はじめに
・Scrapyをとりあえず使ってみたかったのでScrapyを使ってます。
・この程度であればScrapyよりBeautifulsoupなどを使った方が断然良いですw
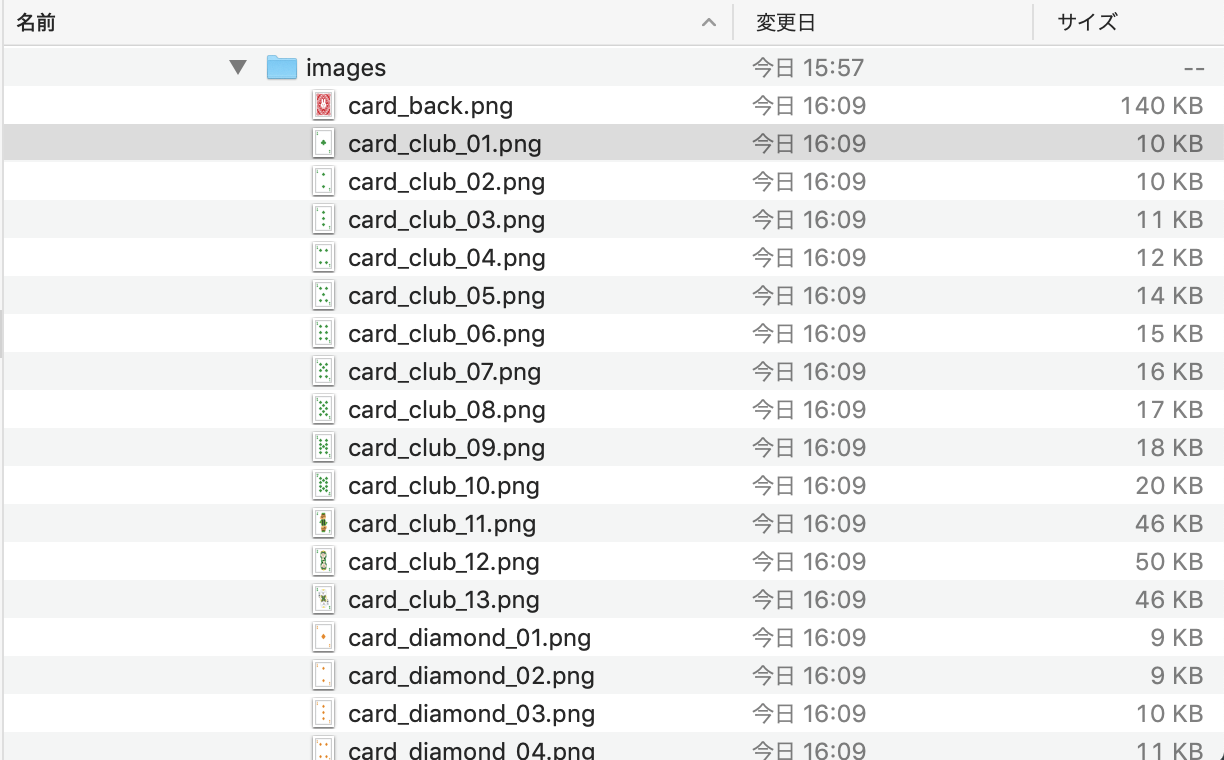
・ダウンロード対象の画像はこのページです。リンク先にあるトランプの画像を全てダウンロードします。
1. scrapyをインストール
$ pip install scrapy
...
..
.
$ scrapy version # バージョンを確認
Scrapy 1.8.0
2. プロジェクトを作成
2-1.
$ scrapy startproject download_images
ディレクトリが出来上がる。
$ cd download_images
download_images $ tree
.
├── download_images
│ ├── __init__.py
│ ├── __pycache__
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ ├── __init__.py
│ └── __pycache__
└── scrapy.cfg
2-2. リクエスト送信間隔の設定
settings.py内DOWNLOAD_DELAYのコメントアウトを外してリクエストの送信間隔をセットしましょう(単位:秒)。
リクエスト間隔が短いとDos攻撃みたいになってしまうので、必ず設定しましょう。
(サイトによってはブロックされてしまいます。)
settings.py
...
..
.
DOWNLOAD_DELAY = 3
.
..
...
2-3. キャッシュを有効にする。
HTTPCACHE_で始まるコードのコメントをアウト外すだけ。
トライ&エラー中、何度も同じページにアクセスしにいく手間がなくなります。
settings.py
.
..
...
HTTPCACHE_ENABLED = True
HTTPCACHE_EXPIRATION_SECS = 0
HTTPCACHE_DIR = 'httpcache'
HTTPCACHE_IGNORE_HTTP_CODES = []
HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
3. 画像をダウンロードする
3-1. Spiderを作成
雛形を作成する
$ scrapy genspider download_images_spider www.irasutoya.com
コマンドの実行ディレクトリは
download_images # ←ココ
├── download_images
│ ├── ...
│ ├── ..
│ ├── .
│ └── spiders
│ ├── __init__.py
│ └── __pycache__
└── scrapy.cfg
すると、spidersディレクトリがこうなる
download_images
├── download_images
│ ├── ...
│ ├── ..
│ ├── .
│ └── spiders
│ ├── __init__.py
│ ├── __pycache__
│ │ └── __init__.cpython-37.pyc
│ └── download_images_spider.py
└── scrapy.cfg
3-3. 作成した雛形ファイルを編集する
download_images_spider.py
# -*- coding: utf-8 -*-
import os, scrapy, urllib
from download_images.items import DownloadImagesItem
class DownloadImagesSpiderSpider(scrapy.Spider):
name = 'download_images_spider'
allowed_domains = ['www.irasutoya.com']
start_urls = [
'https://www.irasutoya.com/2010/05/numbercardspade.html', # スペード(数字)
'https://www.irasutoya.com/2017/05/facecardspade.html', # スペード(絵札)
'https://www.irasutoya.com/2010/05/numbercardheart.html', # ハート(数字)
'https://www.irasutoya.com/2017/05/facecardheart.html', # ハート(絵札)
'https://www.irasutoya.com/2010/05/numbercarddiamond.html', # ダイア(数字)
'https://www.irasutoya.com/2017/05/facecarddiamond.html', # ダイア(絵札)
'https://www.irasutoya.com/2010/05/numbercardclub.html', # クラブ(数字)
'https://www.irasutoya.com/2017/05/facecardclub.html', # クラブ(絵札)
'https://www.irasutoya.com/2017/05/cardjoker.html', # ジョーカー
'https://www.irasutoya.com/2017/05/cardback.html', # 裏面
]
dest_dir = '/Users/~~~/images' # ダウンロード先ディレクトリ
def parse(self, response):
# Webページによって、CSSセレクタを適切なものに書き換える必要があります。
for image in response.css('div.separator img'):
# ダウンロードするファイルのURL
image_url = image.css('::attr(src)').extract_first().strip()
# ダウンロードする画像のファイル名
file_name = image_url[image_url.rfind('/') + 1:]
# 画像のダウンロード先が存在しない場合は作成する
if not os.path.exists(self.dest_dir):
os.mkdir(self.dest_dir)
# ダウンロード
urllib.request.urlretrieve(image_url, os.path.join(self.dest_dir, file_name))
time.sleep(1) # ダウンロード間隔は1秒
トランプの画像をすべてダウンロードできました!