はじめに
本記事は、クラウドインフラにおけるシステム開発時に、インフラの設計として最低限のセキュリテイ対策や、アンチパターンを中心にまとめています。本記事で記載している内容は、特定のクラウドインフラに依存しない普遍的な設計パターンとして適用ができます。
クラウドインフラを利用して、サービスを作るということは、現実の社会にとてもよく似ています。引っ越しを例に説明します。
例えば、内装だけを気にして、家具を購入し、引っ越し後に家具が入らなかったということはよくあるでしょう。これをシステム的に言うと、アプリ先行で考えて、ただクラウドに乗せただけです。これでは、クラウドの恩恵を活かせず、拡張性がない技術的負債のシステムを作る原因になります。
本質として、オンプレだろうがクラウドだろうが、インフラの上にアプリがあってシステムとして成り立っています。
よって、システム開発時に最低限のセキュリテイ対策を行い、アンチパターンを意識して、品質の作り込みを行うことが重要です。
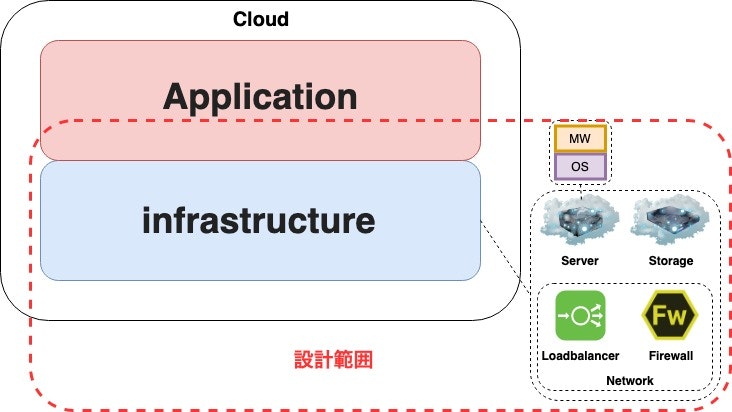
※本記事の内容は、あくまで考え方の一例であり、必ずしも全ての考え方がシステムに適合したり、ここに書いている内容で満たされている訳ではありません。
クラウドインフラ
クラウドインフラ選定時に気をつけることは、そのサービスでできることとできないことを見極めることです。
現在、パブリッククラウドで利用されているサービスは、基本的にインフラリソースをAPIで提供するという形に大差はありません。サーバ、ストレージ、ネットワーク等、必要なリソースを使いたいときに使えるというのがクラウドの本質です。
しかし、サービスによって料金や使い勝手が変わってくるので、仕様を事前に抑えることが重要です。
例として、Oracle Cloud PlatformのOracle Cloud Infrastructure - Compute(※)は、オンラインでの拡張ができません。運用中にサーバリソース等のを拡張(スケールアップ)したい場合は、システム停止が必要になります。
(※)AWS(Amazon Web Services)のEC2(Amazon Elastic Compute Cloud (Amazon EC2))や、GCP(Google Cloud Platform)のGCE(Google Compute Engine)に相当
以降、本記事の一部内容については、Oracle Cloud Infrastructureを例に解説しています。
インスタンス
インスタンスとしてLinuxを選択する場合、最初に検討しないといけないのはOS選定です。
アンチパターンは、理由なき現行踏襲や何となく決めてしまうことです。
設計として大事なことは、何らかの理由や根拠に基づいて選定し、決定することです。
クラウドインフラで利用されるLinuxで、ライセンス無料で使用できるOSは、CentOSとUbuntuがよく使われますが、それぞれ一長一短があるのでしっかりと見極めましょう。
| CentOS | Ubuntu | |
|---|---|---|
| 系統 | RHEL | Debian GNU/Linux |
| 対応プラットフォーム | IA-32, x64 | i386, AMD64,PowerPC, ARM |
| カーネル種別 | モノリシックカーネル | モノリシックカーネル |
| パッケージ管理 | RPM,YUM,DNF | dpkg |
| 特徴 | サポート期限が非常に長く、パッケージの更新頻度が少ないため、安定性にも優れている | TensorFlow等、ディープラーニングで使用するライブラリはUbuntuファーストで開発されている |
| マイナーリリース | 年2~4回 | 4月,10月 |
| サポート期間 | 10年(CentOS 4以前は約7年) | 18.04 LTSから10年 |
| シェア | 日本ではCentOSの方が人気 | 海外ではUbuntuの方が人気(※) |
(※)DistroWatchの2018年のランキングでは、Centosが12位、Ubuntuは5位
海外の質問サイトQuoraの過去のQAを見ると、CentOSをビジネスで使うべき理由が見つかります。
私はこのフォーラムの投稿の大部分に同意します。本格的な - 企業に近いレベルの場合、CentOSはあなたにぴったりです。
たとえば、cPanelはUbuntuでは機能しません。cPanelが必須の場合は、Red Hatベースを検討する必要があります。
Ubuntuは、Linuxを勉強したいと思っていて、どこから始めればいいのかわからない人にとって、使いやすく優れたデスクトップおよび完璧なスターターサーバーです。
私はそれらの両方を試してみました、そしてそれが私が最もよく知っているシステムであったとしても、私は本当にUbuntuで苦労しました。例えば、Ubuntuは動きが速く不安定です。
サーバーの観点からすると、ネットワークカードなどの重要な設定がドライバに変更されたことを確認するために新しいアップデートをダウンロードする必要はありませんでした。時々、Ubuntuはアップデートを停止します。
デスクトップの場合、これらの問題は簡単に解決できますが、コマンドラインを使用しなければならないことは、ヘッドレスサーバーを扱うときの別の話です。
したがって、企業で最も使用されているもの、つまりRed Hat / CentOSを選択してください。
2つの間のもう一つの違いはパッケージ管理システムです。RPMは依存関係のインストールに関してはあまり役に立ちません。なぜならそれはdebianインストーラを使うほうがずっと簡単だからです。
Red Hatベースのサーバー用のユーザーフレンドリーなデスクトップが必要な場合は、SUSE Linuxエンタープライズサーバーまたはその他のNovell製品を選択してください。
私のアドバイスはCentOSをビジネスに使うことです。
Linuxセキュリティ設計
Linuxサーバのセキュリテイ対策について、CentOS等RHEL系を例に解説します。
なお、本記事で記載している内容は、オンプレでも適用できます。
ディスクパーティションの設計
RHEL系の場合 、/boot/、/、/home/、/tmp/、及び /var/tmp/ の各ディレクトリー毎に個別のパーティションを作成することを推奨しています。
- /boot
ブート時にシステムが最初に読み込むパーティション。なお、このパーティションは暗号化すべきではありません。/boot領域に対して暗号化を行うと、起動ができなくなります。 - /home
ユーザのホームディレクトリ。別個のパーティションではなくシステム領域の/ に含まれていると、このパーティションが一杯になった場合、OSが不安定になる可能性があります。 - /tmp及び/var/tmp
ダンプ領域等で使われるディレクトリ。これらtmpディレクトリが / に含まれていると、これらパーティションが一杯になった場合、OSが不安定になりクラッシュする可能性があります。
必要なパッケージの最小限のインストール
使用しないサービスが起動していると、不要なポートが空いた状態になったり、ソフトウェアに脆弱性がある場合、サーバに侵入を許すリスクが高まります。よって、根本的にセキュリティ対策を考える場合は、OSインストール時に実際に使用するパッケージのみをインストールすることがベストプラクティスになります。
脆弱性対策
セキュリティの脆弱性が発見された場合、セキュリティ上のリスクを最小限に抑えるために、影響を受けるソフトウェアを更新する必要があります。
以下にセキュリティに関するyumコマンドの操作方法について記載します。
- 使用中のシステムで利用可能なセキュリティー関連の更新を確認
# yum check-update --security
このコマンドは、利用可能なセキュリティー更新がある場合には 100 を返し、更新がない場合には 0 を返します。エラーが発生すると、1 が返されます。
-
セキュリティ関連の更新のみがインストール
# yum update --security -
リポジトリーが提供する利用可能な更新についての情報を表示
# yum updateinfo -
署名パッケージの検証
# cat /etc/yum.conf | grep gpgcheck
攻撃者により改ざんされたパッケージのインストールを防ぐため、yum install実行時にパッケージの署名を検証します。Yum パッケージマネジャーは、インストールまたはアップグレード対象の全パッケージを自動的に検証できます。この機能は、デフォルトで有効になっています。
/etc/yum.conf 設定ファイル内で gpgcheck 設定ディレクティブが 1 に設定されていることを確認します。
-
ファイルシステム上のパッケージファイルを手動で検証
# rpmkeys --checksig package_file.rpm -
特定ライブラリにリンクしている実行中のアプリケーションを判別
# lsof /lib64/libwrap.so.0
例)libwrap.so ライブラリにリンクしている実行中のアプリケーションを判別する場合
[root@localhost ~]# lsof /lib64/libwrap.so.0
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
auditd 480 root mem REG 8,1 42520 12624381 /usr/lib64/libwrap.so.0.7.6
sshd 836 root mem REG 8,1 42520 12624381 /usr/lib64/libwrap.so.0.7.6
sshd 1276 root mem REG 8,1 42520 12624381 /usr/lib64/libwrap.so.0.7.6
このコマンドは、ホストのアクセス制御に TCP Wrapper を使用する実行中のプログラムの一覧を返します。そのため tcp_wrappers パッケージが更新されると、リストにあるすべてのプログラムは停止してから再起動する必要があります。
なお、systemdサービスはOS起動時にメモリにロードしているため、パッケージを更新したした際はsystemdのサービスを再起動する必要があります。カーネルのバージョンアップについても、OS再起動することで修正が適用されます。
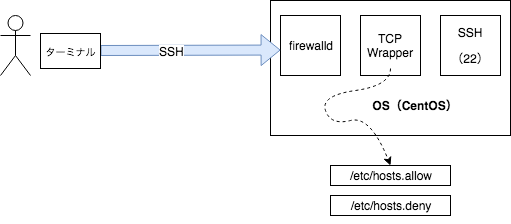
TCP Wrapper
TCP Wrapper は、LinuxやBSD系の(Unix系)OSに対して、TCP/IPレベルでネットワークアクセスをフィルタリングする仕組みです。
かつては、1台のサーバで複数のサービス(FTPサーバ、TELNETサーバ等)を稼働させておくには、それぞれのサービスのデーモン(ftpd、tftpd等)を起動して、それぞれのデーモンが、それぞれの待ち受けポートを監視する仕組みをとっていました。しかし、これでは各デーモンを常駐させることになるため、メモリの消費量が多くなります。
そこで、inetdののようなスーパーサーバが待ち受けポートの監視を代行することで、アクセス許可を行なうようになりました。しかし、inetdが中継動作することとなるので、動作レスポンスが遅れるため、httpd等はinetdを経由させず常時起動させておくことが多かったようです。
TCP Wrapper の仕組みはいたって単純です。
以下の二つのファイルを用意してアクセス制御を行ないます。
- /etc/hosts.allow
- /etc/hosts.deny
仕組みとしては、TCPでラップされたサービスがクライアントの要求を受け取り、以下の制御が実行されます。
- /etc/hosts.allowを参照し、マッチするルールがあれば接続を許可する
- /etc/hosts.denyを参照し、マッチするルールがあれば接続を拒否する
- /etc/hosts.allowと/etc/hosts.denyのどちらにもマッチするルールがなければ、接続を許可する
ファイアウォール
RHEL系ならfirewalld、debian系ならufw等を使用して、ファイアウォールを設定しましょう。
クラウドのファイアウォールだけでなく、OSのファイアウォールもきちんと設定することで意図しない通信を防ぐことができます。
SELinux(Security-Enhanced Linux)
Linuxによるアクセス制御は、任意アクセス制御と強制アクセス制御に大別できます。
-
任意アクセス制御(Discretionary Access Control)
ディレクトリやファイルといったリソースに対するアクセス制御をパーミッションで制御します。「オーナー」、「グループ」、「その他ユーザ」に対してそれぞれ「読み込み」、「書き込み」、「実行」の許可を設定します。また、ACLを設定することで特別なアクセス制御を行うことができます。 -
強制アクセス制御(Mandatory access control)
SELinuxは1992年、アメリカのNSAが主体となって開発されたセキュアOSの一つになります。他にも強制アクセス制御を実装したものではAppArmor(Application Armor)などがあります。強制アクセス制御は、全てのファイルとプロセスをオブジェクトとして、セキュリティコンテキストと呼ばれるラベルをプロセスやリソースに付与します。そして、ポリシーに沿ったアクセス制御を行うことで、rootさえも制御する機能を提供します。アクセス制御の実体は、ホワイトリスト形式になっていて、あらかじめ定義したアクセスルール以外のアクセスについてはすべて拒否します。
よって、アクセス制御のポリシーの設定変更さえ理解すれば、SELinuxを自由に扱うことができます。但し、SELinuxの設定方法が煩雑なのは知られている通りで、今はその設定方法を抽象化したブール値等ツールがあるので、それらを利用することでより簡単にSELinuxを実装することができます。
Linuxのアクセス制御は最初にDACでの確認が行われ、次にMACによる確認が行われます。つまり、DACでのアクセス制御が許可されていることが前提になります。DAC ルールが最初にアクセスを拒否すると、SELinux ポリシールールは使用されません。
SSH設定及びsu実行ユーザの制限
どのクラウドインフラでも、外部からのポート22を許可していると、インスタンス作成後すぐに海外からSSHのデフォルトポートに対する不正アクセスが行われます。
不正アクセスに対しては、SSHの僅かな設定でセキュリテイレベルを上げることができます。
ワンライナーで設定できるコマンドを以下に記載します。設定後は、sshの再起動が必要です。
なお、設定ファイルのバックアップは事前に取得しましょう。また、OSの種類によっては、最初からwheelグループが存在しない場合があります。もし、存在しない場合はwheelグループを作成します。
-
デフォルトポート変更
# sed -i -e "s/#Port 22/Port <変更するポート番号>/g" /etc/ssh/sshd_config -
rootログイン禁止
# sed -i -e "s/#PermitRootLogin yes/PermitRootLogin no/g" /etc/ssh/sshd_config -
wheelグループのみsshを許可
# sed -i '$a\AllowGroups wheel' /etc/ssh/sshd_config -
wheelグループのみsuを許可
# sed -i -e "s/^#auth\t\trequired\t/auth\t\trequired\t/g" /etc/pam.d/su
ネットワーク
クラウドインフラは簡単にネットワークを作成することができます。
プライベートアドレスは、RFC1918のレンジを前提とし、作成後は変更不可であることを認識した上で設計しましょう。
パブリックサブネットとプライベートサブネットを適切に分けずに、全てパブリックサブネットに公開しているシステムはアンチパターン以外に何物でもありません。
以下はアンチパターンなシステム構成とセキュアなシステム構成の比較です。
- アンチパターンなシステム構成
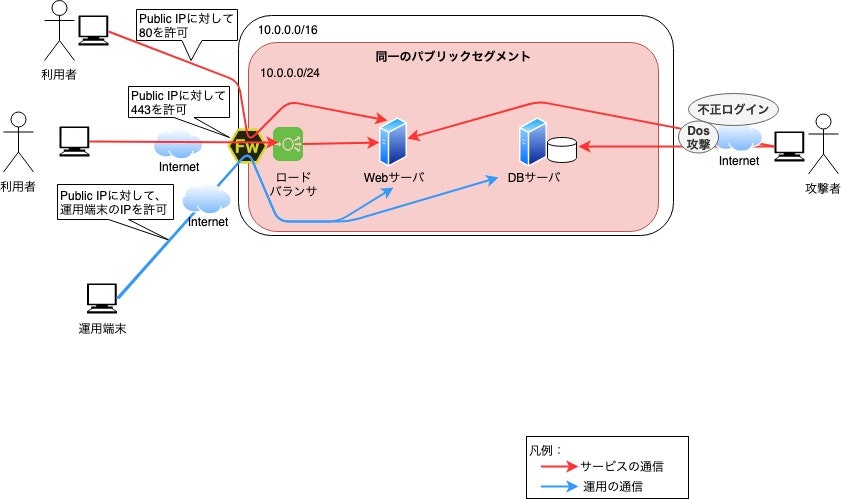
全てのサーバが同一のパブリックセグメントに存在し、ファイアウォールの設定が緩く、インスタンスに直接アクセスできる場合は、システムを危険な状態にさらしている
- セキュアなシステム構成
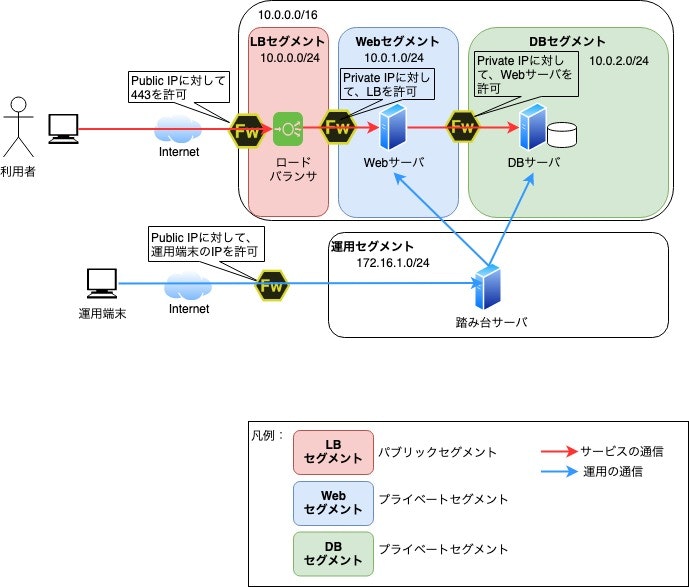
全てのサーバは別々のセグメントに存在しているため、アクセスは局所的になる。また、運用でサーバにログインする場合は踏み台経由でないとログインできないため、セキュリティを向上させる
ポイント
- サービスで使用するセグメントと運用で使用するセグメントの分離
- WebサーバやDBサーバへのSSHは踏み台サーバからのみ許可する
- SSHのポート番号はデフォルトから変更する
- SSHのパスワードは複雑なパスワードを設定する
- 踏み台サーバへのSSHは、送信元を信頼された運用端末からのみ許可する
- 各セグメントへの通信をファイアウォールで適切に設定する
SSHのポートフォワーディング
上記、セキュアなシステム構成の場合、そのままではローカルのDBeaver等SQLクライアントツールを使用することができません。
SSHのポートフォワーディングを使用することで、透過的に踏み台サーバ経由でSQLクライアントツールが使用できます。Macを例に手順を記載します。
まずは、ターミナルを起動し、以下のコマンドを実行して、SSHのポートフォワーディングを行います。
# ssh -f -N -L <ローカル端末の任意のポート番号>:<DBサーバのプライベートIP>:<DBサーバのポート番号> <ユーザ名>@<踏み台サーバのパブリックIP> -i <SSHの秘密鍵> -p <変更したSSHのポート番号>
上記、セキュアなシステム構成の図の例(DBはMySQLとする)
# ssh -f -N -L 13306:172.16.1.2:3306 user@<踏み台サーバのパブリックIP> -i id_rsa -p <変更したSSHのポート番号>
次に、DBeaverを起動し、データベースナビゲータに新しいデータベースを追加し、以下を設定します。
Server Hostは、ローカルホストを指定(localhostまたは127.0.0.1)
Portに上記、SSHのポートフォワーディングで指定した任意のポート番号を指定

もし、「SQL Error [08001]: Public Key Retrieval is not allowed」のエラーメッセージが表示された場合は、ドライバのプロパティより、allowPublicKeyRetrievalをtrueにを設定することで接続できます。

ストレージ
ストレージは、ブロックストレージ、オブジェクトストレージ、ファイルストレージに大別できます。
クラウドインフラでデータベースを構築する場合、データベースで使用するデータ領域は、システム領域ではなく、ブロックストレージ等別領域に分けるのが定石です。また、データベースで使用する場合は、ブロックストレージが適していると考えます。
以下、Oracle Cloud Infrastructure Block VolumesのFAQより引用
ブロック・ボリュームとは、ファイル・ストレージよりも拡張性の高いデータ・ストレージ・タイプです。ブロック・ボリュームは、iSCSI Ethernetプロトコルを使用して、オンプレミスのストレージ・エリア・ネットワーク(SAN)に似た機能とパフォーマンスを実現するもので、データのライフ・サイクルのセキュリティと耐久性を高めるよう設計されています。Oracle Block Volumesを使用すると、ブロック・ボリュームを作成してコンピュート・インスタンスにアタッチできます。
データベースのデータ領域がシステム領域になっていると、ディスク容量不足時に柔軟な拡張ができません。データ領域を分けることで、ディスクIOやディスク枯渇を考慮した運用が行えます。
データ領域の作成
データ領域の作成手順について記載します。
まずは、クラウドインフラ上で、データ領域に割り当てるためのストレージを作成し、インスタンスにストレージを割り当てます。ストレージの割り当てはクラウドインフラによって違うため、本記事では割愛します。
次に、ディスクパーティションを作成するため、partedを起動します。(fdiskは使用しないこと)
以下はデバイスファイルが/dev/sdbで、partedを対話的に実行した際の出力です。
-
ディスクパーティションの作成
# parted /dev/sdb- mklabelでラベルをgptに指定
- mkpartでファイルシステムをxfsに指定し、全ての領域を割り当てる
(parted) mklabel gpt
(parted) mkpart
Partition name? []? "Linux filesystem"
File system type? [ext2]? xfs
Start? 0%
End? 100%
(parted) p
Model: ORACLE BlockVolume (scsi)
Disk /dev/sdb: 53.7GB
Sector size (logical/physical): 512B/4096B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name Flags
1 1049kB 53.7GB 53.7GB Linux filesystem
(parted) quit
Information: You may need to update /etc/fstab.
ディスクパーティション作成後、ファイルシステムを作成します。
- ファイルシステム作成
# mkfs.xfs /dev/sdb1
ファイルシステムを作成するとUUIDが認識されるので確認します。
- UUIDの確認
# lsblk -o +UUID
最後に、/etc/fstabを設定し、マウントを行います。
ポイントは、インスタンス起動時にデータ領域のマウントが失敗しても、インスタンスが起動できるように、nofailオプションを指定します。
- /etc/fstabの設定
# vi /etc/fstab
UUID=UUID(※) /data xfs defaults,_netdev,nofail 0 2
(※)UUIDは、lsblk -o +UUIDで出力された値を入力する
-
マウント
# mount -a -
マウント確認
# df -h
/dev/sdb1 50G 84M 50G 1% /data
データベース
最後に、上記で作成したデータ領域をデータベースで使用する場合の方法について記載します。
データベースは、二大巨頭であるMySQL(※)とPostgreSQLについて解説します。
(※)MySQL8
MySQL
MySQLインストール後、はじめに以下の設定を行います。
なお、MySQLの設定はmy.cnfで行いますが、読み込む順番があるため、注意しましよう。
順番を確認したい場合は、以下のコマンドで確認できます。
# mysql --help | grep my.cnf
order of preference, my.cnf, $MYSQL_TCP_PORT,
/etc/my.cnf /etc/mysql/my.cnf ~/.my.cnf
また、my.cnfは更に中で別ファイルを読み込む設定になっています。
本記事では、/etc/mysql/mysql.conf.d/mysqld.cnfで設定します。
- /etc/mysql/mysql.conf.d/mysqld.cnf
# 変更前
datadir = /var/lib/mysql
# 変更後(※)
datadir = /data/mysql
(※)/dataディレクトリをデータ領域としてマウントしています。
次に、以下のコマンドを実行し、必要なファイルをデータ領域にコピーします。
cp -arp /var/lib/mysql /data/
最後にMySQLのサービスを再起動することで、ブロックストレージであるデータ領域をMySQLのデータベースとして使用することができます。
なお、データ領域変更後、MySQLが起動できない例を以下に記載します。
以下のログは、OSがUbuntuでデータ領域変更後、MySQL起動に失敗し、システムログに出力されたメッセージです。
メッセージの意味は、AppArmorの強制アクセス制御により、起動が失敗しています。
Jul 31 15:26:48 my-database-db kernel: [ 2500.940894] audit: type=1400 audit(1564554408.606:27): apparmor="STATUS" operation="profile_replace" info="same as current profile, skipping" profile="unconfined" name="/usr/sbin/mysqld" pid=3587 comm="apparmor_parser"
Jul 31 15:26:48 my-database-db kernel: [ 2501.299944] audit: type=1400 audit(1564554408.967:28): apparmor="DENIED" operation="mknod" profile="/usr/sbin/mysqld" name="/data/mysql/mysqld_tmp_file_case_insensitive_test.lower-test" pid=3588 comm="mysqld" requested_mask="c" denied_mask="c" fsuid=110 ouid=110
Jul 31 15:26:48 my-database-db kernel: [ 2501.304108] audit: type=1400 audit(1564554408.971:29): apparmor="DENIED" operation="mknod" profile="/usr/sbin/mysqld" name="/data/mysql/mysqld_tmp_file_case_insensitive_test.lower-test" pid=3588 comm="mysqld" requested_mask="c" denied_mask="c" fsuid=110 ouid=110
Jul 31 15:26:48 my-database-db kernel: [ 2501.304295] audit: type=1400 audit(1564554408.971:30): apparmor="DENIED" operation="open" profile="/usr/sbin/mysqld" name="/data/mysql/binlog.index" pid=3588 comm="mysqld" requested_mask="wrc" denied_mask="wrc" fsuid=110 ouid=110
Jul 31 15:26:48 my-database-db systemd[1]: mysql.service: Main process exited, code=exited, status=1/FAILURE
Jul 31 15:26:48 my-database-db systemd[1]: mysql.service: Failed with result 'exit-code'.
Jul 31 15:26:48 my-database-db systemd[1]: Failed to start MySQL Community Server.
そのため、AppArmorを回避する場合は、以下のコマンドを実行して無効にすることで、正常にMySQLが起動できます。
# ln -s /etc/apparmor.d/usr.sbin.mysqld /etc/apparmor.d/disable/
# apparmor_parser -R /etc/apparmor.d/usr.sbin.mysqld
PostgreSQL
PostgreSQLはMySQLとアーキテクチャが違いますが、データ領域を使用するのに特別な設定はありません。
データベースクラスタ作成時(initdbコマンド実行時)に、pgdataのオプションにデータ領域を指定するのみです。以下はコマンドの実行例になります。
# initdb -D /usr/local/pgsql --pgdata=/usr/local/pgsql/data --encoding=UTF-8 --locale=ja_JP.UTF-8 --username=postgres
バックアップ
データ領域を別にするもう一つのメリットは、データベースバックアップをクラウドインフラの機能を使用して、簡単に取得することができます。
例えば、Oracle Cloud Infrastructureでは、ブロックストレージのバックアップが簡単に取得できます。
以下、Oracle Cloud Infrastructure Block VolumesのFAQより引用
バックアップはポイントイン・スナップショットを使用して行われるため、バックアップがバックグラウンドで非同期的に実行されている間、中断およびパフォーマンスへの影響なしに、アプリケーションは引き続きデータにアクセスできます。
RPO(目標復旧地点)
インフラの設計について、本記事で全てを取り上げるのは難しいため、システム設計のフレームワークである、非機能要求グレードをベースに、データベースバックアップに係わる重要な項目として、グレード表の項番「A.1.3.1」を例にして解説します。
グレード表の項番「A.1.3.1」で定義する内容は以下になります。
業務停止を伴う障害が発生した際、何をどこまで、どれ位で復旧させるかの目標。
つまり、要件定義で定義したレベルにより、どこまで戻すかが決まります。
レベル3の場合、しっかりとした運用設計が必要になってくるため、クラウドインフラの機能だけではなく、データベースを障害発生時点までの状態まで復旧させる設定が必要になります。
また、非機能要求グレードですが、非機能要求グレード2018として、去年アップグレードされています。非機能要求グレードお持ちの方で、古い方はアップデートしましょう!
おわりに
設計の妥当性は、実際に運用がはじまったときに、どれだけ設計時とのギャップが発生しないかが、評価のポイントになってくると思います。なお、そのギャップが少しの手直しで済むならまだしも、システムを止めて直す必要がある場合は、単なる設計ミスです。
また、完全というものは存在しませんが、どれだけ最善を尽せるかが、運用として設計冥利に尽きるものです。
サーバレスという新しい技術がありますが、世の中、まだまだサーバで動いているシステムはたくさんあります。
正しいLinuxの知識を身につけて、堅牢なシステムを作りましょう![]()
参考
過去に書いたセキュリテイに関する記事です。