はじめに
CEML (Clinical Engineer Machine Learning)初投稿です。
今回は初心者向けにpythonでのデータ解析について解説したいと思います。
ソースコード
https://gitlab.com/ceml/qiita/-/blob/master/src/python/notebook/first_time_data_analysis.ipynb
本記事の内容
無料で公開されているデータセットを使用して、データの読み込みから簡単なデータ解析までを解説します。
データセットについて
・提供元:カルフォルニア工科大学
・内容:心臓病患者の検査データ
・URL :https://archive.ics.uci.edu/ml/datasets/Heart+Disease
・上記URLにあるprocessed.cleveland.dataのみを使用します。
解析目的
データセットは患者の病態を5つのクラスに分類しています。
各クラスの特徴を掴む事を目的に解析を進めてみようと思います。
データのダウンロード
上記URLにアクセスし、Data Folder内にあるprocessed.cleveland.dataをダウンロードします。
データの読み込み
pandasをインポートして、pandasのread_csvメソッドでデータを読み込みます。
データの読み込み時にカラム名を指定しています。カラム名はリストにして、read_csvメソッドのnemesに引数として渡します。
import pandas as pd
columns_name = ["age", "sex", "cp", "trestbps", "chol", "fbs", "restecg", "thalach", "exang", "oldpeak","slope","ca","thal","class"]
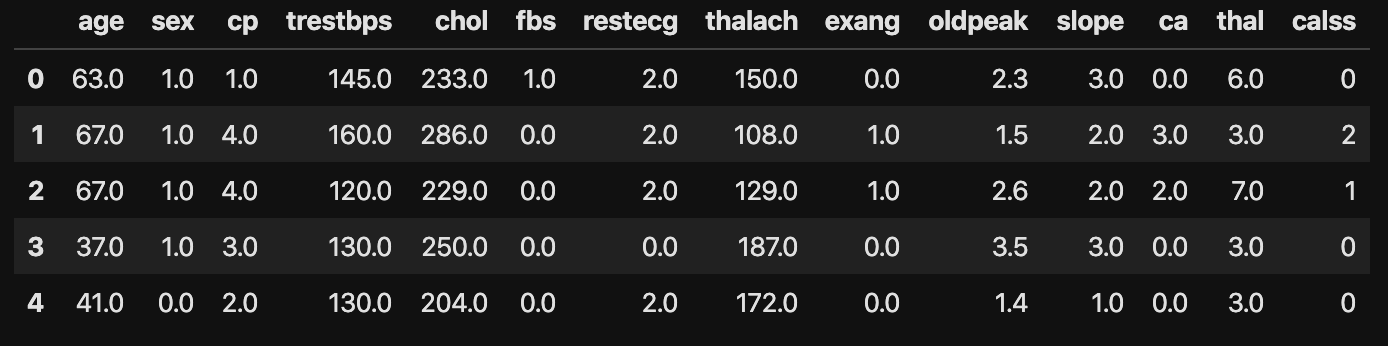
data = pd.read_csv("/Users/processed.cleveland.data", names=columns_name)
# dataの上5行を表示
data.head()
以下が読み込まれたデータです。
簡単にカラムの説明を載せておきます。詳しくはデータ元を参照してください。
・age
・sex (1 = male; 0 = female)
・cp: chest pain type
1:typical angina 2: atypical angina 3: non-anginal pain
4: asymptomatic
・trestbps:resting blood pressure (in mm Hg on admission to the hospital)
・chol:serum cholestoral in mg/dl
・fbs:fasting blood sugar > 120 mg/dl) (1 = true; 0 = false)
・restecg:resting electrocardiographic results
0: normal
1: having ST-T wave abnormality
(T wave inversions and/or ST elevation or depression of > 0.05 mV)
2: showing probable or definite left ventricular hypertrophy by Estes'criteria
・thalach:maximum heart rate achieved
・exang:exercise induced angina (1 = yes; 0 = no)
・oldpeak:ST depression induced by exercise relative to rest
・slope:the slope of the peak exercise ST segment
1: upsloping
2: flat
3: downsloping
・ca:number of major vessels (0-3) colored by flourosopy
・thal:3 = normal; 6 = fixed defect; 7 = reversable defect
・class : 0~5 (0は正常,数字が大きほど悪い)
データの前処理
今回は前処理として、各カラムのデータ型を確認し、数値型でなければ数値型へ変換します。
?と入力された欠損値が存在するので、nullに置換します。
# dataの型を確認
data.dtypes
# 型をfloatに変換,?はnull値に置換
data = data.replace("?",np.nan).astype("float")
データの基礎統計量と欠損値を確認する
各特徴量(変数)毎の確認
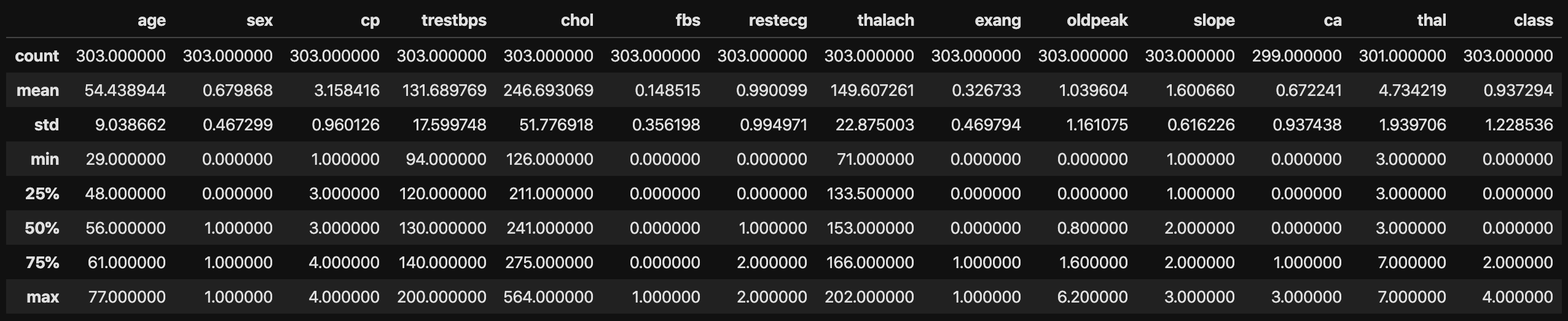
# 統計量を算出
data.describe()
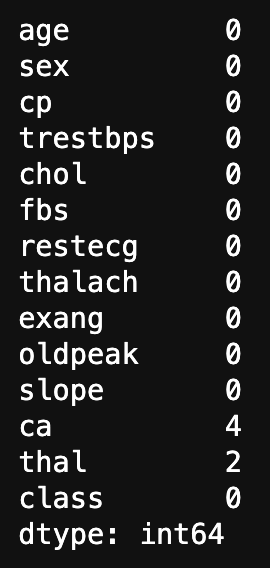
# 欠損値をカウント
data.isnull().sum()
たったこれだけで、各列の統計量を欠損値がわかります。
以下の図は統計量の計算結果です。
各クラス毎の各特徴量(変数)の確認
ここからが本題です。
確認ですが今回の解析目的は各クラス毎の特徴把握です。
この場合pandasのgroup_byメソッドを使用します。
# class列でグループ化
class_group = data.groupby("class")
# クラスを指定して統計量を取得する場合
# class_group.get_group(0).describe()
# カラムが全表示できるようにオプションを指定(notebook)
pd.options.display.max_columns = None
# 全クラスの統計量表示
class_group.describe()
以下は全クラスの統計量を表示させています。

簡単ですね。今回のデータは特徴量(変数)や分類されているクラス数(5つ)も少ないので,全クラスの統計量を表示しても確認出来ますが,これらが多い場合,全て表示させて確認することは難しくなります。
データを可視化する
各特徴量(変数)の分布を確認
ヒストグラムでデータの分布を確認します。
data.hist(figsize=(20,10))
# グラフが重ならないようにする
plt.tight_layout()
plt.show()
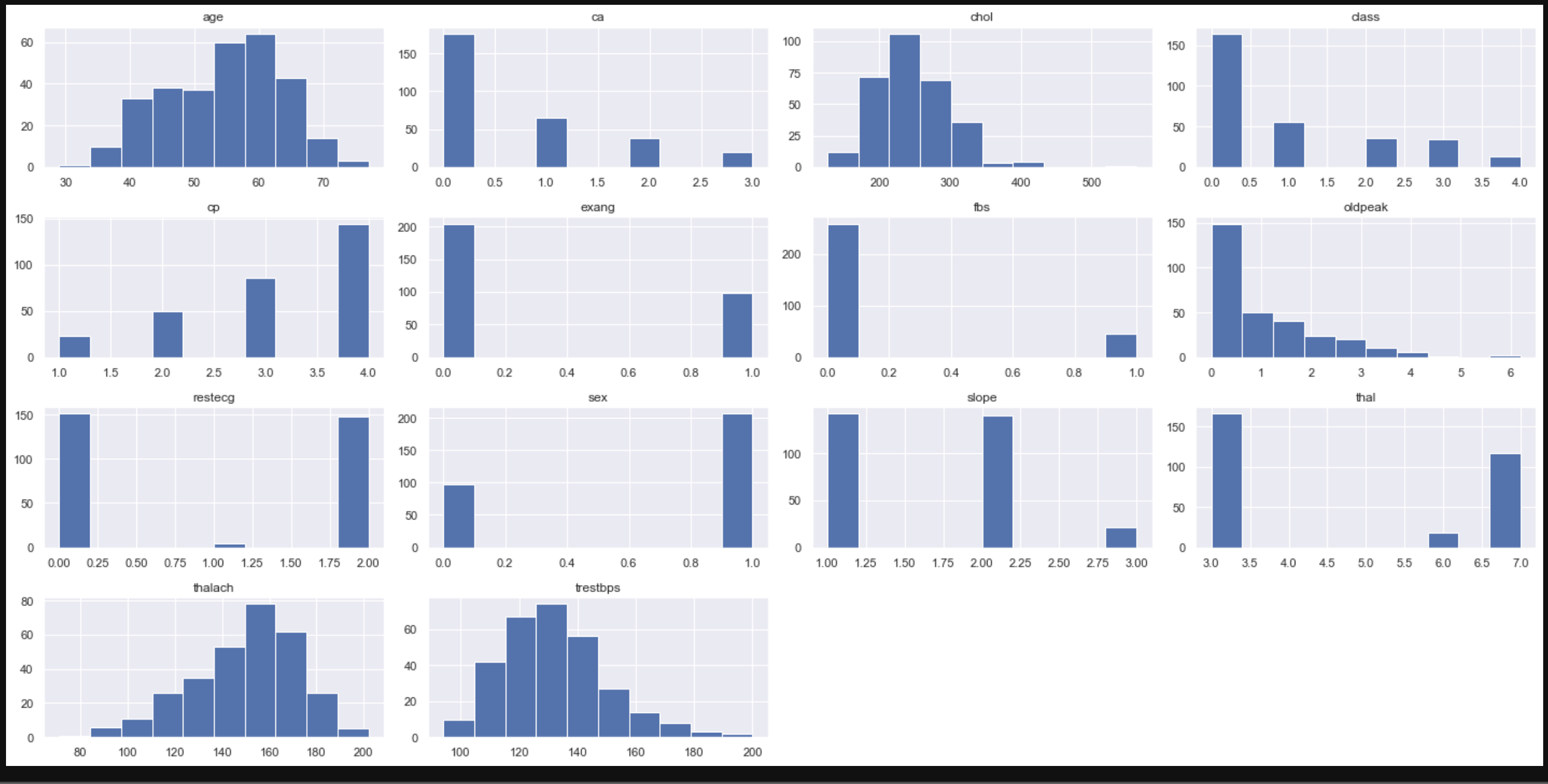
各クラス毎の各特徴量(変数)のヒストグラムを表示
# 単体でのプロット
# class_group["age"].hist(alpha=0.7)
# plt.legend([0,1,2,3,4])
# 全てを表示させる
plt.figure(figsize=(20,10))
for n, name in enumerate(data.columns.drop("class")):
plt.subplot(4,4,n+1)
class_group[name].hist(alpha=0.7)
plt.title(name,fontsize=13,x=0, y=0)
plt.legend([0,1,2,3,4])
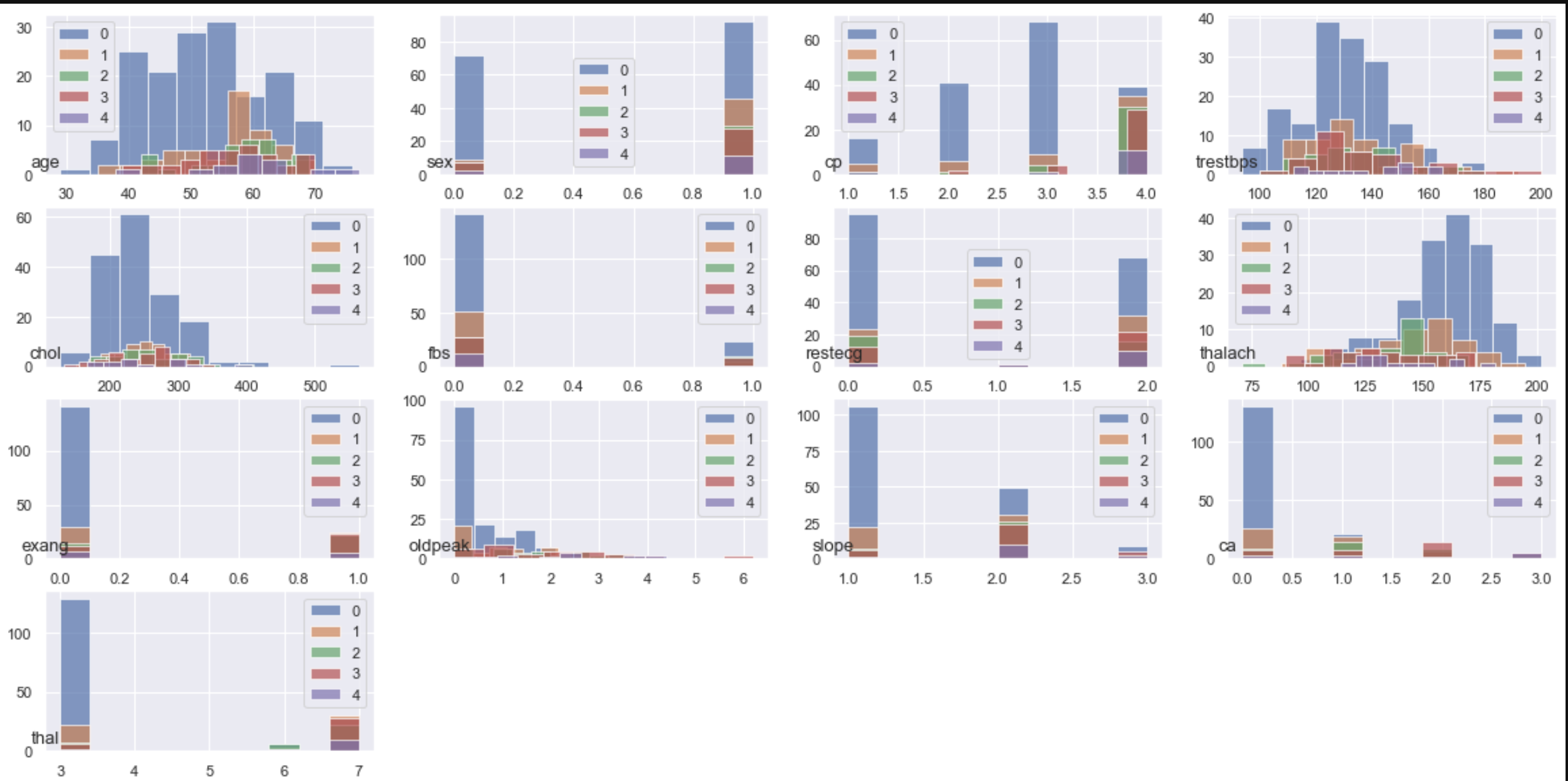
各クラス毎の各特徴量(変数)の平均値と分散を棒グラフに表示
# 単体でのプロット
# class_group.mean()["age"].plot.bar(yerr=class_group.std()["age"])
# 全てを表示させる
plt.figure(figsize=(20,10))
for n, name in enumerate(data.columns.drop("class")):
plt.subplot(4,4,n+1)
class_group.mean()[name].plot.bar(yerr=class_group.std()[name], fontsize=8)
plt.title(name,fontsize=13,x=0, y=0)

ざっと可視化してみましたがクラス毎のヒストグラムなどはこのままではよく見えないです。
次回はグリグリ動かせるグラフや3dプロットなどを使って解析していこうと思います。
pythonではじめるデータ分析 (データの可視化2)
https://qiita.com/CEML/items/e932684502764be09157
pythonではじめるデータ分析 (データの可視化3)
https://qiita.com/CEML/items/71fbc7b8ab6a7576f514