポジトリのコードを取得した後、npm install で依存関係をインストールし、npm test でテストを実行しています。この最小構成をベースに、段階的にステップを追加していくことを推奨します。
Orbs による簡略化
Orbs は共有可能な CI/CD 設定パッケージです。CircleCI や SaaS ベンダーが公開しており、言語別に最適化された実行環境が用意されています。circleci/node や circleci/ruby といった Orbs を使えば、複雑な設定を数行で実装できます。

設定ファイルで詰まったら
公式ドキュメントの Configuration Reference を参照してください。また、VS Code 拡張を使えば、構文チェックやコード補完、ローカルからのテスト実行が可能です。タイポや必須項目の不足を確認しながら、少しずつ設定を追加していくことを推奨します。
CircleCIを使って無料でCI/CDを開始する
CI/CD を導入するために、まずは無料プランからお試しください。
CircleCI アカウントを作成し(無料)、デモプロジェクトを fork して、パイプラインが動くのを確認してください。まずは最初のビルドを成功させてみることが重要です。
自分のプロジェクトに導入する場合も、現在では生成AIによる設定ファイル生成機能がベータ版ながら提供されています。以下の記事を参考にテストやリント・ビルドなどが動くかをチェックしてみましょう。
初学者が躓きやすいポイント
最初から完璧なパイプラインを構築しようとすると、全テストの一括追加、カバレッジ目標の設定、すべての自動化を一度に実現しようとする方向に陥りがちです。これらはよくある失敗パターンです。
推奨するアプローチは、最初はビルドが通るだけで OK とし、速いテストから段階的に追加していくことです。カバレッジの計測は後から導入し、手動で仕組みを理解してから自動化に進んでください。小さく始めて、継続的に改善していくことが重要です。
『入門 継続的デリバリー』では、この原則を次のように表現しています。
できるだけ早く、多くのシグナルを得る
完璧なパイプラインを最初から構築する必要はありません。まずは「何か壊れたら気づける」という状態を作ること。そこから少しずつ改善を重ねていくことで、頻繁にリリースできる体制が整っていきます。
まとめ
リリースによる障害リスクや影響度合いは、「頻度を減らしてまとめてやる」ほうが大きくなります。長くとも 1 ヶ月以内にはコードをリリースする体制を目指し、そのために開発の粒度や完了判定の調整から始めてください。
頻度を増やすためには、自動チェックが不可欠です。CI および CD を整備することで、頻度の増加に耐えられる体制を構築できます。
今日からできることは 2 つあります。1 つ目は CircleCI でデモプロジェクトを動かしてみること。2 つ目は自分のプロジェクトに config.yml を追加してビルドが通るか確認することです。この小さな一歩が、リリース作業を特別なイベントから日常的なオペレーションへ変化させる第一歩になります。