参考URL
昨日に続いて、クラスメソッドさんの記事を見て勉強を続けていきます。
https://dev.classmethod.jp/cloud/aws/lambda-my-first-step/
オブジェクト情報の取得
昨日の記事で実施した部分はオブジェクトが所定の場所に置かれることで起動するトリガーについて触れました。
今回はそこからさらに進んで、昨日、定義したLambdaのハンドラーで指定した引数eventに含まれている「バケット名」とか、「パス」の情報を取得してみます。
コードを以下のものに差し替えます。
def lambda_handler(event, context):
print("Lambdaが呼ばれたよ!!!!!!")
input_bucket = event['Records'][0]['s3']['bucket']['name']
input_key = event['Records'][0]['s3']['object']['key']
print("bucket =", input_bucket)
print("key =", input_key)

差し替えが終わって、コードを保存したら、またS3上の所定フォルダにテキストファイルをアップしてみます。
また、例のごとく、Cloud Watchにログインして、ログを確認してみます。
おっ!ログが増えてます。

ログ結果を確認すると確かにバケット名とアップロードしたテキストファイル名を取得できています。

テストの実行
記事によりますと、昨日までで用意していた空のjsonファイルだとエラーが出力されるとのことでした。
実際に実行してみますと、確かにエラーが出力されました。
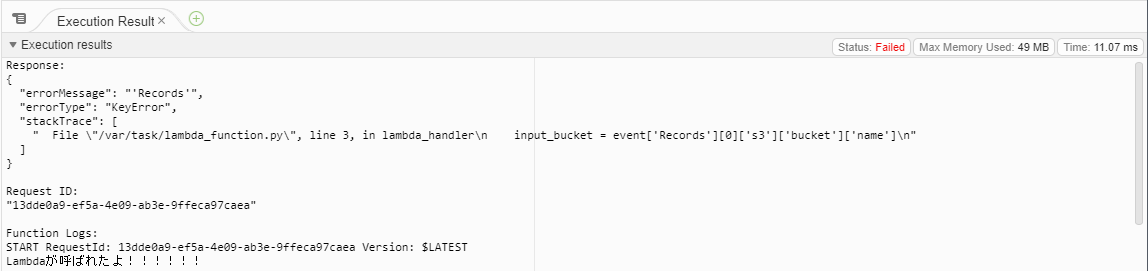

エラーを出力させないためには「バケット」と「ファイルパス」の情報を渡してやればよいとのことです。
実際に渡してみたら、エラーが解消するのか確認してみました。
↓のような感じでテンプレートをベースにバケット名、ファイルパス(key)の情報を入力してテストを実行してみます。
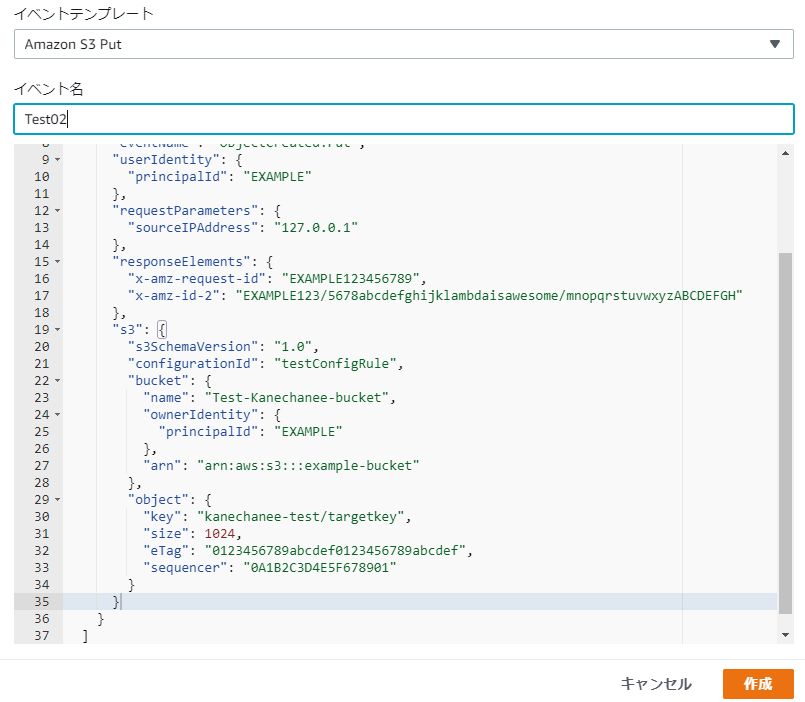
おっ!エラーは出ずに、私が適当に突っ込んだ値を無事に取得することができました!
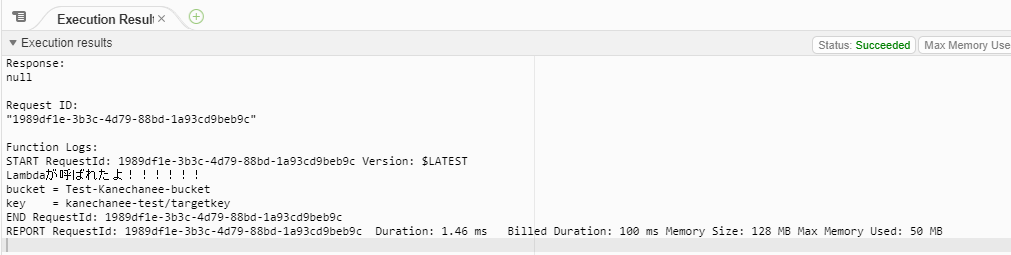
記事にも記載されているのですが、この時点で現段階のLambdaで使用しているロールにはS3に対するアクセス権は設定されていない状態です。
なのにも関わらず、バケット名とファイルパスを取得できているのはトリガーイベントから受け取っている情報だからになるそうです。
ロールの制限を受けることなく、トリガーイベントとして取得している情報はLambdaデフォルトのロール権限で無制限に取得可能だということを理解しました。
ファイルコピーする関数の作成
また、コードを差し替えます。
import boto3
s3 = boto3.client('s3')
def read_file(bucket_name, file_key):
response = s3.get_object(Bucket=bucket_name, Key=file_key)
return response[u'Body'].read().decode('utf-8')
def upload_file(bucket_name, file_key, bytes):
out_s3 = boto3.resource('s3')
s3Obj = out_s3.Object(bucket_name, file_key)
res = s3Obj.put(Body = bytes)
return res
def lambda_handler(event, context):
print("Lambdaが呼ばれたよ!!!!!!")
input_bucket = event['Records'][0]['s3']['bucket']['name']
input_key = event['Records'][0]['s3']['object']['key']
print("bucket =", input_bucket)
print("key =", input_key)
# S3からファイルを読み込み
text = read_file(input_bucket, input_key)
# outputのキーを設定
output_key = "outputs/" + input_key
# ファイルをS3に出力
upload_file(input_bucket, output_key, bytes(text, 'UTF-8'))
上記の処理はlambda_handlerって関数で取得したバケット名、ファイルパス名をread_fileとupload_fileって関数でそれぞれ、流用する形で別ファイルの形で別のバケットへアップロードするものになるようです。
先頭のimport boto3が気になったのですが、こちらはAWSをPythonから利用するためのライブラリとのことです。※詳細は以下に。
Python boto3 でAWSを自在に操ろう ~入門編~
https://qiita.com/kimihiro_n/items/f3ce86472152b2676004
では昨日、自動的に作成されたLambdaのロールにS3へのアクセス権を付与してみます。
まずはIAMへアクセスし、先日、作成したロールを選択します。
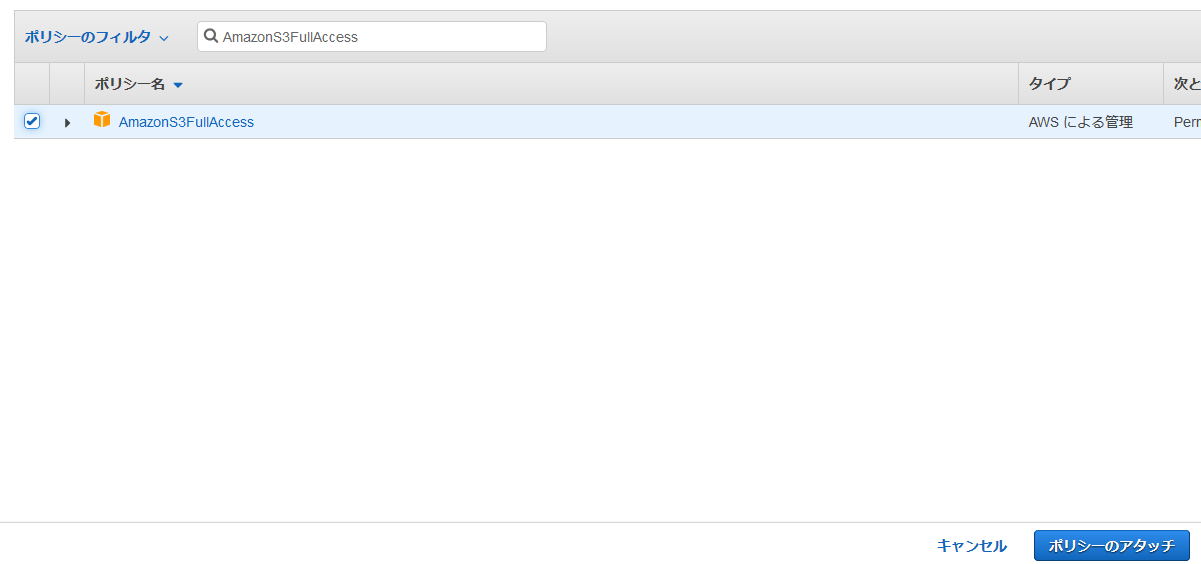
記事で紹介されている通り、ここは何も考えず、AmazonS3FullAccessを付与しておきます。
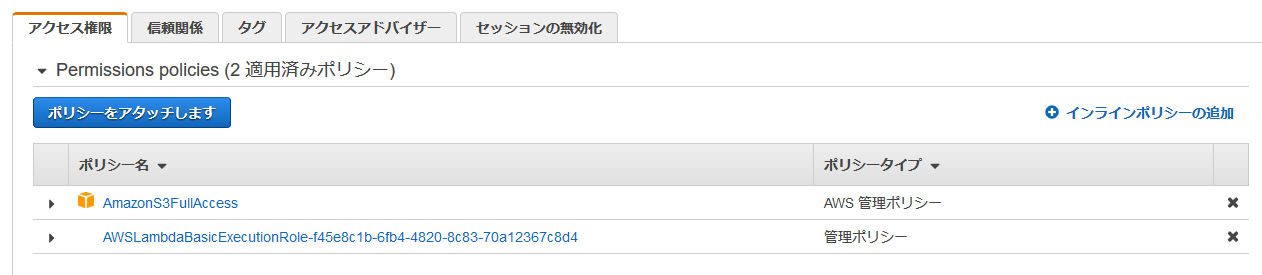
IAMとは別に、Lambda上でもアクセス権が増えていることが確認できました。
ではこのパワーアップした関数が動作するのか、確認してみます。
動作確認
実際にS3上にファイルをアップロードしてみます。
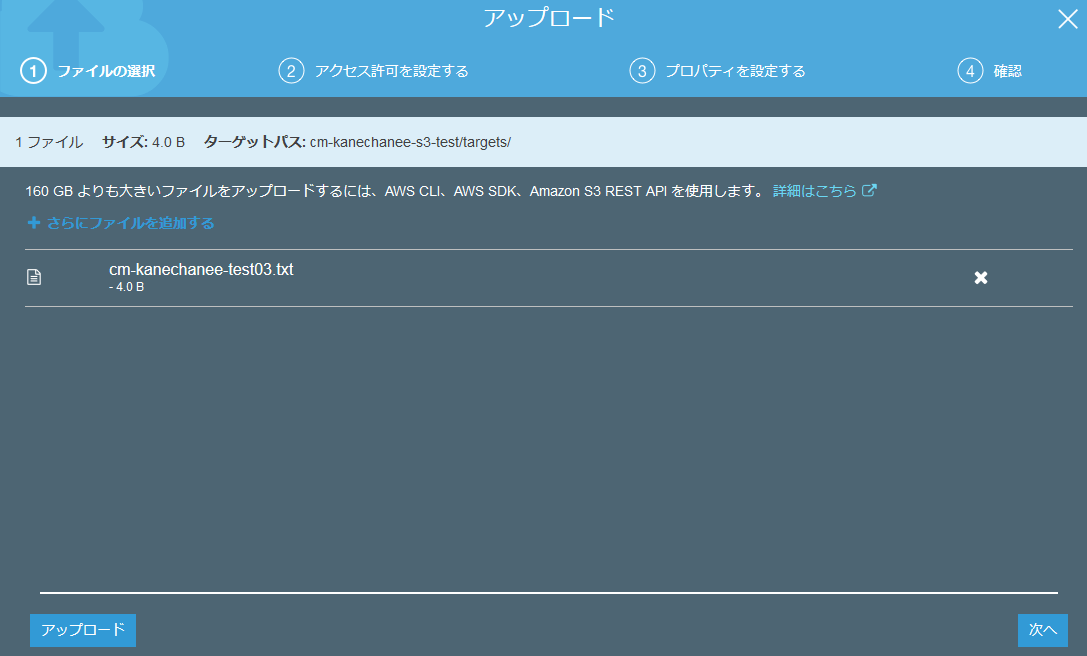
そして、例のごとく、Cloud Watchへ飛んでみると、
おっ!また、新しいログが出てます!

えっ、ただ、ログには前回までと同じような内容しか出てないなー(汗
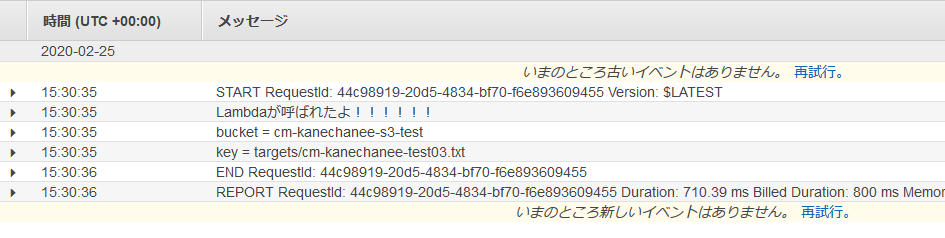
ただ、「何か間違ってたのかなー」とちょっとあきらめ気味にS3バケット内のフォルダを確認してみたところ、なんと!「outputs」フォルダが出来ているではありませんか!

「outputs」フォルダの中には「targets」フォルダが!

おー、ちゃんとファイルがコピーされてますね!

ログの出力だけ疑問が残ったので、よくよく考えたら、print処理している内容変わってなかっただけでした笑
ひとまず出来ましたー!というわけで、今回、参考にさせていただいた記事はここまででしたので、
明日もまた、別の記事をベースに勉強したいと思います。