PostgreSQLやMySQL, Oracle, SQLServerといったRDBに慣れ親しんだ人が初めてBigQueryに触る際に抑えておきたいポイントです。
自分がBigQueryを使い始めて2~3週間の頃にハマったポイント中心にまとめました。
比較表
以下、それぞれざっくりした特徴を並べた比較表です。
| PostgreSQL, MySQLなど | BigQuery | |
|---|---|---|
| タイプ | リレーショナルデータベース(RDB) | データウェアハウス(DWH) |
| 用途 | データの整理、保管 | データ分析 |
| 指向 | 行指向 | 列指向 |
| サーバ有無 | あり | サーバレス |
| 構造 | database (cluster)- schema(database) - table | project - dataset -table |
| データ型の粒度 | 細かい | 荒い |
| キー制約 | あり | なし |
| 最も料金ウェイトの高いポイント | (Cloud系の場合)インスタンス(サイズと稼働時間) | 分析(クエリ実行) |
| クエリの書き方 | 標準SQL | 標準SQL(推奨) レガシーSQL |
比較表の内容の一部に関し、もう少し詳しくみていきます。
タイプ, 用途
PostgreSQLやMySQLなどのRDBは、データの整理や保管に使われ、整合性、一貫性を担保する必要がある(トランザクション処理が必要な)場合に使います。
使用シーンとしては、会員情報や商品データの管理など、業務システムでの利用があげられます。
一方、BigQueryは、DWH(データウェアハウス)の一種でデータ分析に特化したGCPのサービスです。
他の代表的なDWHとしては
- Snowflake
- Amazon RedShift
- Azure Synapse Analytics
- Treasure Data
などがあげられます。
(1) 指向
RDBが行指向なのに対し、DWHは列指向です。
DWHはRDBと違って、フィールド全体ではなく、指定した列データのみ読み取ることができるので、RDBと比べて高速に処理を行うことができます。
自分の経験ベースだと、RDB(Amazon Aurora: PostgreSQL互換)で4時間半くらいかかっていた処理が30分で終わったりなど、目に見えて処理が速くなりました。
以下、Treasure Dataのドキュメントではありますが、ビジュアル的にも、行指向と列指向の違いがわかりやすかったので、リンクを貼っておきます。
【参考】 列指向データベースと行指向データベース | TREASURE DATA
(2) 構造
RDBがおおよそ、database- schema - table という構造になっているのに対し、BigQueryは project - dataset - table という構造をとっています。
- schema ≒ dataset
- table = table
なので、まずはこの2点だけ押さえておけばよいでしょう。
(3) データ型の粒度
RDBに比べ、BigQueryのデータ型の粒度のほうが荒めです。
例として、PostgreSQLの整数型, 文字列型とBigQueryのそれを比較してみると以下の通り。
整数型
| PostgreSQL | BigQuery |
|---|---|
| smallint integer bigint smallserial serial bigserial |
INT64(※) |
※BigQueryの整数型の表現として他に、INT、SMALLINT、INTEGER、BIGINT、TINYINT、BYTEINTがありますが、全てINT64のエイリアスになります。
文字列型
| PostgreSQL | BigQuery |
|---|---|
| character varying(n), varchar(n) character(n), char(n) text |
STRING STRING(L) |
PostgreSQLだと、大きく分けて3つの文字列型があるのに関し、BigQueryはSTRING型, STRING(L)型(後者は文字列長を指定できる)の2つのみ。
(4) キー制約
RDBにはPrimary Key, Unique Key, Foreign Keyといったキー制約があるのに対し、BigQueryにはありません。
簡単な内容にはなりますが、標準SQLでBigQuery上にテーブル作成するDDLを書くと以下の通り。
CREATE TABLE mydataset.newtable (
id INT64
, product_name STRING
, sex STRING
, age INT64
, insert_time DATETIME
);
RDBのテーブル作成のためのDDL文では、少なくともprimary keyを指定する必要がありますが、BigQueryでは上述の理由もあって指定しません。
料金
RDBの課金体系は、使い方や契約にもよりますが、ここではCloudサービスのSQLであるAmazon Auroraと比較してみます。
| RDB(Amazon Aurora) | BigQuery |
|---|---|
|
インスタンス料金 ストレージ・I/O料金 バックアップストレージ データ転送 他 |
分析(クエリ実行)料金 ストレージ料金 他 |
Amazon Auroraがインスタンス料金(サイズと稼働時間で決まる)のウェイトが高いのに対し、BigQueryは分析(= クエリ実行)料金のウェイトが高いです。
なので、何も考えずにクエリを多数実行してしまうと、データ量にもよりますが、課金額が上がる可能性大!(この点の対策については、後述の「クエリ実行時 - (1) 特に重いクエリを流す際は実施前に必ずdry runを」に記載してますので、そちらをご覧ください)
BigQueryのクエリ料金は、米国(マルチリージョン)の場合、1TBあたり5USD(ただし、毎月1TBまでは無料)。
BigQueryの料金についての詳細は、
BigQuery の料金 | BigQuery: クラウド データ ウェアハウス | BigQuery
をご覧ください。
クエリ
RDBはデータベースによって多少の方言があるものの、基本的には標準SQL。
BigQueryについては、ひと昔前はレガシーSQL(BigQuery SQL)という独自のクエリ構文のみでしたが、2016年のBigQuery2.0のリリースに伴って、標準SQLが使えるようになり、現在は後者が推奨されています。
ただし、標準SQLに関しても、後述の通り多少クセがあるのでその点は要注意!!
テーブル作成、クエリ実行時の注意点
操作方法
注意点に入る前に、
①コンソール
②コマンドライン(bqコマンド)
③クライアントライブラリ
の大きく分けて3つがあります。
例えば「SQLワークスペース」から操作する場合は①のコンソール、プログラムから操作する場合は、③のクライアントライブラリになります。
テーブル
(1) ログ収集など大量データを投入する場合は必ずパーティショニングを使用しましょう。
(2) 日付パーティションの場合は特別な事情がない限りDAY単位で設定
→ クエリ実行時にパーティション単位で検索に行くのでクエリ効率がよくなり、コスト軽減にもなります
実際のケースで見てみましょう。
以下のキャプチャは、dateというカラムに日単位(DAY単位)のパーティションを切った同じテーブルに対し、クエリを実行した結果です。
dateでの絞込以外は全く同じ条件にしているのですが、絞込ありのほうがなしの場合よりも、実行時間(=期間(①))、コスト(=課金されるバイト数(②))ともに少なくなっていることがわかります。
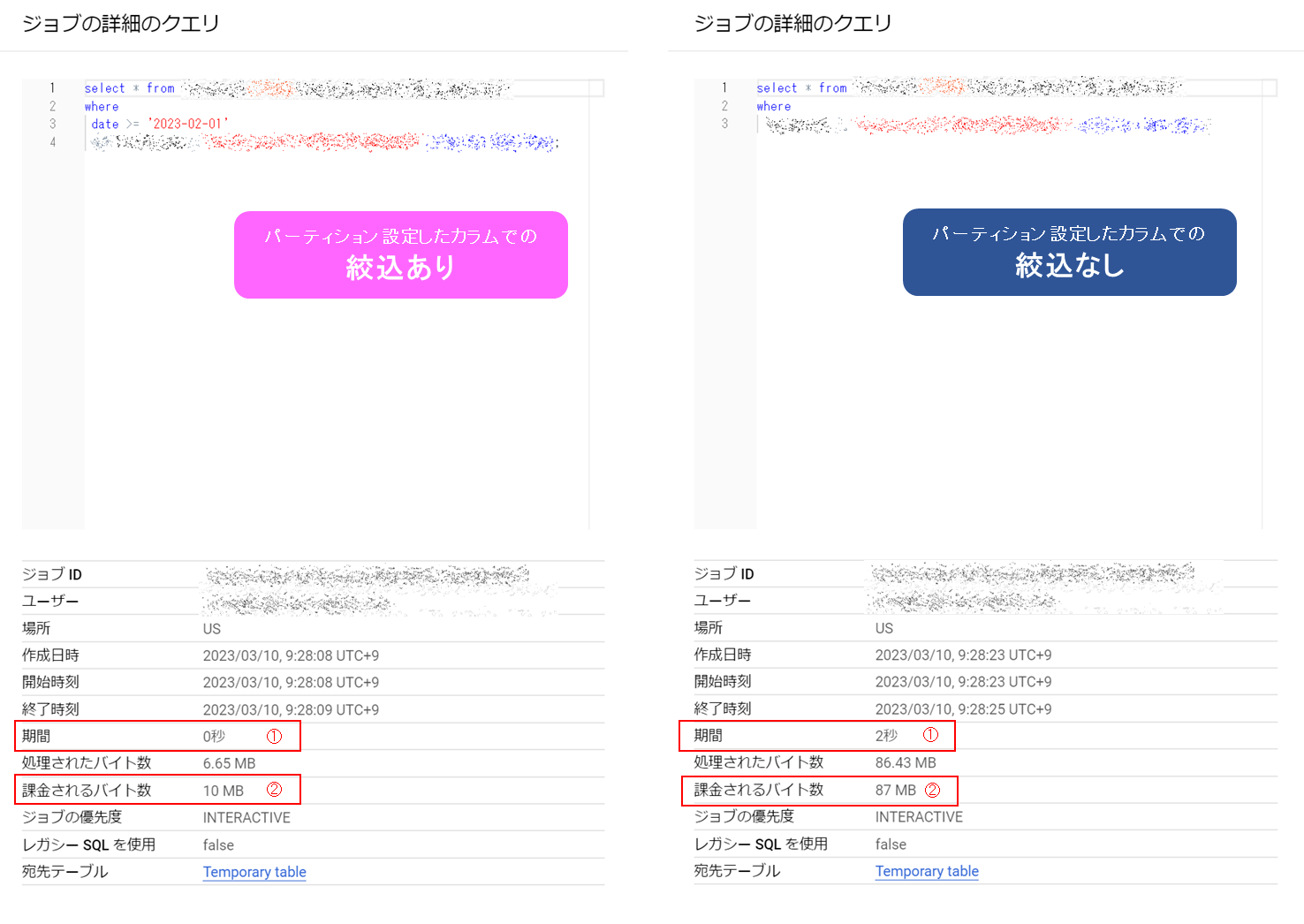
パーティション設定したカラムでの絞込有無の比較
| あり | なし | 備考 | |
|---|---|---|---|
| 期間 | 0秒 | 2秒 | 実行時間に相当 |
| 課金されるバイト数 | 10MB | 87MB | 大きいほどコストがかかる |
このパーティション(分割テーブル)については、詳しくは
分割テーブルの概要 | BigQuery | Google Cloud
をご確認ください。
また、上記キャプチャの「ジョブ詳細のクエリ」の出し方は後述の
「覚えておくと便利なワザ」の「(1) 実行履歴の確認」
に記載していますので、そちらをご覧いただければと。
クエリ実行時
(1) 特に重いクエリを流す際は実施前に必ずdry runを
クエリ実行が最もコストウェイトとして高いので、特に重いクエリを流す際は実施前に必ずdry runを実行するようにしましょう(SQLワークスペースにてクエリの入力 →画面右上でもチェック可能)
①hogeプロジェクトにて、Cloud Shellを起動し、bqコマンドにて確認する場合
bq query \
--use_legacy_sql=false \
--dry_run \
'SELECT
id,
name,
age
FROM
`fuga.piyo`
LIMIT
1000'
②SQLワークスペースから確認する場合

→ 「SQLワークスペース」にて、正しいクエリを入力するとコンソール右上に消化されるデータ量が表示されます。
255.09GBと表示されていますので、このクエリをそのまま実行すると、
(255.09/1024)(TB)×5(USD)×130(円) ≒162(円)
かかってしまいます(1USD = 130円として計算、米国マルチリージョンの場合)。
【参考】 クエリのドライランの発行 | BigQuery | Google Cloud
※クエリコストがかからないパターン
以下の場合はクエリコストがかかりません。
①count関数(全件), truncate table
②クエリキャッシュを利用しての再度のクエリ実行
③クエリに失敗した場合
(2) 後からカラム名の変更は不可能 2022年8月19日に後からカラム名の変更も可能に!(2023年2月24日現在ではプレビュー版)
自分がBigQueryを使い始めた2022年6月時点では、カラム名の変更は不可だったので、Create table as Selectなどでカラム名を変更した別テーブルを作って、テーブルをリネームする必要があったのですが、リリースノート によれば、2023年2月24日現在もプレビュー版ではありますが、カラム名を直接変更できるようになったようです。
-- fugaデータセット:piyoテーブルのidをpiyo_idにリネーム
alter table `fuga.piyo` rename column id to piyo_id;
(3) from句には少なくとも「データセット名.テーブル」を書く
RDBの場合、スキーマ(データベース)名を指定して接続すれば、クエリ実行時のfrom句にはテーブル名のみ記載すればよかったのですが、BigQueryの場合は基本from句に最低「データセット名.テーブル」を記載する必要があります
以下、hogeプロジェクトを使っていて、SQLコンソールから、fugaデータセットのpiyoテーブルにアクセスする場合
-- 動かないパターン
select count(1) from `piyo`;
-- データセットを指定すると動く
select count(1) from `fuga.piyo`;
-- プロジェクトも指定するとなおよい&権限さえ付与されていれば別プロジェクトのコンソールからも実行できる
select count(1) from `hoge.fuga.piyo`;
※バッククォートはなくても動きますが、SQLワークスペースでの実行の場合つけたほうが色付けされてわかりやすいです。
(4) 日付は'yyyy/MM/dd'ではなく'yyyy-MM-dd'で指定
こちらも覚えてしまったら大したことはない内容ですが、最初の頃は割と躓きました。
-- 動かないパターン
select count(1) from `fuga.piyo` where date = '2023/02/01';
-- 動くパターン
select count(1) from `fuga.piyo` where date = '2023-02-01';
(5) 時刻はTIMESTAMP型よりDATETIME型がベター
時刻に関し、TIMESTAMP型かDATETIME型か、でいえば、できれば後者のDATETIME型を使うのがよいでしょう。
タイムスタンプ関数でのタイムゾーンの仕組み | BigQuery | Google Cloudによれば、
タイムゾーンが指定されていない場合は、デフォルトのタイムゾーンの UTC が使用されます。
とあり、そのままだとUTCすなわち、日本時間-9時間でとれてしまいます。
この概念に不慣れなメンバーがいる場合、どうしても事故の起きる可能性が高くなってしまうので、特別な事情がない限りはDATETIME型を使うようにしたほうが安全です。
覚えておくと便利なワザ
以下、SQLワークスペースから実行できる、覚えておくと何かと役に立つワザたちです。
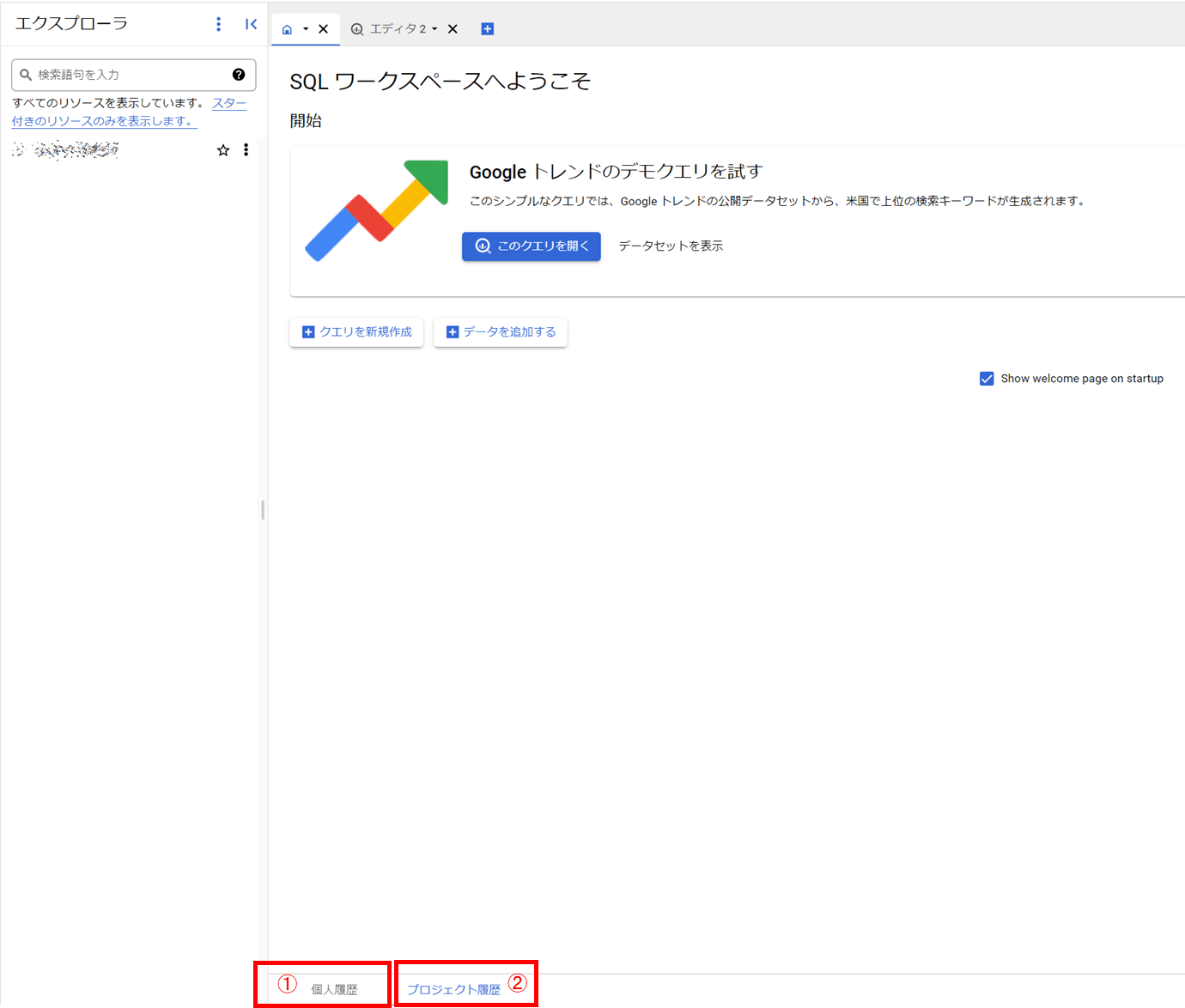
(1) 実行履歴の確認
SQLコンソールの下方、
- 「個人履歴」(①)から自身のクエリ等の実行履歴
- 「プロジェクト履歴」(②)から操作中のプロジェクトにおける実行履歴
が確認可能
そこからさらに、履歴一覧の「操作」(③)> 「ジョブの詳細を表示」(④)を開くと、
- 実行されたクエリ(⑤)
- クエリ実行にかかった時間(⑥)
- 課金対象のデータ量(⑦)
など詳細な内容を確認できます
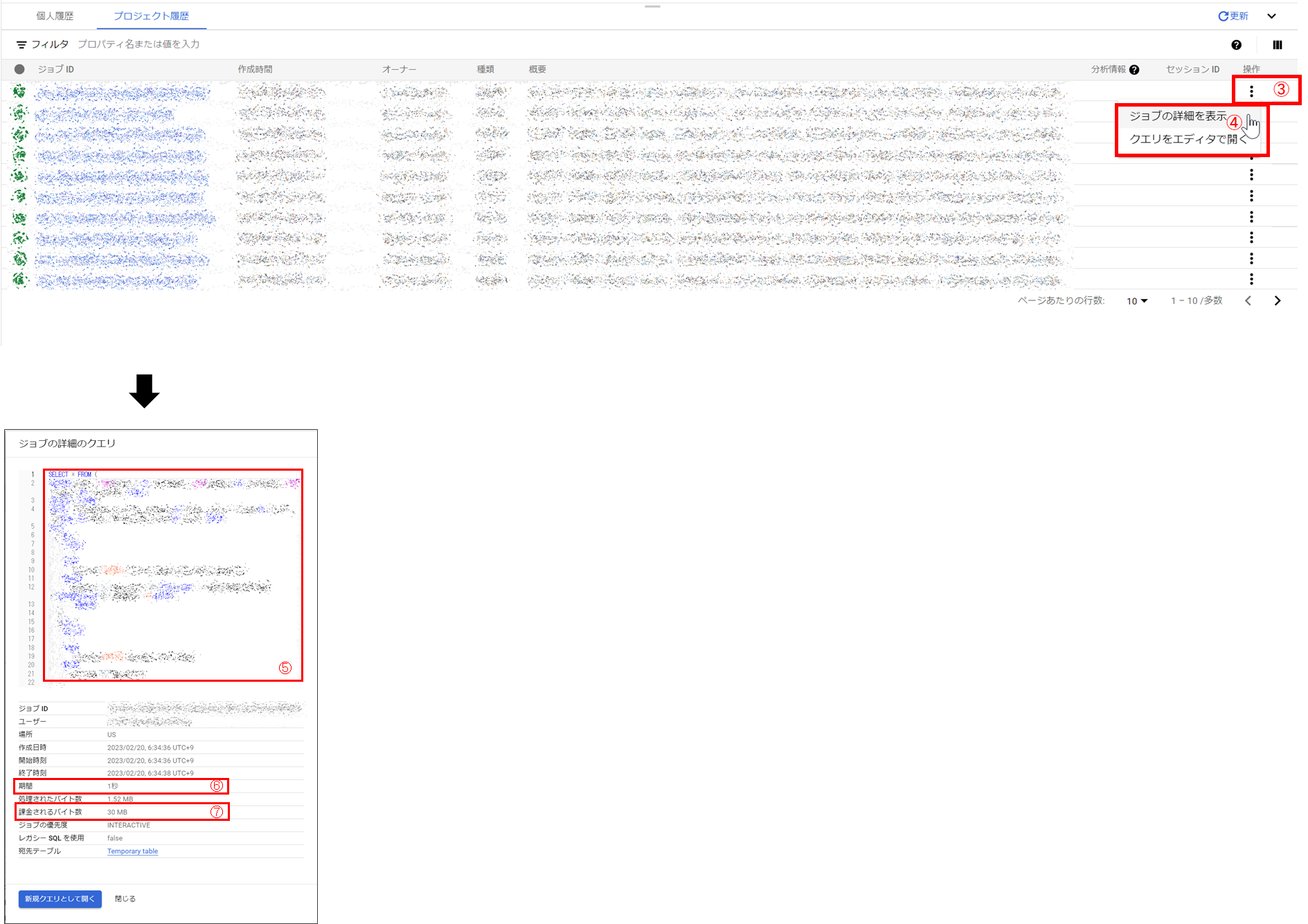
→ クエリの成否や、後からクエリコストを算出したい場合などに!
(2) エクスプローラのテーブル情報
エクスプローラにて、任意のテーブルをクリックしての操作
①クエリ
クエリサンプルを発行できます
テーブル情報の「クエリ」(①) > 「新しいタブ」(②)とクリックすると、
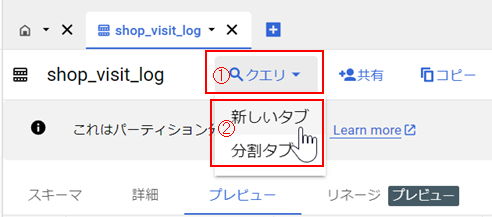
以下のようにクエリが発行されます。

そのままだとエラーが出て実行できませんが、以下のようにカラム指定すると実行可能なクエリになります。

②スキーマ
テーブル定義を確認できます。
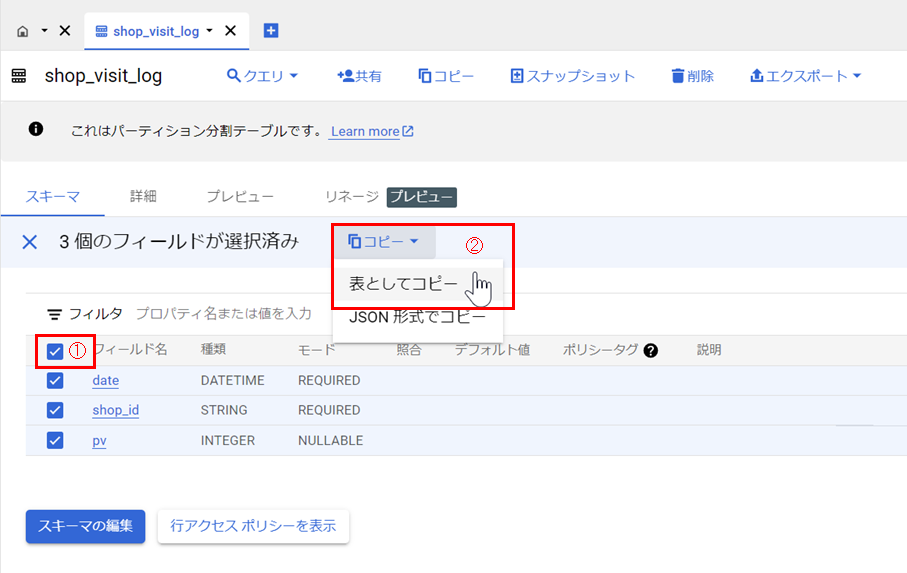
全フィールドを選択 > 「表としてコピー」すればテーブル定義書の作成時にも便利!
③詳細
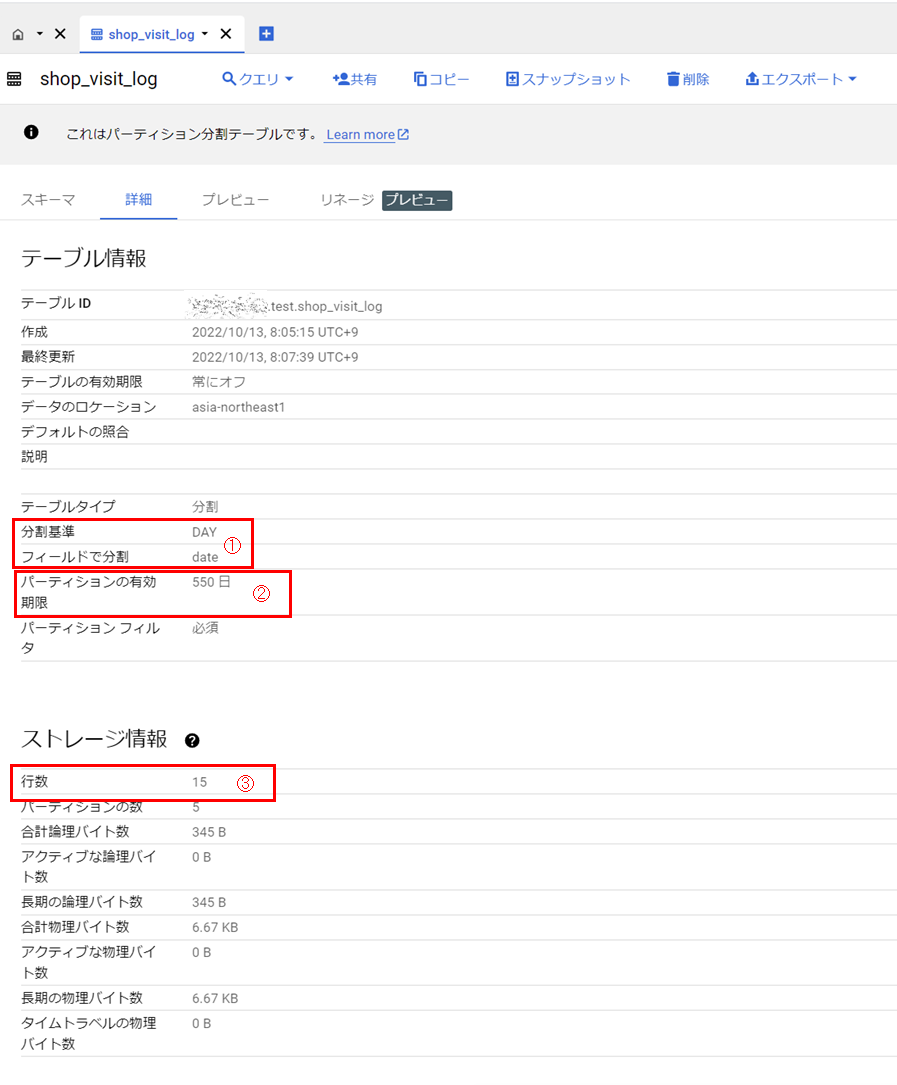
テーブルの詳細情報です。
パーティション単位(①)や有効期限(②)、データ件数(③)を確認できます。
④プレビュー
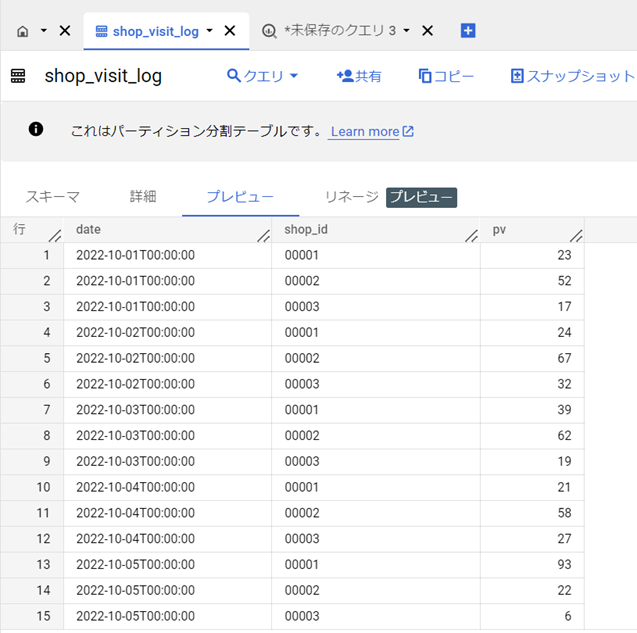
テーブルの中身の一部を確認できます。
どんなデータが入っているかサクッと確認したい時に。
終わりに
RDB慣れしていると少々とっつきにくいBigQueryですが・・
標準SQLを使えることもあって、ポイントさえ押さえてしまえば、その後は非常にスムーズ。
この記事の内容が少しでもお役に立てば幸いです。