概要
個人的な備忘録を兼ねたPyTorchの基本的な解説とまとめです。BERTタイプのMLM事前学習に向けて学んだことをまとめおきたいと思います。Transformer Encoderタイプ(BERTタイプ)の事前学習で利用されるMLM (Masked Language Modeling) の方法を実装、事前学習してみるのがMLM事前学習編の目的となります。前回の事前学習の結果、<mask>部分もある程度予測できたので、モデルを利用して転移学習も行ってみたいと思います。
自作のモデルでのファインチューニング回となります。🔥
方針
- できるだけ同じコード進行
- できるだけ簡潔(細かい内容は割愛)
演習用のファイル
- トークナイザー: unigram_tokenizer_2k.json
- 語彙数2000のトークナイザー・tokenizerディレクトリー
- 事前学習モデル:unigram_2k.model
- 第31回で学習したモデル・modelディレクトリー
- 学習データ:history_text_label_id.jsonl
- 5クラスのテキスト分類・dataディレクトリー
- コード: sample_32.ipynb
1. BERTタイプモデルの転移学習
wikipediaから抽出した日本の歴史データを利用してBERTタイプ (Transformer Encoderタイプ) の事前学習を試みました。小さなモデルではありますが、テキスト分類問題に転移学習して、ささやかながらその効果を確認してみたいと思います。
- 転移学習してみる検証精度を確認
- 事前学習モデルを使わずに訓練、検証精度を確認
この2つを試して比較してみたいと思います。
利用するのは日本の歴史関係の文章を分類するというテキスト分類タスクとなります。wikipediaから抽出した文章から歴史の年代を予測する形になります。学習済みモデルを利用するので、トークナイザーやモデルの基本形は完成している状態から始まります。主な流れは次のようになります。
(1) 分類問題のテキストデータに対してtokenizerを使いID化
(2) 学習済みモデルのmlm_head部分を分類問題用に変更
(3) 一部のパラメータのみ再学習
2. コードと解説
基本的にテキスト分類なので今まで同様の流れとなります1。
- データの読み込みとtorchテンソルへの変換 (2.1)
- ネットワークモデルの定義と作成 (2.2)
- 誤差関数と誤差最小化の手法の選択 (2.3)
- 変数更新のループ (2.4)
- 検証 (2.5)
2.0 データについて
利用するデータについて簡単に紹介します。wikipediaの日本の歴史について書かれているページから情報を取得します。時代区分が弥生であれば、「https://ja.wikipedia.org/wiki/弥生時代」
から文章を取得します。1文1行データにして、「弥生」が含まれていない行のみ利用します。
1文1行を入力データ、時代区分をラベルとします。時代区分が記載されている文は除いています。たぶん、ヒントになるからね![]() 2
2
簡易的な演習なので、適当に5種類の時代を選択して、それぞれ200行(200個)のデータを集めました。これを利用して学習と検証を行ってみたいと思います。
データのサンプル
ラベルの番号と時代の並びが整合していない!のですが、分類問題なのでこのまま行います![]()
| text | label | 時代区分 |
|---|---|---|
| 田中は自ら外相を兼任し中国での革命の進展に対して強く干渉した。 | 0 | 昭和 |
| 倭国大乱がどのような争いであったのかは未だ具体的に解明されていないのが現状である。 | 1 | 弥生 |
| その後の島原の乱も鎮圧することで、平安時代以降、700年近く続いた政局不安は終焉を迎えた。 | 2 | 江戸 |
| 玄宗の治世前半は「開元の治」と称された。 | 3 | 奈良 |
| これを自身への反乱と誤認した後醍醐天皇は、尊氏討伐を決め、建武の乱が発生した。 | 4 | 室町 |
事前学習で利用したトークナイザーによって、text部分をトークナイズします。文頭に<bos>、文末に<eos>を挿入したID列を追加してデータセットを作成しました。
2.1 データの読み込みとtorchテンソルへの変換
ライブラリーの読み込み、精度の関数を定義、利用するトークナイザーを読み込みます。このあと、データの読み込みとなります。
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
from tokenizers import Tokenizer
from sklearn.model_selection import train_test_split
#デバイスの選択
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("利用デバイス:", device.type)
# 精度を計算する関数
def accuracy(y, t):
_, argmax_list = torch.max(y, dim=1)
accuracy = sum(argmax_list == t).item()/len(t)
return accuracy
# (1) 事前学習で保存したのモデル名
pre_trained_model = "model/unigram_2k.model"
# 保存したトークナイザーを読み込む
tokenizer_filename = "tokenizer/unigram_tokenizer_2k.json"
tokenizer = Tokenizer.from_file(tokenizer_filename)
説明メモ
- (1) 前回作成したモデルを指定します。
データの読み込み
データはJSONL形式、pandasを利用して読み込んでみました。
# (1) データファイルの読み込みJSONLファイルを読み込む
filename = "data/text_label_id.jsonl"
df = pd.read_json(filename, lines=True)
# (2) 系列長を等長にする
# x: IDベクトル
# t: ラベル
target_length = 64
df["ids"] = df["ids"].apply(lambda x: x + [0] * (target_length - len(x))) # 系列長が異なるので注意!64 になるように0で埋める
x = torch.LongTensor(df["ids"])
t = torch.LongTensor(df["label"])
# (3) 学習データと訓練データに分割
x, x_test, t, t_test = train_test_split(x,t, stratify=t, random_state=55)
x = x.to(device)
t = t.to(device)
x_test = x_test.to(device)
t_test = t_test.to(device)
説明メモ
- (1) pandasでjsonlを読み込むぞ😆
idsがID列、labelがラベルのキーとなります。 - (2) 最大系列長64トークンで学習しているので、64トークンに揃えます。文頭<bos>や文末<eos>のIDはすでにID列に付加されてあるので、<pad>を追加するだけになります。
applyを利用して、64トークンに揃えるように「0」で埋めていきます。実際は、xに[0]を必要な数追加するlambda関数で対応します。 - (3) train_test_splitを利用して、学習データと訓練データに分割します。
2.2 ネットワークモデルの定義と作成
今回は図1のように埋め込み層などから抽出された特徴量をTransformer Encoder層で関連度を考慮した特徴量に変換、文頭<bos>のみを利用して全結合層による5種類のクラス予測をする形をとります。
図1:モデル構造(分類ネットワーク)

図2の事前学習時のmlm_headを図1の全結合層へ付け替える形になります。実際のコードでもmlm_headブロックを分類のための全結合層に変更するだけです。黄色のTransformer Encoder ブロックの重みとして事前学習で学習した重みを使います。
図2:事前学習モデルと分類ネットワーク
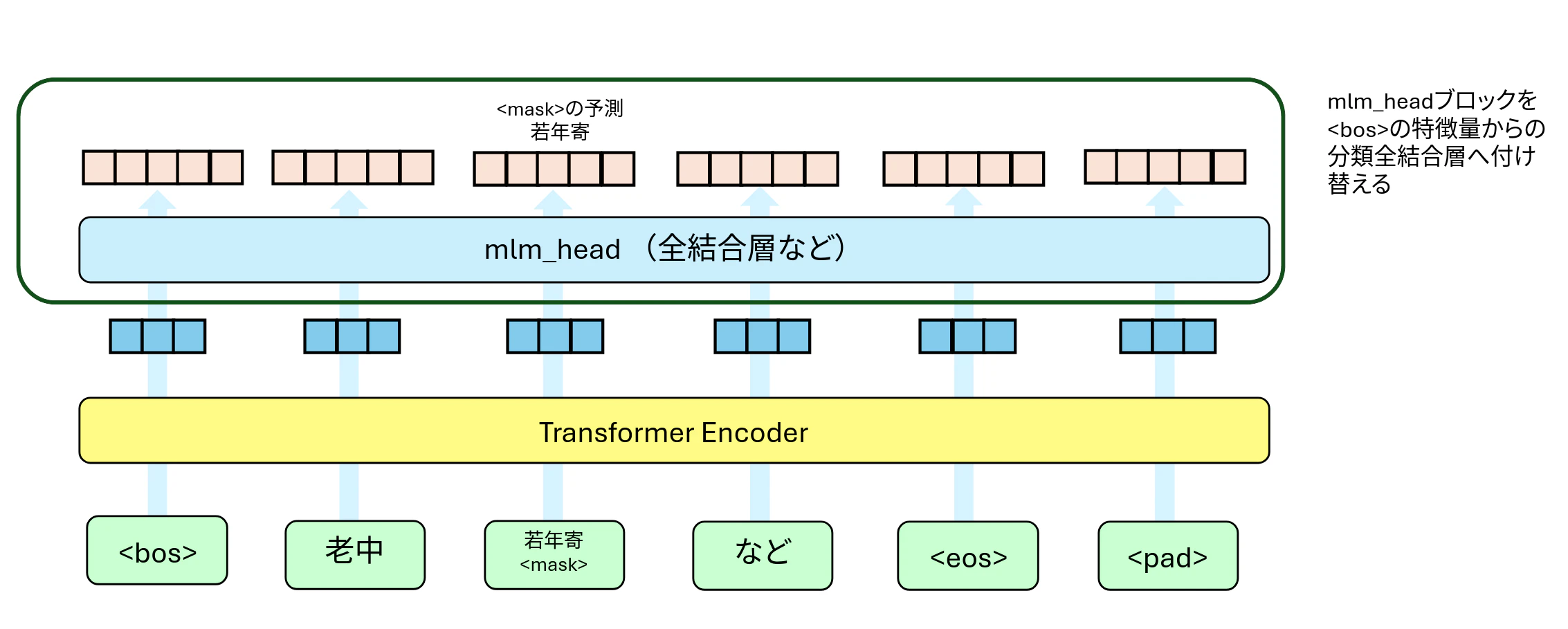
修正部分は大きく2点
- 事前学習時に用いたmlm_headブロックをテキスト分類用のLinearに変更
- テキスト分類用Linearへの入力には<bos>部分の特徴量を利用
# (1) モデル設定クラス
class ModelConfig:
def __init__(self, tokenizer):
# モデル構造
self.vocab_size = tokenizer.get_vocab_size()
self.d_model = 64
self.seq_len = 64
self.nhead = 4
self.dim_feedforward = 256
self.num_layers = 6
self.dropout = 0.1
self.out_features = 5
# 特殊トークンID
self.pad_token_id = tokenizer.token_to_id("<pad>")
self.mask_token_id = tokenizer.token_to_id("<mask>")
self.bos_token_id = tokenizer.token_to_id("<bos>")
self.eos_token_id = tokenizer.token_to_id("<eos>")
self.unk_token_id = tokenizer.token_to_id("<unk>")
# 特殊トークンのセット
self.special_tokens = {
self.pad_token_id,
self.mask_token_id,
self.bos_token_id,
self.eos_token_id,
self.unk_token_id,
}
# 通常トークンのリスト special_tokenを除くトークンのリスト(MLMランダム置換用)
self.normal_tokens = [
i for i in range(self.vocab_size)
if i not in self.special_tokens
]
# 学習設定 (今回は利用しないけど使うと便利かも)
self.batch_size = 512
self.learning_rate = 0.0001
self.num_epochs = 100
self.mask_prob = 0.15
self.max_grad_norm = 1.0
# (2) 文章分類のネットワーク
# 事前学習のネットワーク構造のmlm_headの部分を分類問題用に変更
class DNN(nn.Module):
def __init__(self, config: ModelConfig):
super().__init__()
self.config = config
# 埋め込み層
self.token_embedding = nn.Embedding(
num_embeddings=config.vocab_size,
embedding_dim=config.d_model,
padding_idx=config.pad_token_id
)
self.pos_embedding = nn.Embedding(num_embeddings=config.seq_len, embedding_dim=config.d_model)
self.layer_norm = nn.LayerNorm(config.d_model)
self.dropout = nn.Dropout(config.dropout)
# Transformer Encoder
encoder_layer = nn.TransformerEncoderLayer(
d_model=config.d_model,
nhead=config.nhead,
dim_feedforward=config.dim_feedforward,
dropout=config.dropout,
batch_first=True,
)
self.transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers=config.num_layers, enable_nested_tensor=False)
# MLM用の出力層:BERT風レイヤー 各トークン位置で語彙全体を予測
self.classifier = nn.Linear(in_features=config.d_model, out_features=config.out_features)
def forward(self, x):
# マスクの作成
src_key_padding_mask = (x == self.config.pad_token_id)
# 埋め込み
tok_emb = self.token_embedding(x)
pos_emb = self.pos_embedding(torch.arange(x.size(1), device=x.device))
x = tok_emb + pos_emb.unsqueeze(0)
x = self.layer_norm(x)
x = self.dropout(x)
# Transformer Encoder
h = self.transformer_encoder(x, src_key_padding_mask=src_key_padding_mask)
# ---- 文ベクトルへの Pooling <BOS>トークン(先頭)に情報を集約
pooled = h[:, 0, :] # [batch, d_model]
# ---- 分類 ----
y = self.classifier(pooled) # [batch, num_labels=5]
return y
# (3) 事前学習したモデルファイルを読み込む
checkpoint = torch.load(pre_trained_model, map_location=device)
config = ModelConfig(tokenizer)
config.__dict__.update(checkpoint["config"])
# (4)
model = DNN(config).to(device)
# (5) 事前学習重み(checkpoint側)をフィルタ
pretrained = checkpoint["model_state_dict"]
pretrained_filtered = {
k: v for k, v in pretrained.items()
if (not k.startswith("mlm_head."))
}
# (6) 必要な部分(事前学習モデルの一部分)の重みだけ必要なのでstrict=False にする。
info = model.load_state_dict(pretrained_filtered, strict=False)
print(f"削除されているか確認: {info.unexpected_keys}") # 何も表示されないはず
モデルの詳細は第22回 文章分類・Transformerを参照してください3。
説明メモ
- (1) ModelConfigクラスを利用して、モデル内部の数値をまとめています。
- (2) DNNは文章分類のネットワーク構造。事前学習モデルで利用したmlm_headブロックを分類用の全結合層に変更します。第22回同様、<bos>へ情報を集約して、<bos>の出力値を全結合層へ入力します。
- (3) 事前学習したモデルを読み込みます。(3)の段階ではModelConfigのみアップデートされます。
- (4) 読み込んだconfig情報を利用してDNNを作ります。この段階で事前学習のネットワーク構造が再現されます。
- (5) checkpoint["model_state_dict]で事前学習モデルの重みを取得します。mlm_headブロック以外の重みが必要な重みとなります。mlm_head関連のブロックを削除した pretrained_filtered を作成します。
- (6) retrained_filteredの重みを(4)で作成したmodelへコピーします。strict=Falseにすることで、(4)で作成したmodelのclassifier層 (事前学習のモデルには存在しない層) 以外に重みをコピーすることができます。
- (5)と(6)を省略してmodel.load_state_dict(pretrained, strict=False)でも動作します
 削除している層を明示的に示してみました
削除している層を明示的に示してみました
2.3 誤差関数と誤差最小化の手法の選択
転移学習のポイント!一部のパラメータだけ更新するように、更新パラメータを変更します。
params_to_update = []
# (1) 全部Falseにして更新不要にする
for name , param in model.named_parameters():
param.requires_grad = False
# (2) 更新するパラメータを追加
# 最終層とtransformer層一部を更新させてみた
for name, param in model.transformer_encoder.layers[-2:].named_parameters():
param.requires_grad = True
params_to_update.append(param)
print("更新されるパラメータ:", name)
for name, param in model.classifier.named_parameters():
param.requires_grad = True
params_to_update.append(param)
print("更新されるパラメータ:", name)
どこかの書籍に記載されていたコードの写経状態![]()
説明メモ
- (1) param.requires_grad=Falseで全部を更新不可にします。
- (2) 更新が必要な部分のみ、param.requires_grad=Trueとして、リストへ追加します。リストの追加を忘れても動作してしまうので注意が必要です。更新パラメータのリストは
params_to_updateという名称にしました。 - 追加するリストを複数準備すれば、リストごとに異なる学習率でパラメータを更新させることができます4。
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(params_to_update, lr=1e-3)
# optimizer = torch.optim.AdamW(model.parameters()) # これまでの書き方
これまでは全部のパラメータを更新したためmodel.parameters()と使ってきました。ファインチューニングなので先程作った一部の更新パラメータリスト (params_to_update) を使うことになります。
2.4 変数更新のループ
LOOPで指定した回数、
- y=model(x) で予測値を求め、
- criterion(y, t) で指定した誤差関数を使い予測値と教師データの誤差を計算、
- 誤差が小さくなるようにoptimizerに従い全結合層の重みとバイアスをアップデートします。
LOOP = 100
model.train()
for epoch in range(LOOP):
optimizer.zero_grad()
y = model(x)
loss = criterion(y, t)
acc = accuracy(y,t)
loss.backward()
optimizer.step()
if (epoch+1)%10==0:
print(f"{epoch}:\tloss:{loss.item():.3f}\tacc:{acc:.3f}")
「転移学習する時って学習回数が少なくていいはず!」なのですが、100回もループさせています。損失や精度、検証精度も改善し続けるのでつい回数を重ねてしまった。事前学習とは異なり順調に損失が減少していくと思いますj。
2.5 検証
2.1のデータ分割で作成したテストデータ x_test と t_test を利用して学習結果をテストしてみましょう。x_testをmodelに入れた値 y_test = model(x_test) が予測値となります。accuracyで平均精度を求めれば完成です。
model.eval()
with torch.inference_mode():
y_test = model(x_test)
acc = accuracy(y_test, t_test)
print(f"検証精度: {acc}")
# 検証精度: 0.816
- 学習時の精度は85〜90%くらいまで上昇
- 検証精度は、81%前後で落ち着くと思います
個別の精度
うまく表にできなかったのですが、列が予測したラベルです。例えば、正解ラベルが昭和(1行目)、江戸時代3個、奈良時代4個誤判定していると見てください。43/50=0.86 だけ正解しています。
| 予測 | |||||
|---|---|---|---|---|---|
| 昭和 | 弥生 | 江戸 | 奈良 | 室町 | |
| 昭和 | 43 | 0 | 3 | 4 | 0 |
| 弥生 | 2 | 41 | 1 | 4 | 2 |
| 江戸 | 7 | 0 | 36 | 5 | 2 |
| 奈良 | 2 | 3 | 5 | 38 | 2 |
| 室町 | 1 | 0 | 1 | 2 | 46 |
江戸時代が正解だけど、昭和と予測(7個)だったり、奈良時代が正解だけど、江戸と予測(5個)になっているようです。奈良時代はいろいろ誤判定しているように見えます。まあ適当に作成したデータセットなのでこんな感じでOKでしょう。
3. 事前学習モデルを使わないタイプと比較
同じモデル構造で事前学習の重みを使わず、学習データのみ利用した場合と比較してみたいと思います。コードの説明はパス![]()
モデル部分までコードも同じです。
# (1) モデルの設定
config = ModelConfig(tokenizer)
model = DNN(config).to(device)
# (2) パラメータは全部更新するので model.parameters() を使う
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=0.001)
# (3) 学習ループ:LOOPの回数は結構適当。損失と精度みて決める。
LOOP = 200
model.train()
for epoch in range(LOOP):
optimizer.zero_grad()
y = model(x)
loss = criterion(y, t)
acc = accuracy(y,t)
loss.backward()
optimizer.step()
if (epoch+1)%10==0:
print(f"{epoch}:\tloss:{loss.item():.3f}\tacc:{acc:.3f}")
# printの出力
# 9: loss:1.601 acc:0.243
# 19: loss:1.505 acc:0.329
# ~~~ 中略 ~~~
# 189: loss:0.017 acc:0.999
# 199: loss:0.008 acc:1.000
# (4) 検証
model.eval()
with torch.inference_mode():
y_test = model(x_test)
acc = accuracy(y_test, t_test)
print(f"検証精度: {acc}")
# 検証精度: 0.612
- 事前学習モデルの重みを使わない場合、60%前後でした。
- もちろん、検証用のデータも同じです😆
- モデルのパラメータも同一です。ここを変更すればタスクに合わせてもう少し精度向上を目指せるはずですが、それでは比較にならないのでNG
個別の精度
| 予測 | |||||
|---|---|---|---|---|---|
| 昭和 | 弥生 | 江戸 | 奈良 | 室町 | |
| 昭和 | 38 | 1 | 6 | 2 | 3 |
| 弥生 | 7 | 27 | 5 | 4 | 7 |
| 江戸 | 11 | 3 | 29 | 4 | 3 |
| 奈良 | 8 | 4 | 8 | 25 | 5 |
| 室町 | 5 | 1 | 9 | 1 | 34 |
比較してみた
- 転移学習:検証精度は80%
- 直接学習:検証精度は60%
どうやら自作の小さなモデルと小さなコーパスであっても事前学習の効果がみられるようです。ただし、事前学習に利用していない分野だと転移学習のメリットはまったくありませんよ![]()
次回
Datasetクラスのカスタマイズに挑戦してみたいと思います。クラスのカスタマイズってちょっと難しそう😆 Datasetクラスのカスタマイズは、MLM事前学習編からずれるのでMLM事前学習編はこれで終わり?!
目次ページ
注
-
1文だけでは時代区分の判定がほぼ不可能な一般的内容も内容も含まれています。品質の良いデータセットではありません。あくまで演習用の簡易データセットとなります
 ↩
↩ -
第22回とネットワーク構造は同一なのですが、unigramによるトークナイザー、事前学習などきっと理解の深さが違うはずと思いたい🌵 ↩
-
複数のリストにそれぞれ更新するパラメータを追加する形になります。次のような感じです。
# 更新するパラメータを入れるリスト encoder_params = [] classifier_params = [] # まず全部 freeze for name, param in model.named_parameters(): param.requires_grad = False # Transformer Encoder の最後2層だけ更新 for name, param in model.transformer_encoder.layers[-2:].named_parameters(): param.requires_grad = True encoder_params.append(param) print("更新されるEncoderパラメータ:", name) # 分類ヘッドを更新 for name, param in model.classifier.named_parameters(): param.requires_grad = True classifier_params.append(param) print("更新されるClassifierパラメータ:", name)optimizerを指定するときに、encoder_paramsとclassifier_paramsに分けて学習率を設定する形になります。長い注で
↩