はじめに
機械学習など大量の画像データが必要なときに頼るものといえばスクレイピングですよね。Googleを始め、YahooやBingなど様々なサイトから画像を拾ってくる記事は既に沢山ありますが、今回はGoogle画像検索について書こうと思います。
Google画像検索から画像を集めるプログラムは多々紹介されていますが、仕様変更が多いのか、はたまたスクレイピング対策か今現在もまともに画像を集められるものは少ないです。
実際にrequestsやBeautiful Soupを使ってGoogle画像検索の検索結果をスクレイプして見るとわかるのですが、所得した情報には20件分くらいしか画像データが含まれていないんですよね。
直接スクレイプできないならクローリングで実際にブラウザを経由すれば?
と、言うことで、本題のSeleniumの登場です。
Seleniumを使って検索結果のページを表示すると、HTML等の内容も当然表示内容に合わせて(因果が逆ですが)多くの写真のデータを含んだものに書き換わります。
この状態に持っていってから改めてスクレイプすることで大量の画像を得ることが出来るわけです。
しかしGoogle、なかなか手強く、この状態で得られるのはサムネ画像だけです。まあ元サイズの画像データが数百枚分埋め込まれてたら大変なデータ量になりますのでGoogleとか関係なく当然ですけどね。
ここから個々の画像をクリックして1枚ずつ元サイズで保存することも可能ですが、そもそも画像サイズが大きい必要がない場合にはこのままサムネイルさえかき集めてしまえば勝ちです。
Chromedriverのダウンロード等、Seleniumを使う準備は整っているとして、
では行きましょう。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import os
import time
import requests
import shutil
import base64
options = Options()
options.add_argument("--disable-gpu")
options.add_argument("--disable-extensions")
options.add_argument('--proxy-server="direct://"')
options.add_argument("--proxy-bypass-list=*")
options.add_argument("--start-maximized")
# options.add_argument("--headless")
DRIVER_PATH = "chromedriver.exe" #chromedriverの場所
driver = webdriver.Chrome(executable_path=DRIVER_PATH, chrome_options=options)
query = input('Search word? :')
url = ("https://www.google.com/search?hl=jp&q=" + "+".join(query.split()) + "&btnG=Google+Search&tbs=0&safe=off&tbm=isch")
driver.get(url)
# 適当に下までスクロールしてる--
for t in range(5):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight)")
time.sleep(1.5)
try:driver.find_element_by_class_name("mye4qd").click() #「検索結果をもっと表示」ってボタンを押してる
except:pass
for t in range(5):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight)")
time.sleep(1.5)
srcs = driver.find_elements(By.XPATH, '//img[@class="rg_i Q4LuWd"]')
try:os.mkdir(query) #検索語と同じ名前のフォルダを作る、保存先
except:pass
# --
i = 0 #ファイル名に通し番号をつける用カウンタ
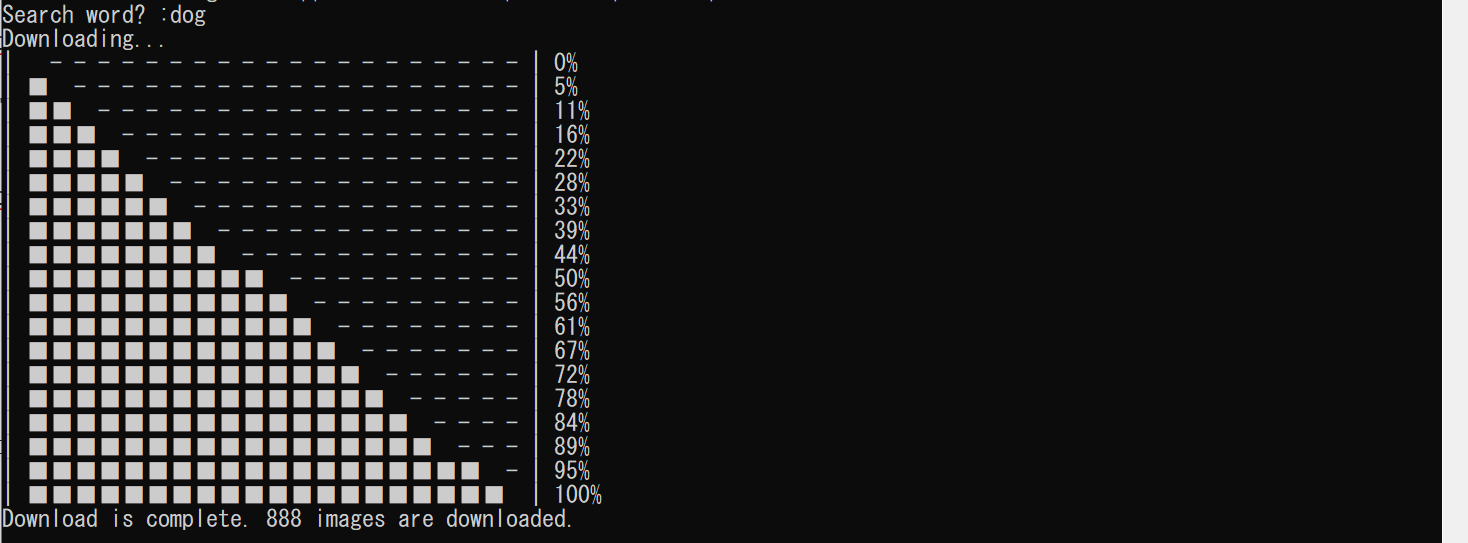
print("Downloading...")
for j, src in enumerate(srcs):
if j % 50 == 0 or j == len(srcs)-1:
print("|"+ ("■" * (20 * j // (len(srcs)-1)))+ (" -" * (20 - 20 * j // (len(srcs)-1)))+ "|",f"{100*j//(len(srcs)-1)}%") #ダウンロードの進捗示すやつ
file_name = f"{query}/{'_'.join(query.split())}_{str(i).zfill(3)}.jpg" #ファイル名とか場所とか
src = src.get_attribute("src")
if src != None:
# 画像に変換--
if "base64," in src:
with open(file_name, "wb") as f:
f.write(base64.b64decode(src.split(",")[1]))
else:
res = requests.get(src, stream=True)
with open(file_name, "wb") as f:
shutil.copyfileobj(res.raw, f)
# --
i += 1
driver.quit() #ウィンドウを閉じる
print(f"Download is complete. {i} images are downloaded.")
結果
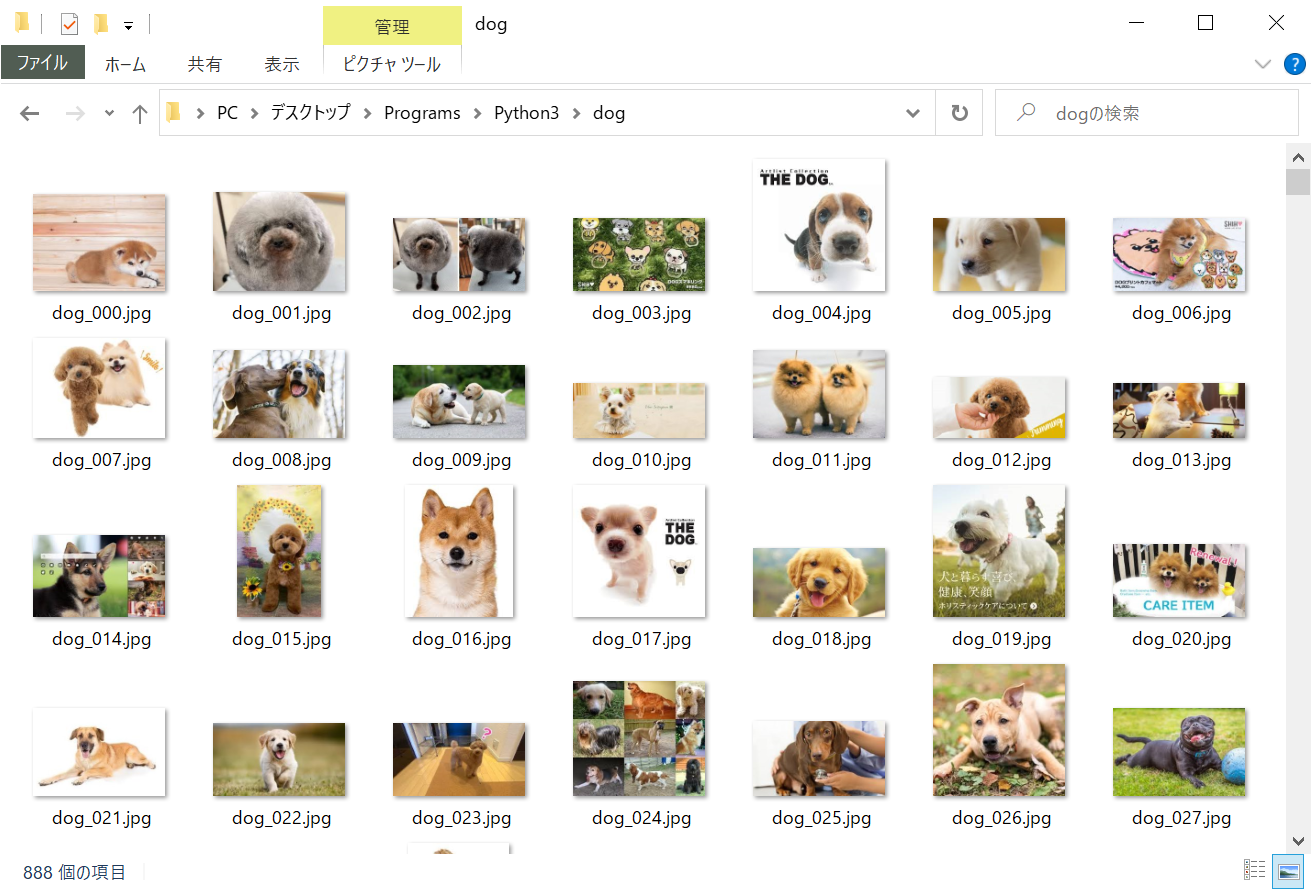
実行後、検索語を入力して少し待つと400~1,000枚程度の画像が検索語句と同じ名前のフォルダに保存されているはずです。
まとめ
2分くらいで数百~千枚の画像が集まるので機械学習が捗りそう(自分でデータセット作ったことないけど)。
スクレイピング、クローリングは最近勉強を始めたばかりなので、改善点、マズイ点等ありましたらご教示いただけると助かります。
参考にしたサイトなど