はじめに
最近のお仕事ではクローラーを開発するためのフレームワークである scrapy を使ってクローラーの開発をしています。
かつて趣味でクロールをやってみていたとき は色々なコマンドを組み合わせてなんとかやっていたのですが、それと比べると scrapy は遥かに強力で便利なフレームワークだなと日々実感しています・・・。
例えば、 https://blog.scrapinghub.com/ をクロールして投稿されている記事のタイトルとURLをページングもしながら全て取得する処理はたったこれだけのコードで書けます。
def parse(self, response):
for post in response.css('div.post-item'):
yield Page(
url=post.css('div.post-header h2 a::attr(href)').extract_first(),
title=post.css('div.post-header h2 a::text').extract_first()
)
next_page = response.css('div.blog-pagination a.next-posts-link::attr(href)').extract_first()
if next_page:
yield scrapy.Request(next_page, self.parse)
さて、そんな便利な scrapy なのですが、 クロールして抽出したデータをどこにどうやって格納するか?はこのフレームワークの範疇ではなく面倒を見てくれません。
DB にデータを保存するとかをどのように実装したらいいか、恐らく scrapy ユーザーの方々は同じような課題にぶつかるはずですが、ググってもあまり情報が出てこないようでした。
そこで今回は、scrapy で抽出したデータを ORM を使って DB に保存するやり方を試行錯誤してみた のでそれについて書きたいと思います。
ここからは scrapy を何となくしている人向けに書いてしまいます。
scrapy を使ったクローラーの実装についての基本的なところが知りたい方はこちらの記事も読んでみてください。↓↓↓↓
10分で理解する Scrapy
scrapy について簡単におさらい
さて、それではまず scrapy のアーキテクチャーについておさらいします。
scrapy の説明でよく引用される図なのですが、公式ドキュメントにはこのようなアーキテクチャー図が掲載されています。
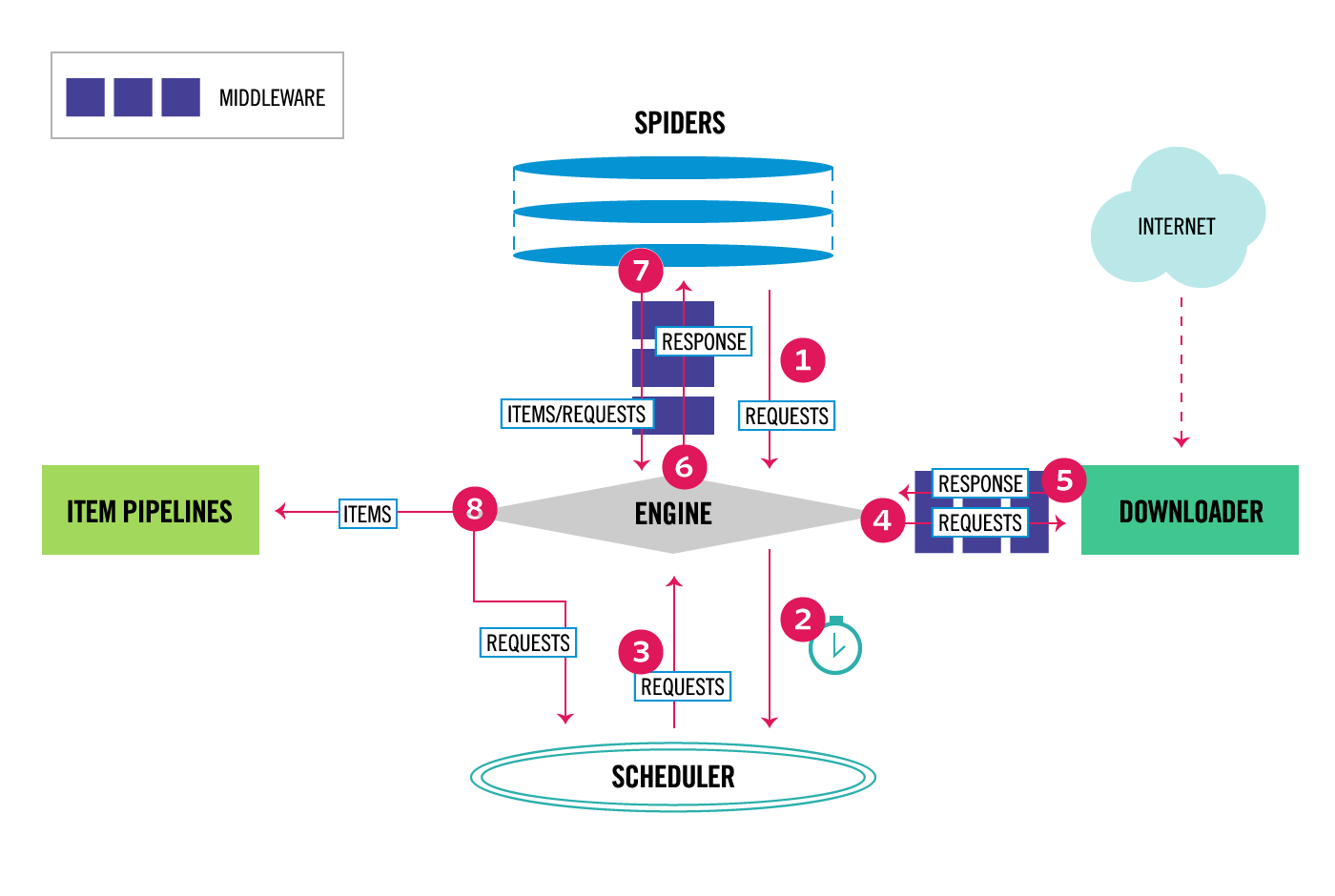
scrapy は クロールの並列実行や抽出したデータの流れを制御することがメイン となっているので、HTML のパースや抽出したデータのハンドリングなどは自由度が高くカスタマイズができるような設計になっています。
データのチェックや出力の処理を入れるための item pipeline という枠だけ用意されており、あとはそれぞれ好きに使ってくれというスタンスです。
※上記の構成図では (8) から左側の ITEM PIPELINES と書かれているところです。
scrapy を使う上で感じたつらみ
色々な情報をググってみると、独自の pipeline を実装してその中で DB への接続や SQL の実行をしている例がいくつか見つかります。
例えば、こちらの記事の実装が非常にシンプルでわかりやすいです。
https://ohke.hateblo.jp/entry/2018/07/07/230000
これと同じようなやり方で実装をしていたのですが、何らか DB に関わる処理が増えたりすると mysqlclient を使って DB とのコネクションやトランザクションの処理を1つ1つ書くことが結構つらく感じてきます。
また、クローラーを継続して開発し続けていくことを考えると、多くの Web フレームワークで一般的になってきているようにモデルの定義と DB のスキーマの定義もコードで管理したくなってきます。
そしていつしか scrapy でも ORM が使えたら嬉しいのになああああ と思うようになっていました。
scrapy で ORM を使おう!
ざっくりとこんな感じのことがやりたかったのです。
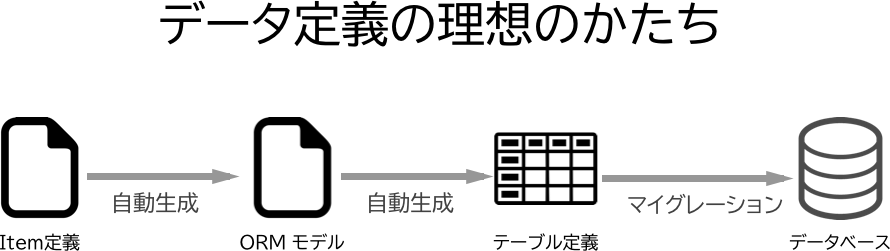
理想は scrapy の Item か ORM のモデルを定義すればあとは自動生成してくれると非常に嬉しいですよね。
scrapy の公式ドキュメントでは、 scrapy の item を拡張して Django の model と連携できる DjangoItemという プラグインが紹介されています。
https://github.com/scrapy-plugins/scrapy-djangoitem
ただこのプラグインでは、Django の model を定義した上で scrapy の item も同じ項目で2重に定義
する必要があったり、ベースとなる Django のプロジェクトを作る必要があったりと、やりたいことのイメージとちょっと違いました。
なので普通に ORM を組み込むやり方を探すことにしました。
python の ORM ライブラリたち
これまで Python の ORM は Django のものと Peewee を少ししか使ったことがなく、他にどんな ORM が使われているのかを awesome-python で見てみました。
https://github.com/vinta/awesome-python#orm
ざっとそれぞれ単体でどんな感じかを使ってみたところ、Orator がセットアップも簡単でシンプルに使えそうだったのでこれを使ってみることにしました。
※あとドキュメントが他のと比べるとめちゃカッコいいというところも気に入りました
scrapy に Orator を組み込む
いろいろと試行錯誤をした結果無事 Oractor を使って求めていた処理を実現できるようになったので、いくつかポイントを解説していきます。
Item の定義
まず、保存したい対象の scrapy item を以下のように定義しました。
__table_name__ __uniq_fields__ は pipeline の処理で使うように新たに追加したクラス変数ですが、そのほかのフィールドの定義は通常の item を定義する時と同じです。
class Page(scrapy.Item):
__table_name__ = 'pages'
# define the uniq field names for your items here like: (Optional)
__uniq_fields__ = ['url']
# define the fields for your items here like:
url = scrapy.Field()
title = scrapy.Field()
Pipeline の定義
ORM の処理を差し込む箇所はこれまで通り Pipeline に実装しました。
そしてこの処理の中で item に定義されている field を見て、動的に Model クラスを生成し(!) Oractor の Model オブジェクトを作成することで通常と同じように扱うようにしました。
class ScrapyOrmPipeline(object):
def process_item(self, item, spider):
_table_name = getattr(item, '__table_name__', None)
_uniq_keys = getattr(item, '__uniq_fields__', {})
# Generate orator model class.
model_class = generate_model_class(type(item).__name__, item.keys(), _table_name)
# If there is a record having same keys return it, if not create new record, doing like "upsert".
model = model_class.first_or_new(**{k: item[k] for k in _uniq_keys})
# Set model attributes from item.
for attr in item.keys():
setattr(model, attr, item[attr])
model.save()
return item
Model クラスの動的生成
generate_model_class ではこのように type を使ってクラスを定義しています。
def generate_model_class(model_name: str, columns: List[str], table_name: str = None):
"""
Generate make_item.py model class in dynamically.
:param model_name:
:param columns:
:return:
"""
cls = type(model_name, (Model,), {'__fillable__': columns, '__table__': table_name})
return cls
Orator では Model クラスを以下のように定義するのですが、 generate_model_class では item の Page に対応する以下と同じ Model クラスを動的に生成しているということです。
class Page(orator.Model):
__fillable__ = ['url']
__table__ = 'pages'
マイグレーションファイル
理想をいうと item の定義からマイグレーションファイルを自動生成するようにしたかったのですが、そこまでは難しそうだったのでまずは通常通りマイグレーションファイルを作ることにしました。
Page モデルに対応するテーブル作成のマイグレーションファイルは Oractor ではこう書きます。
class CreatePagesTable(Migration):
def up(self):
"""
Run the migrations.
"""
# To set other type column,
# See https://orator-orm.com/docs/0.9/schema_builder.html#adding-columns
with self.schema.create('pages') as table:
table.increments('id')
table.string('url').unique()
table.string('title')
table.timestamps()
def down(self):
"""
Revert the migrations.
"""
self.schema.drop('pages')
マイグレーションファイルを作成したら以下のコマンドを実行すると DB に反映されます。
$ orator migration
通常の Oractor では以下のように make:model コマンドに --migration オプションをつけるとマイグレーションファイルの雛形を自動で生成してくれます。
$ orator make:model <モデル名> --migration
Item クラス & マイグレーションファイル の雛形の自動生成
make:model コマンドを参考に oractor コマンドを拡張して、 item クラスの雛形と対応するマイグレーションファイルを自動生成するようにしてみました。
$ ./make_item.sh NewItem
上記を実行すると以下のように Item クラス・マイグレーションファイルの雛形が生成されます。
Item クラス (NewItem)
import scrapy
class NewItem(scrapy.Item):
__table_name__ = 'models'
# define the uniq field names for your items here like: (Optional)
# __uniq_fields__ = []
# define the fields for your items here like:
# name = scrapy.Field()
マイグレーションファイル
from orator.migrations import Migration
class CreateNewItemsTable(Migration):
def up(self):
"""
Run the migrations.
"""
with self.schema.create('new_items') as table:
table.increments('id')
table.timestamps()
def down(self):
"""
Revert the migrations.
"""
self.schema.drop('new_items')
ディレクトリ構成
scrapy プロジェクト crawlers の配下に、 scrapy アプリケーションの crawlers と oractor のディレクトリ database を配置しました。
Item クラスは前述のカスタマイズした oractor のコマンドで自動生成するようにしたので、 database の配下に置くようにしました。
crawlers/
├── crawlers
│ ├── __init__.py
│ ├── middlewares.py
│ ├── orm.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ ├── __init__.py
│ └── scraping_hub_spider.py
├── database
│ ├── __init__.py
│ ├── commands
│ │ ├── __init__.py
│ │ ├── items
│ │ │ ├── __init__.py
│ │ │ ├── make_command.py
│ │ │ └── stubs.py
│ │ └── make_item.py
│ ├── items
│ │ ├── __init__.py
│ │ └── page.py
│ ├── make_item.sh
│ ├── migrations
│ │ ├── 2018_12_18_143127_create_pages_table.py
│ │ └── __init__.py
│ ├── orator.yml
│ └── settings.py
└── scrapy.cfg
コード一式
今回説明したソースコードの一式はこちらのリポジトリに置いています。
https://github.com/Chanmoro/scrapy-orm
サンプルとして https://blog.scrapinghub.com/ をクロールして、投稿されているブログ記事の URL とタイトルを全て取得して mysql に保存するという処理を実装しています。
まとめ
さて、今回の記事では scrapy で item を DB で管理するために ORM の Oractor を組み込んでみた ということを書きました。
ささーっとやってしまったのでいろいろと細かいところで不足があると思いますが、 Oractor 以外の ORM を使っても同じようなやり方で実装できそうな気がしてきました。
理想は Item を定義するだけでマイグレーションファイルを全て自動生成してくれるようにできたら最高だなあと思うので、いろいろと試してみようと思うのでうまく行ったらお仕事にも使おうと思います。
それでは皆さんもくれぐれもクローリングは用法用量を守って正しくお使いくださいね。
ハッピースクレイピング!