VS Code の AI チャットで、Ollama 上のローカル LLM を選べるようにしたので、設定手順と使いどころをまとめます。
この記事では、VS Code の GitHub Copilot Chat / Chat ビューから Ollama のモデルを選び、ローカルモデルでコード相談や簡単な修正依頼をするところまでを扱います。
できるようになること
- VS Code のチャット画面からローカル LLM を選べる
-
qwen系やgpt-oss系など、Ollama に入っているモデルを AI コーディングに使える - クラウドモデルとローカルモデルを、タスクに応じて切り替えられる
ローカル LLM は「すべてが完全オフラインになる」という意味ではありません。VS Code / GitHub Copilot 側の機能を使う場合、Copilot の認証や一部サービス接続が必要になることがあります。一方で、実際の推論を Ollama のローカルモデルに寄せられるのが大きなメリットです。
前提
必要なものは次の通りです。
- VS Code
- GitHub Copilot Chat が使える状態
- Ollama
- Ollama に pull 済みのローカルモデル
Ollama 公式の VS Code 連携ドキュメントでは、Ollama、VS Code、GitHub Copilot Chat の対応バージョンが案内されています。うまく表示されない場合は、まず VS Code と Ollama を最新にしておくのがおすすめです。
1. Ollama を起動してモデルを用意する
まず Ollama が動いていることを確認します。
ollama list
まだモデルがない場合は、使いたいモデルを pull します。
ollama pull qwen3.6:latest
コーディング用途では、環境に余裕があれば coding 向けの大きめモデル、まず試すだけなら小さめのモデルから始めると扱いやすいです。
# 例: 環境にあるモデル名に合わせて変更してください
ollama pull qwen3.6:35b-a3b-coding-mxfp8
大きいモデルほど賢くなりやすい反面、メモリを多く使います。反応が遅い、途中で止まる、Mac のメモリプレッシャーが高い場合は、より小さいモデルに切り替えるのが現実的です。
2. VS Code のチャットからモデル選択を開く
VS Code の右側にある Chat ビューを開き、入力欄付近のモデル選択を開きます。
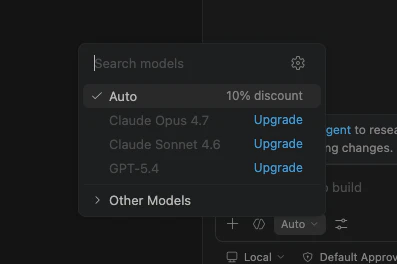
ここには、Copilot 側のクラウドモデルと、追加済みのローカルモデルが並びます。最初はローカルモデルが出てこないことがあるので、その場合は歯車マーク>Language Models 画面から Ollama を追加します。
3. Language Models 画面を開く
モデル選択メニューや歯車アイコンから、Language Models 画面を開きます。
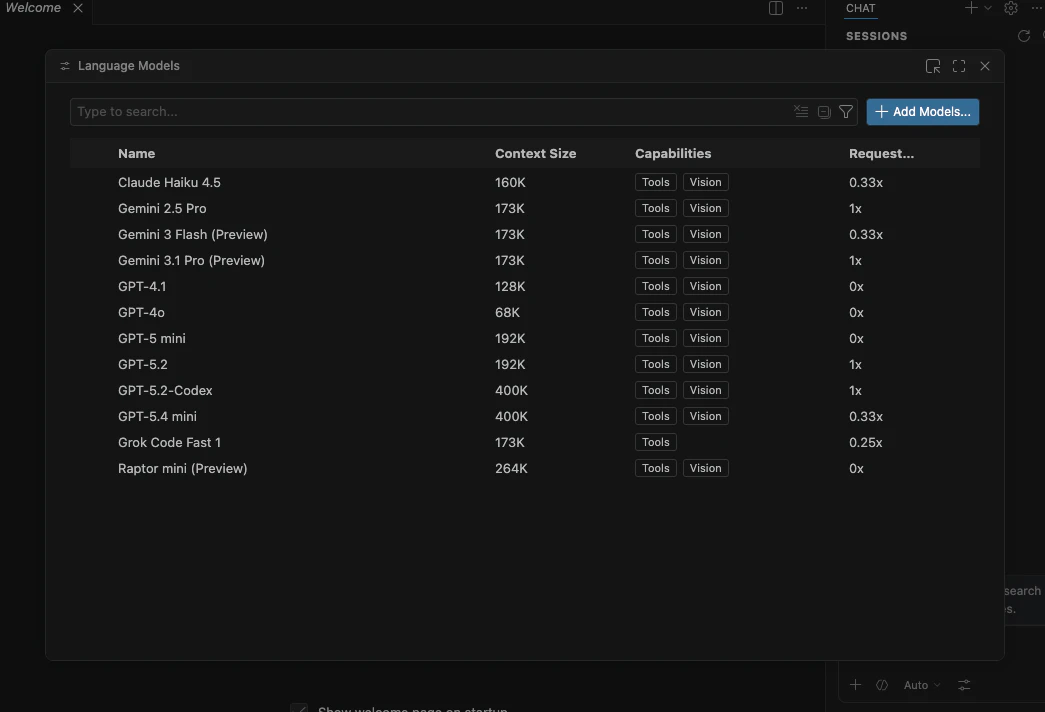
この画面では、利用できるモデル、コンテキストサイズ、Tools / Vision などの capability を確認できます。
AI コーディングで重要なのは Tools です。エージェントにファイル編集やコマンド実行のような道具を使わせたい場合、ツール呼び出しに対応したモデルを選ぶ必要があります。対応していないモデルは、通常のチャットには使えても、エージェント用途では選択肢に出ないことがあります。
4. Add Models から Ollama を追加する
右上の Add Models... を押し、プロバイダー一覧から Ollama を選びます。
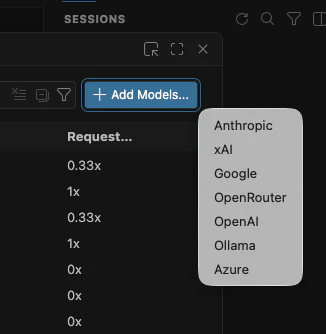
Ollama がローカルで起動していれば、Ollama に入っているモデルが VS Code 側に読み込まれます。
Ollama の標準ポートは localhost:11434 です。VS Code から見つからない場合は、先にターミナルで次を確認します。
curl http://localhost:11434/api/tags
レスポンスが返らない場合は、Ollama アプリを起動するか、環境によっては次のように起動します。
ollama serve
5. Ollama のモデルを表示対象にする
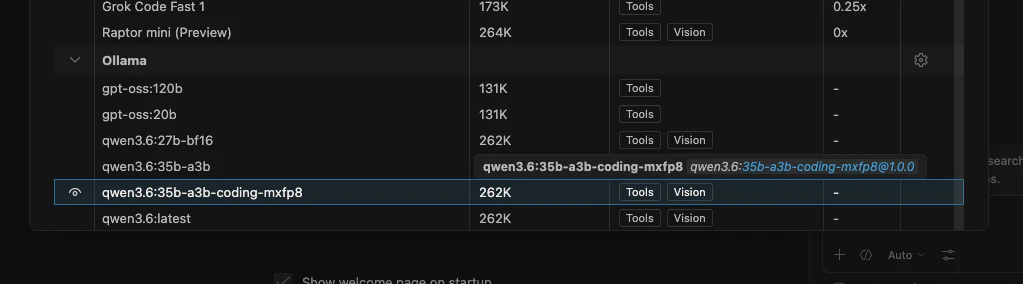
Ollama の行を展開すると、ローカルに入っているモデルが一覧に出ます。
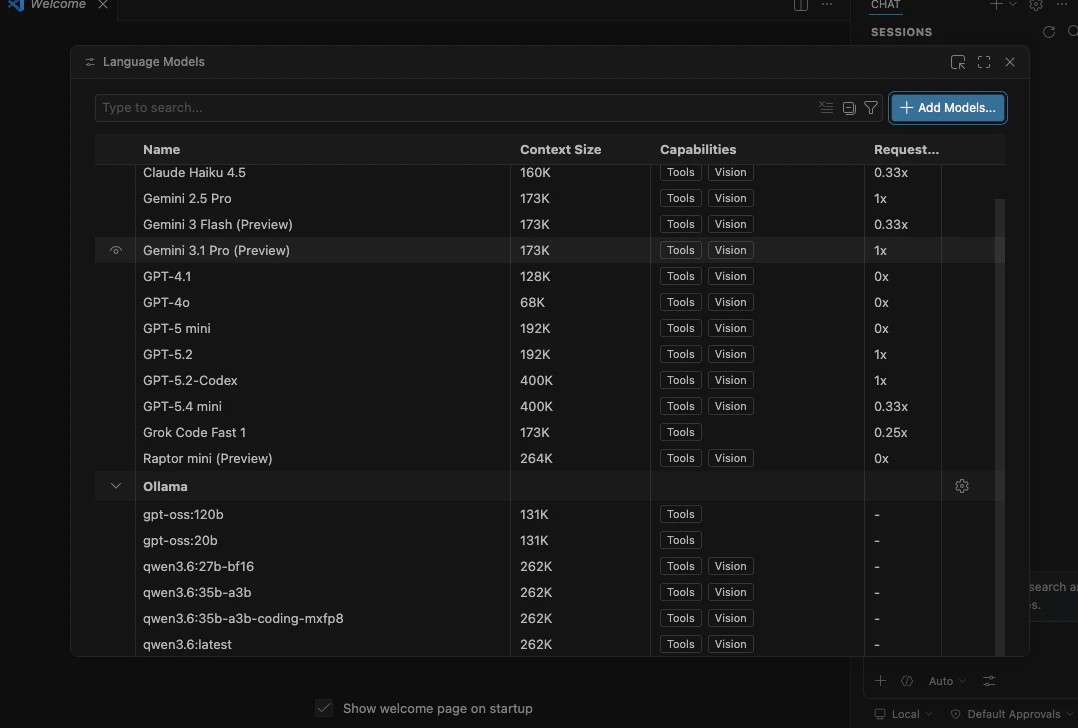
モデルの左側にある表示アイコンで、チャットのモデルピッカーに出すかどうかを切り替えられます。よく使うモデルだけ表示しておくと、モデル選択がかなり楽になります。
今回の例では、次のようなモデルが見えています。
gpt-oss:120bgpt-oss:20bqwen3.6:27b-bf16qwen3.6:35b-a3bqwen3.6:35b-a3b-coding-mxfp8qwen3.6:latest
6. コーディング用モデルを選ぶ
AI コーディングに使いたいモデルを表示対象にして、チャットのモデルピッカーから選択します。
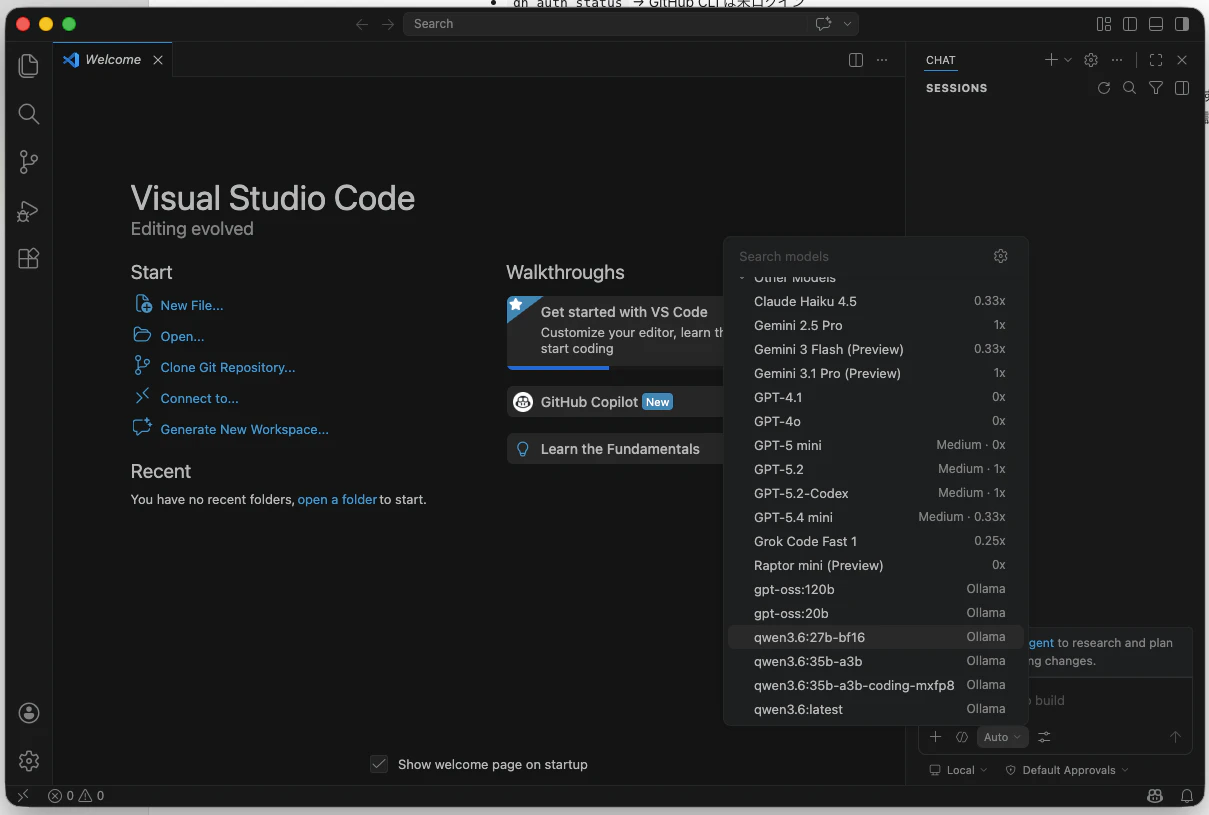
スクリーンショットでは qwen3.6:35b-a3b-coding-mxfp8 を選んでいます。coding と名前に入っているモデルは、コード生成・修正・説明に寄せて調整されていることが多く、まず試す候補にしやすいです。
7. Chat 側で Local を選ぶ
Chat ビュー下部で Local が選ばれていることを確認します。
ここまでできれば、VS Code のチャットからローカル LLM を使えます。
試しに、次のような小さめの依頼から始めると挙動を確認しやすいです。
このリポジトリのREADMEを読んで、開発環境のセットアップ手順を短くまとめてください。
この関数の責務を説明して、テストしやすくする改善案を3つ出してください。
このエラーの原因を調べて、修正案を提示してください。まだファイルは編集しないでください。
いきなり大きな実装を任せるより、まずは「説明」「調査」「小さな修正」から始めると、モデルの得意不得意がわかりやすいです。
クラウドモデルとローカルモデルの使い分け
自分の感覚では、次のように使い分けると快適でした。
| 用途 | 向いているモデル |
|---|---|
| 機密性の高いコードの相談 | ローカル LLM |
| ちょっとした説明・要約 | ローカル LLM |
| 小さなリファクタリング | ローカル LLM |
| 大規模な設計変更 | 高性能なクラウドモデル |
| 最新仕様の調査 | 検索や公式ドキュメントも併用 |
ローカル LLM は手元で動かせる安心感があります。ただし、モデルサイズやマシン性能に強く依存します。速度や精度が足りないときは、クラウドモデルと切り替えて使うのが実用的です。
うまくいかないときのチェック
Ollama のモデルが表示されない
まず Ollama 側でモデルが見えているか確認します。
ollama list
次に API が返るか確認します。
curl http://localhost:11434/api/tags
ここで返らなければ、VS Code ではなく Ollama 側の起動問題です。
モデルはあるのに Agent で選べない
モデルが tool calling に対応していない可能性があります。Language Models 画面で Tools capability が付いているか確認します。
反応が遅い
大きいモデルを選びすぎている可能性があります。まずは小さめのモデルで動作確認し、速度と精度のバランスを見てから大きいモデルに変えるのがおすすめです。
期待したコード修正にならない
ローカル LLM に限らず、AI コーディングではコンテキスト指定が重要です。
悪い例:
直して
良い例:
src/auth.ts の login 関数で、401 のときだけ再ログインを促すようにしたいです。
まず現在の処理を説明してから、最小変更で修正案を出してください。
対象ファイル、期待する挙動、変更範囲を明示すると、かなり安定します。
実験
テストでローカルLLMとクラウドLLMそれぞれに3D太陽系アプリを作ってもらいました。
Ollama-qwenで作成したアプリ(ローカルLLM)

Codex-GPT5.5で作成したアプリ(クラウドLLM)
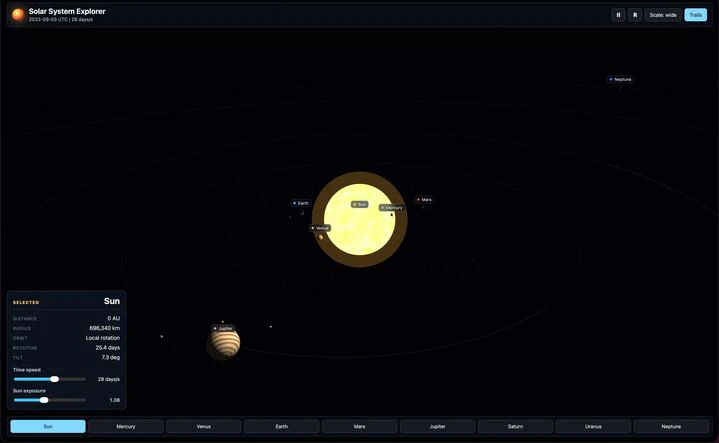
両者ともプロンプトを一回入れた後、修正なしの状態です。
惑星のテクスチャ表示などに差があり流石にクラウドLLMに勝てるとは言いにくいですが、
アニメーション・3D処理・選択した際に惑星詳細をインタラクティブ表示するなどローカルLLMもアプリ開発に十分な性能を発揮したと思います。
まとめ
VS Code の Language Models から Ollama を追加すると、ローカル LLM を VS Code の AI コーディングに組み込めます。
流れはシンプルです。
- Ollama を起動する
- 使いたいモデルを pull する
- VS Code の Language Models を開く
-
Add Models...から Ollama を追加する - 表示したいモデルを有効にする
- Chat のモデルピッカーでローカルモデルを選ぶ
ローカル LLM は、機密性の高いコード相談や軽めの調査にかなり便利です。一方で、重い設計変更や最新情報が必要な作業では、クラウドモデルや公式ドキュメントも併用すると安定します。
「全部ローカルにする」よりも、「ローカルで十分な作業はローカルへ寄せる」と考えると、日常の AI コーディングに取り入れやすいです。
参考
- Ollama Docs: VS Code
- Visual Studio Code Docs: AI language models in VS Code
- Visual Studio Code Docs: Local agents in Visual Studio Code
実験に用いたプロンプト
Build a browser-based solar system explorer that runs locally in a web browser and feels like a real interactive simulation rather than a toy demo. It should accurately represent the structure and motion of the solar system, with believable planetary sizes, orbital behavior, lighting, rotation, and spatial scale, while still remaining usable and visually clear. The experience should look realistic, polished, and aesthetically strong, with smooth navigation, intuitive zoom and camera movement, and a presentation that makes space feel vast and detailed. The final result must be fully functional, visually impressive, scientifically grounded, and directly runnable in the browser without requiring any backend or external services.