Nextremer Advent Calendar 2017 3日目の記事です
Nextremer ではお手軽にGPUマシンを利用できる Shiva という機械学習の開発環境を構築しています
今回はその Shiva の開発に至った経緯とその仕組みをご紹介します

Shiva の開発にあたっては、昨年RettyのCTO樽石さんが公開された Retty流『2200万ユーザを支える機械学習基盤』の作り方 を大いに参考にさせて頂きました
このような貴重なノウハウを公開されていることは本当に素晴らしいですし、この記事がなければ私が Shiva を開発することはなかったです
そんな樽石さん、Rettyさんへの尊敬と感謝の思いを込めて、Nextremerの Shiva についてのノウハウを公開します!
Shiva 開発に至った経緯
Nextremer の研究開発PJでは深層学習を利用した自然言語処理、強化学習などの分野を扱っていますが、計算量が多い深層学習に欠かせないのがGPU環境です
正式なPJであれば予算を確保して個人用にGPUマシンを購入したり、クラウドのGPUインスタンスを利用していますが、全てのエンジニアが業務で深層学習に関わっているわけではなく、これまでは誰でもお手軽に使えるGPU環境は社内にありませんでした
そのため、サクッと実験したり闇研究したりのために「もっと気軽にGPU環境を使いたい!」という声がエンジニアやインターンの学生からちらほら上がっていました
また、研究に関わるメンバーやインターンは必ずしも全員ソフトウェアそのものに詳しいわけではないので、環境構築もそれぞれバラバラで時間がかかってしまっていました
機械学習環境のセットアップはライブラリによってpipでサクッとインストールできるものもあれば複雑なビルドが必要なものまで様々あります
そんな時に前述の樽石さんが書かれた記事を見て「こういうヤツがうちにもあればこの課題が解決できそうだ!」**「ていうか、かっこいいしやってみたい!」**と思い、当初はこの記事のアーキテクチャーの完コピを目標としてShivaの開発を始めました
Shiva とは
Concept
機械学習、深層学習のためのsandbox環境です
お手軽にセットアップ済みのGPU環境が利用でき、革新的なアプリケーションを生み出す try & error を繰り返すための環境として利用されることを想定しています
How to use
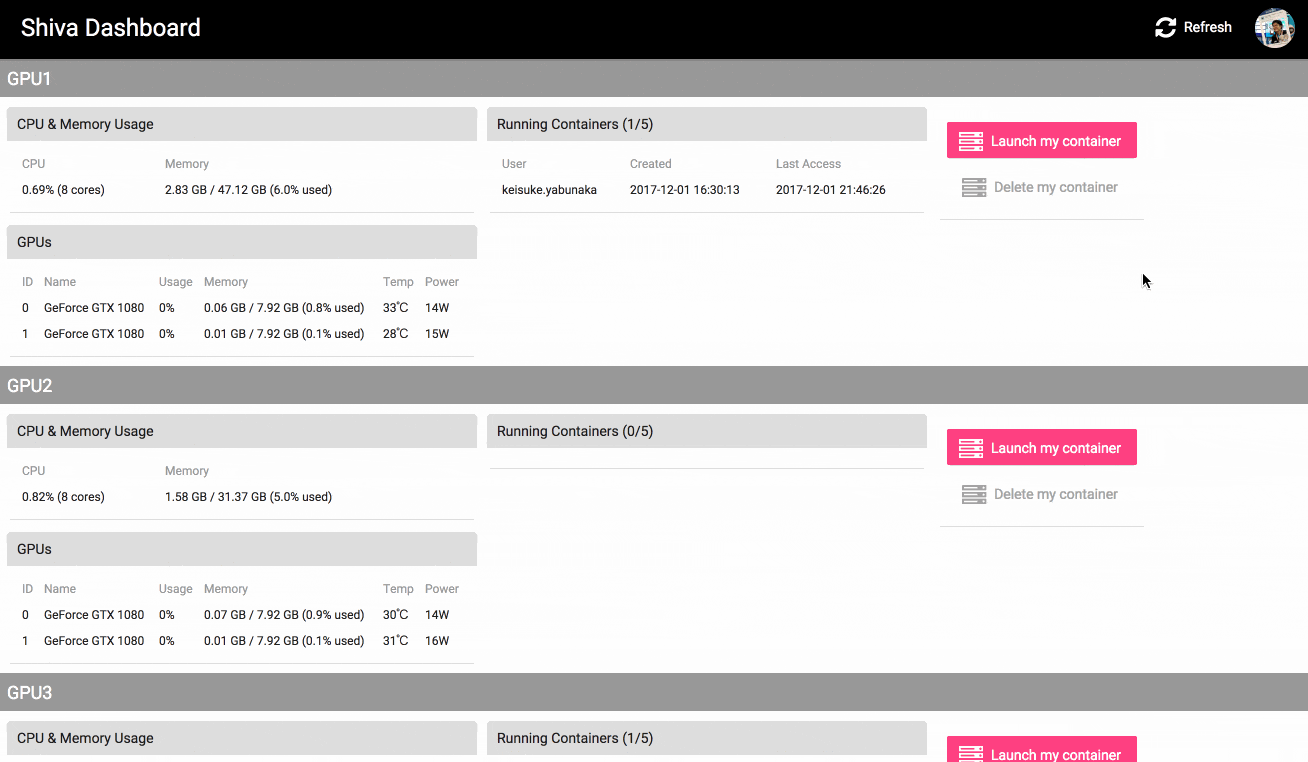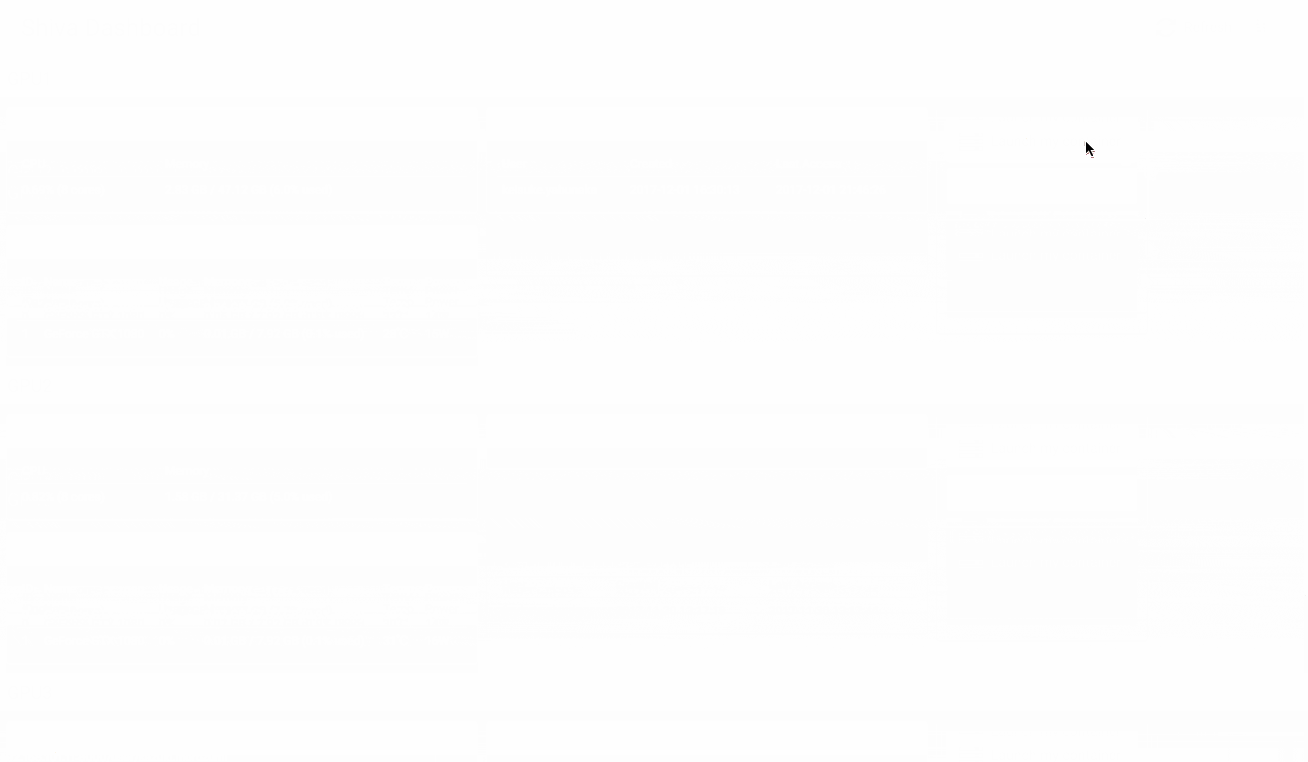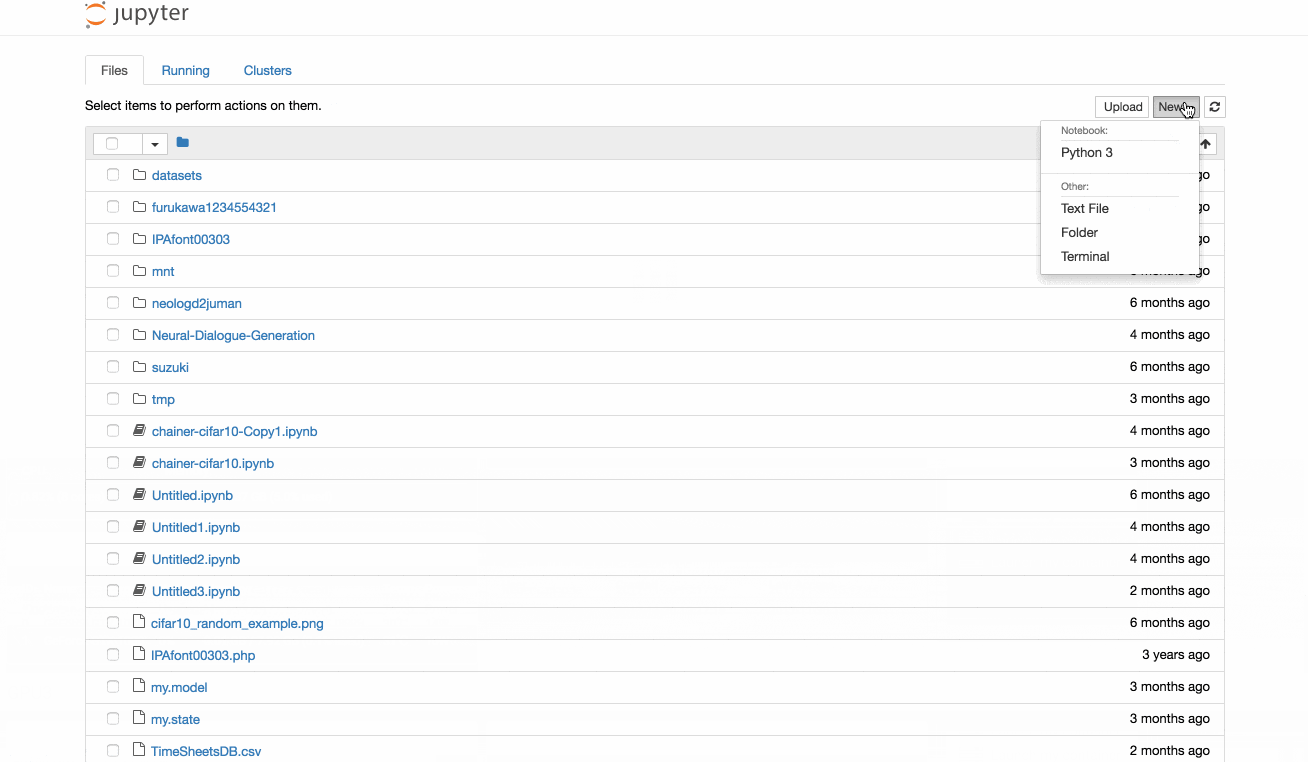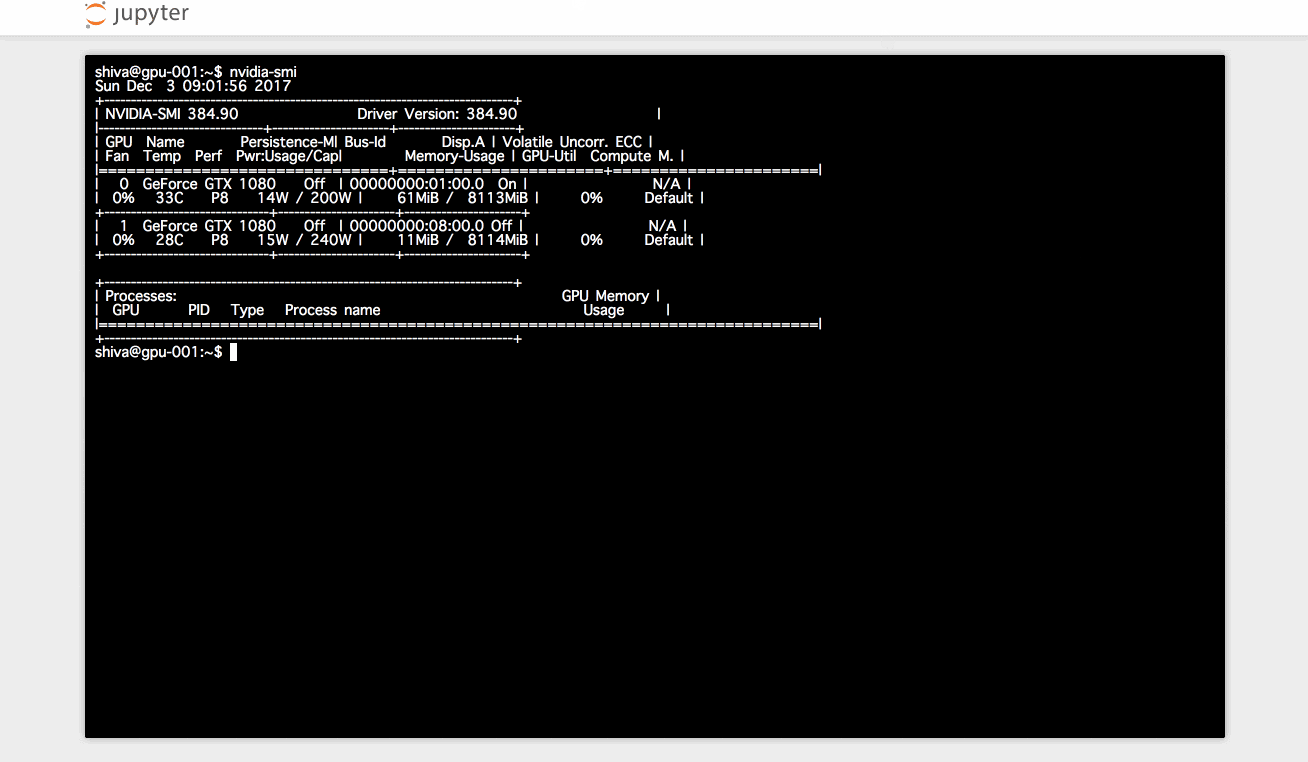
Shiva Dashboard へアクセスすると、各GPUマシンのリソース使用状況、使用中のユーザーが表示されています
ここからリソースが空いているマシンを選んで [Launch my container] をクリックすると、数秒で自分専用のコンテナが作成されてjupyterが立ち上がります
Abstract
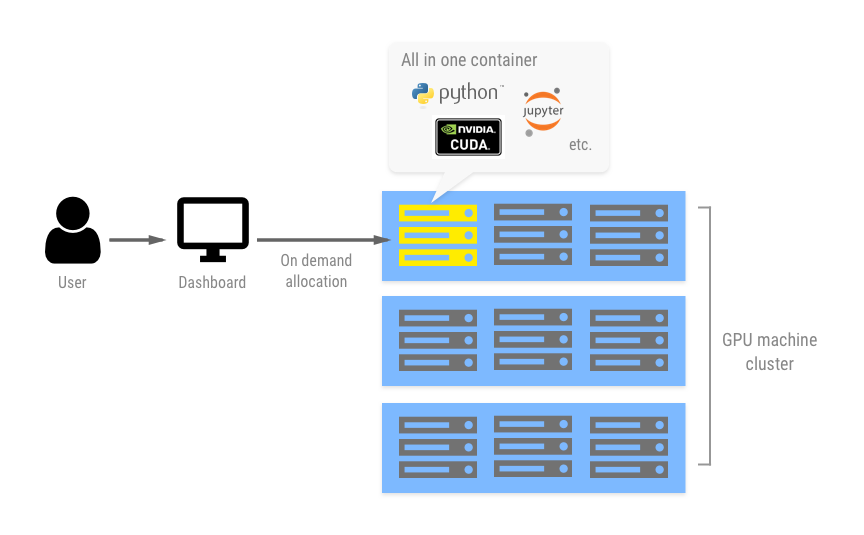
各ユーザー専用のdockerコンテナをGPUマシン上に自動で立ち上げるという仕組みです
これによってマシンリソースのみを複数ユーザーで簡単にシェアでき、他のユーザーとのライブラリの競合などを気にする必要がなくなります
各コンテナには cuda、cudnn、chainer、tensorflow などの深層学習のライブラリや、MeCab、CaboCha、NEologd などの自然言語処理のライブラリをセットアップ済みなので、環境構築に手間をかけずに数秒で開発を始められます
ユーザーには sudo 権限をつけているので自分が使いたいライブラリを自由に追加でインストールできます
また、各ユーザーのホームティレクトリは全マシンで共有されているので、どのマシンを利用しても同じ環境で開発することができます
Architecture Overview
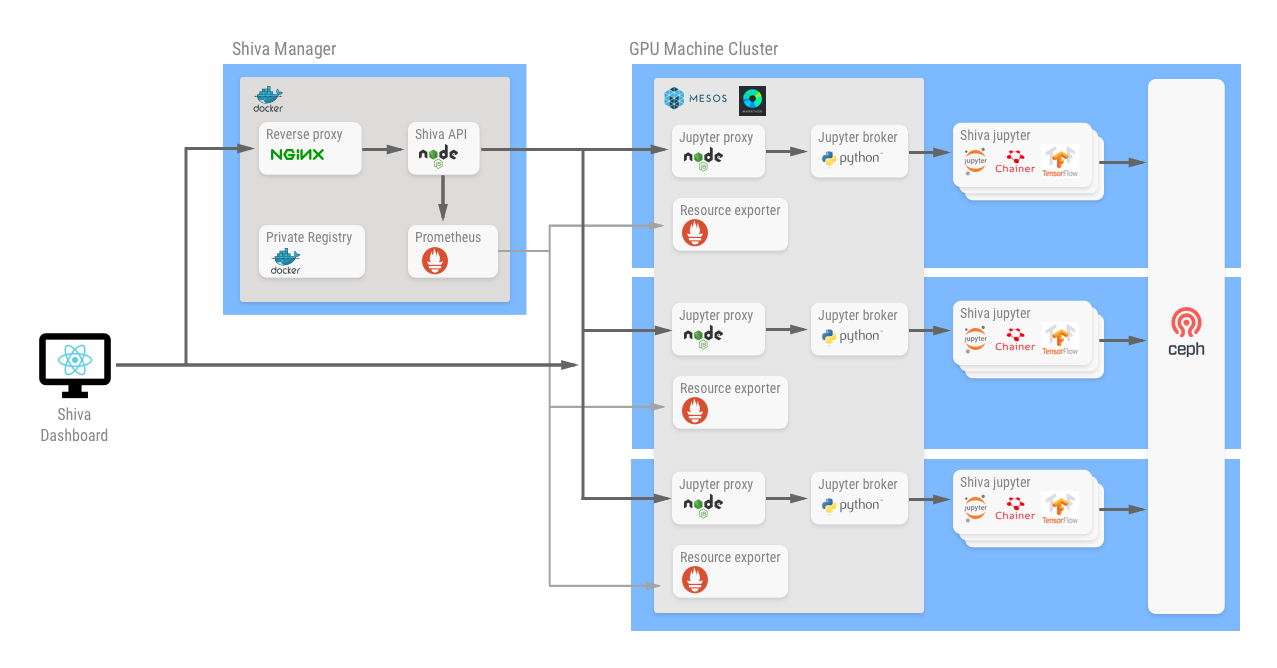
Shiva Dashboard
ユーザーがWebブラウザから Shiva を利用するためのダッシュボードです
ダッシュボードからはコンテナの起動・停止、各マシンのリソース状況、誰がいつから使っているかのコンテナ稼働状況をチェックすることができます
Nextremer では社内ツールでGSuiteを利用していて全社員が会社ドメインのGoogleアカウントを持っているので、ログインにはGoogleアカウントを使います
ダッシュボードはReact.jsで実装しており、私は見た目のデザインのセンスがないので、UI実装の手間を省くためにデザインフレームワークの material-ui を利用しました
Shiva Manager
Shiva API
各マシンのリソース情報取得や、GPUマシンのコンテナ操作を行います
マシンリソース(CPU、メモリ、GPU) は Prometheus のAPIを利用して取得していて、コンテナの情報は Jupyter brokerのAPIから取得します
Private Registry
Shiva で利用しているすべてのコンテナイメージを管理するために、自前でDocker Registry を動かしています
機械学習環境用Dockerイメージはサイズが約15GBとかなり大きいので、push/pullの通信時間を削減するためにローカルネットワーク内でRegistryを動かしています
GPU Machine Cluster
現状はGPUマシン3台を使ってMesosクラスターを構成しています
クラスターの構築とDockerコンテナのオーケストレーションのためにMesos, Marathonを利用しています
Mesos はマシンクラスタを管理するためのソフトウェアで、ある処理を実行しようとした時に、必要な空きリソースがあるマシンを自動で選択して処理を実行してくれます
Marathon は Mesos の機能を利用して動作するフレームワークの1つで、Mesosクラスター上で常時起動するデーモンを管理するためのソフトウェアです
Marathon は Kubernetes に比べると機能が少ないですがその分セットアップが簡単で動作に必要なリソースも少なく済みます
今回の用途ではコンテナオーケストレーションのためのシンプルな機能で十分だったのと、1人で運用することを考えるとトラブル時に調査する箇所がなるべく少ない方がいいので、Shiva ではMesos+Marathonを採用しました
ちなみに、Nextremer で開発・販売している minarai や その他のPJ ではKubernetesを利用して開発されています
機械学習環境コンテナの配備
Jupyter proxy, Jupyter broker, Shiva-jupyter と記載している部分か Shiva の中核を担っている機能で、ユーザーごとの機械学習コンテナとjupyterへのアクセスを管理します
各ユーザーの jupyter がマシン上でリスンしているポートはランダムに割り振られており、Jupyter proxy は起動ユーザーと jupyter のポート番号とのマッピングテーブルを保持しています
これにより、アクセスしてきたユーザーに応じてリクエストをそのユーザーのコンテナにプロキシする仕組みになっています
また、起動しているコンテナ情報の取得やコンテナ作成・削除は API を経由して操作できます
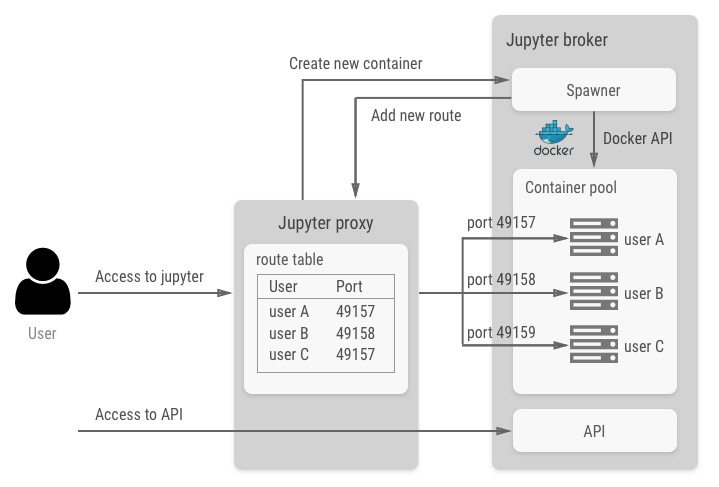
これらの機能は tmpnb というProject Jupyterが公開しているOSSをベースに Jupyter proxy & Jupyter broker を実装しました
tmpnb は複数ユーザーが独立した環境の jupyter を利用する機能を提供していて、Shiva のコンテナ管理はこの機能をほとんど流用しています
機械学習環境のdockerイメージは、nvidiaが提供しているcudaのイメージをベースとして作成しています
nvidia-docker
ホストのGPU にコンテナからアクセスできるようにするために内部ではnvidia-dockerを利用しています
nvidia-dockerコマンド自体は、本来のdockerコマンドにnvidia-docker-pluginから取得したGPUデバイスのオプションを付け足しているだけです
https://github.com/NVIDIA/nvidia-docker/wiki/Internals
https://github.com/NVIDIA/nvidia-docker/wiki/nvidia-docker-plugin
※久しぶりに見たらVersion 1.0 (Deprecated)となってますね(!)
なので、Shiva のようにdocker APIを利用する場合は、単純にnvidia-docker-pluginから取得できるオプションをAPIへのリクエストに付け足せば同じように利用できます
※とはいえ、現状はコンテナ内からsshfsを使うのがうまく解決できず、けっきょくprivilegedオプションを付けて起動しているのでnvidia-dockerの意味がなくなってしまっていますが・・・
Prometheus exporter
Prometheus の監視対象となる情報を Prometheus に公開するためのソフトウェアです
exporter 自身はそれぞれが保持している情報を JSON形式のAPI として公開する機能だけを持っていて、Prometheus が監視対象のexporterをポーリングして Prometheus 側のデータベースに格納するという仕組みになっています
Shiva では以下のexporterを利用しています
- 物理マシン(CPU、メモリ、NW、ディスク、温度)
- node_exporter をそのまま利用
- GPU(利用率、メモリ、温度)
- nvidia_exporter をカスタム
- コンテナ状況(利用ユーザー、最終アクセス時刻)
- Jupyter brokerの情報を取得するexporterを独自に実装
CephFS
分散ストレージを構築するcephをファイルシステムとして利用できる CephFS を利用して、全マシンからアクセスできる共有の領域を作っています
各ユーザーのホームディレクトリはCephFSに保存されており、Shiva-jupyterにはCephFS内にあるユーザーのホームディレクトリをマウントしています
CephFS上のファイルへのI/Oはネットワーク越しに行われ、各ファイルは冗長化と読み込み高速化のために各Cpehノードにストライピングして保持されます
そのため必ずネットワークを介するためLANの速度がボトルネックになってしまいます
しかし機械学習のタスクの場合は、ファイルをメモリ・GPUメモリ上に一括でロードし計算を繰り返す処理が主なのでディスクI/Oがボトルネックになる状況は少ないです
そのため Shiva の利用用途ではここは問題ないと判断し、実際の運用でもディスクI/Oの速度は今のところ問題にはなっていません
いきなり電源が落ちてもデータが消えることなく自動で復旧される点がかなり素晴らしいです
※Cephに関する情報を調べていると、商用環境で大量データ・大量アクセスに対応しようとするとなかなかツライようです
Infrastructure Overview
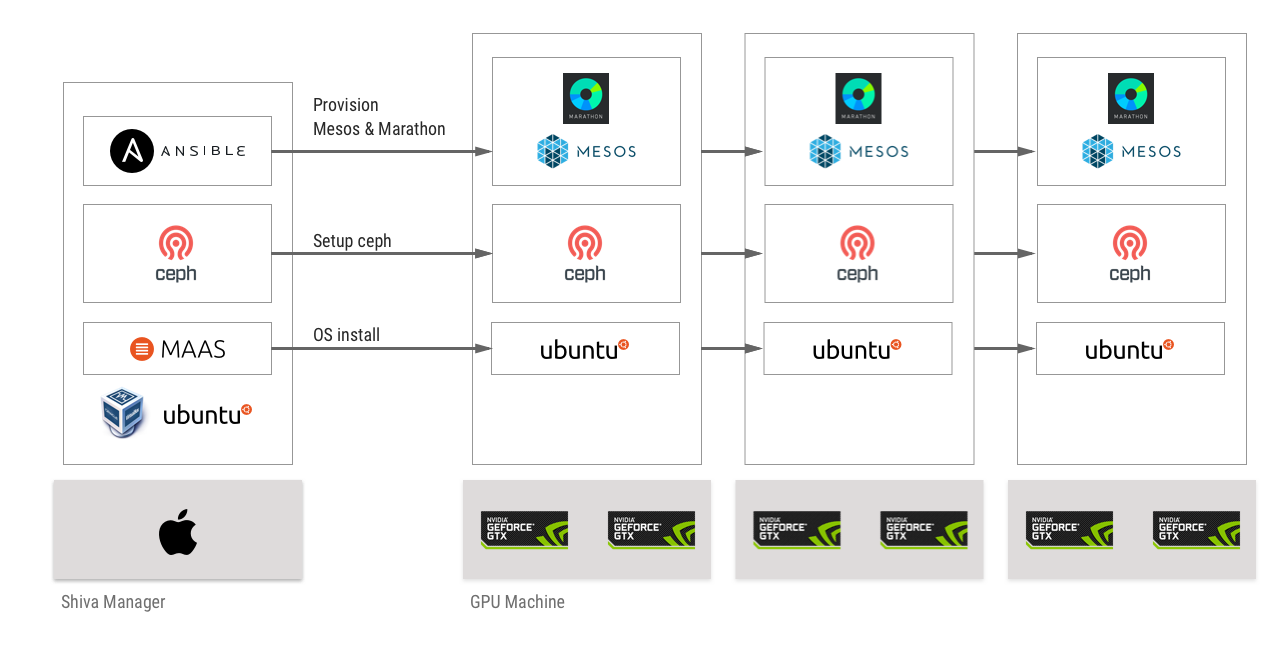
MAAS
ベアメタル環境を構築するための Ubuntu 公式のツールで、マシンへのOSインストールを自動で行うことができます
これはRettyさんの記事で知り利用させていただきました
MAAS自体の情報が少ないので若干戸惑いましたが、MAASの公式ドキュメントの通りにやれば大きくハマることもなく使えました
MAAS の2.x系では電源投入にWake-on-LANが使えず電源ONは手動でやらないといけないところが少しだけ不便です
ただ、物理マシンの電源ON・OFFする機会は少なくオフィスにいる間しかやらないので特に問題にはなっていません
Ceph
cephのセットアップはいろいろ調べながら結構苦戦して何度もやり直しました
cephの構築は以下の記事を参考にさせていただきました
https://jedipunkz.github.io/blog/2014/01/29/ceph-process-best-practice/
https://jedipunkz.github.io/blog/2014/02/27/journal-ssd-ceph-deploy/
https://www.server-world.info/query?os=Ubuntu_16.04&p=ceph
最終的にはceph-deployのコマンドを1つづつ実行していくシンプルな手順になりました
ここもansibleで自動化したいですが現状手はつけていないです
Ansible
ミドルウェアの構成管理ソフトウェアで、Mesos & Marathon 環境のセットアップを自動で行うために利用しています
Rettyさんの記事では juju を利用していたので最初はそちらも試したんですが覚えるまでに多少時間がかかりそうだったので、Ansibleは使い慣れている & 今回やりたいことに対しては十分だったので今のところはAnsibleを利用しています
ただ、クラウド上で動的にスケールさせるような仕組みを考える場合には、juju を利用した方がクラスタのセットアップが簡単そうな印象を受けました
物理マシンスペック
GPUマシンは以下のスペックのものを3台利用しています
| CPU | Intel Core i7-6700K |
| メモリ | 32GB |
| Disk | SSD 500GB |
| GPU | GTX-1080 ×2 |

最初はオフィスの端にひっそりと置いていたんですが、**こういうのは見た目が大事だ!**と思ってとりあえずLEDファンとLEDテープで光らせて、メンバーから見えやすいように神棚てきな場所に置いています
まだまだデコりが足りないので今後も隙を見つけてグレードアップしていきたいです
また、Shiva Managerに利用しているサーバーは、インターン用に持っていたMacbook Proを1台そのまま使っています
運用していて起こった問題
ディスク上限
cephの仕組みでは1つ1つのファイルがレプリケーションされて保持されるので、単純に1ファイルあたりで2倍の容量が使われます
Shiva の環境では合計で1.5TBのディスク容量が利用できますがcephでの実効容量はその半分です
※ここはあまり詳細まで調べられていないです
過去に学習データの数百GBのデータを Shiva にアップロードしたメンバーがいて、cephの容量上限に達してシステムが停止してしまうことがありました
データのアップロード自体にも時間がかかってしまうので、それ以降は大容量のデータは Shiva には置かずに、sshfsでコンテナ内から自分のPCのディスクをマウントして利用してもらうようにしました
コンテナのリソース分離
コンテナに特にリソース制限を設定していなかったので、一部のコンテナが暴走してメモリとCPUを食いつぶしてしまった時にマシン全体の動作が止まってしまう問題がありました
dockerはコンテナ毎にリソース制限を設定することができるので、頻繁に問題が起こるようであればこの設定も入れた方がいいです
Shiva の場合は人数が少ない社内メンバーがユーザーですし各メンバーの技術リテラシーもある程度把握しているのでこのような仕組みでも問題はありませんが、一般ユーザー向けの本格的なサービスの用途となるともっと厳格なリソース分離が必要になってくるのでかなり大変になると想像できます
Kodingがコンテナをやめてdockerから仮想マシンに移行したのはなぜ?
運用開始後の Shiva の利用実態
利用の実態としては、GPU環境での簡単な検証のために利用されたり、インターンやフリーランスで協力してもらっているメンバーに開発用途で利用してもらっています
また、GTX-1080が合計で6枚あるので、ハイパーパラメーターの組み合わせを複数パターン試すのに Shiva を使ってくれているメンバーもいます
機械学習コンテナを全部入りの環境にはしましたが、深層学習のライブラリはpyenv等でメンバーそれぞれで自分の環境をセットアップして使っているようでした
そのため、特定バージョンの全部入り環境よりも、自分でセットアップした環境をそのまま保存できる機能があった方が便利そうです
また、ブラウザからjupyterではなくSSHでアクセスしたいという要望も上がっています
今後そういった機能を追加して拡張していこうと計画しています
※だいぶ前からそう思っているんですが、なかなか時間が取れないものですよね・・・
まとめ
当初はRettyさん機械学習基盤の完コピを目指していましたが、自分たちが抱える課題や自分のスキルの事情に合わせてところどころアレンジしながら現状の Shiva にたどり着きました
今年は複数のPJを掛け持っていてめちゃくちゃ忙しかった時期があったんですが、それらが一段落した後に1ヶ月くらいほぼフリー(10%程度の稼働)にしてくれて、その期間を使って1人で開発しました
普段はクラウドのマネージドのサービスに頼りきっているので、インフラの部分を直接触る場面はほとんどないため、今回インフラに関しては特に幅広く技術を調査する必要があり苦戦しました
それでも、調査して得られた情報を使って実際に Shiva を構築できたので、自分にとってものすごく勉強になりました
そして実はこれまで自作PCなんて一度も全くやったことがなく、パーツの種類も電源の容量とかもよくわからないし、完全な素人だった状態から調べたり周りのメンバーに教えてもらいながら色々と試行錯誤をしてなんとか物理マシンの部分も作りました
秋葉原に行ってPCのパーツを探すのとかもめちゃくちゃテンション上がりました
本当に初めての部分だったのでここは一番おもしろかったです
Nextremerのエンジニアは、何かしら困った課題に直面した時にたとえその分野の専門知識を持たなかったとしても自分たちで調べてエンジニアリングで解決するというマインドを持っています
私たちが研究している対話システム・深層学習の技術に関しても最初は素人だったメンバーがほとんどで、そこから自分で調査・実践してスキルを上げてきた人たちばかりです
今では社外に誇れる卓越したスキルを持つメンバーがたくさんいます
例え未知の領域であっても、自分たちが先頭に立って何もないところに道を切り開いていこうとしている周りのメンバーの姿勢にいつも刺激を受けながら仕事をしています
このような環境で自由にアクティブに働きたい方、ぜひ Nextremer に来て一緒に仕事をしましょう!
https://www.wantedly.com/companies/nextremer/projects
最後に
最後に、機械学習基盤の情報を公開してくださった樽石さん、本当にありがとうございました!
Nextremer でもオープンにできる技術的な情報、ソースコードは今後も積極的に公開していきます
この記事の情報もまた、どこかの誰かの役に立ってもらえることを願って・・・!