概要
個人的な備忘録を兼ねたPyTorchの基本的な解説とまとめです。GTZANデータセットを利用しての音楽ジャンル分類の演習の2回目です。10ジャンル分類の演習を行いたいと思います。
GTZANデータセットは2025年8月時点だとリンク切れのようです。torchaudio.datasets.GTZANを利用してダウンロードできないので、Kaggleから直接ダウンロードするのが良いと思います。
Kaggle: GTZAN Dataset - Music Genre Classification
ちょっとだけ注意で、jazzジャンルのjazz.00054.wavがなぜか壊れています。Kaggleのdiscussionでも指摘されていました![]()
GTZAN音楽データを利用した10ジャンルの分類で最終的に次のような表になります。
図:個別の分類精度(10秒間隔・75%)
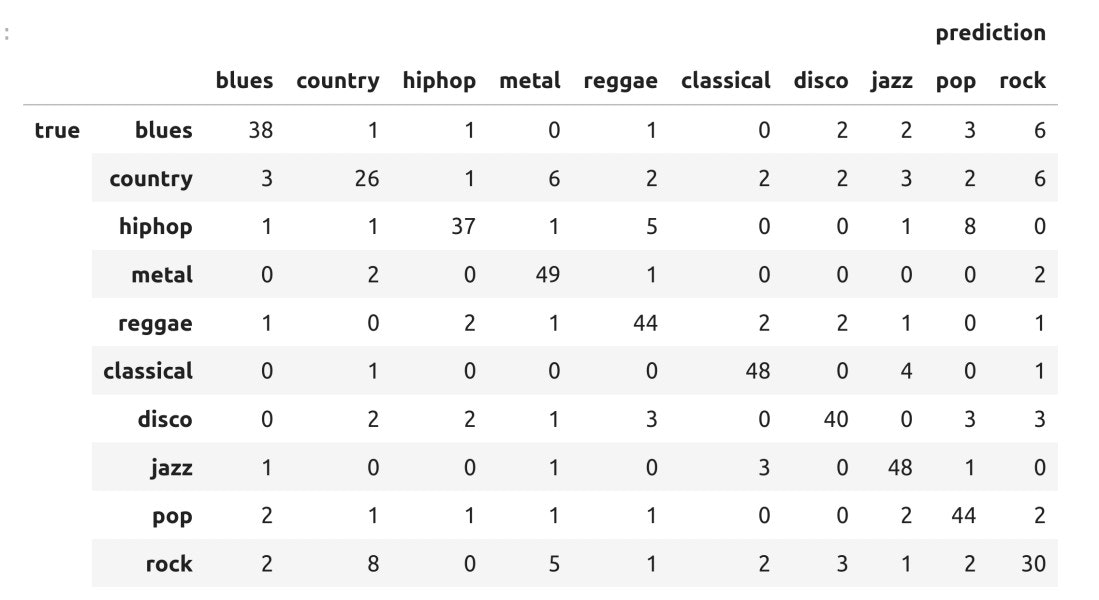
検証精度について(学習時間:20分〜1時間程度、パラメータの数値全部同一)
- 5秒間隔のデータ:75%前後(時々80%台は稀かも)
- 10秒間隔のデータ:75%前後(時々80%台は稀かも)
- 20秒間隔のデータ:70%前後(データ数が少なくなるので精度が下がります)
方針
- できるだけ同じコード進行
- できるだけ簡潔(細かい内容は割愛)
- 特徴量などの部分,あえて数値で記入(どのように変わるかがわかりやすい)
演習用のファイル
- データ:GTZANの音楽ジャンルデータ
- Kaggle: GTZAN Dataset - Music Genre Classificationからダウンロード
- コード:sample_14.ipynb
注意点
- 10ジャンルの合計900個のファイルを利用します
- 音楽データの入手とデータセット作成後でないとsample_14.ipynbは動作しないぞ〜

新しく加わる内容は、ミニバッチと呼ばれるアイディアです。これまで通り学習ループを実装すると、今回のデータセットでは入力するデータのサイズが大きすぎてメモリーエラーになる可能性があります。そこで登場するのがミニバッチ学習です。今回はミニバッチ学習に焦点を当てつつ音楽ジャンル分類を行ってみます🔥
変更点
- ミニバッチ学習
- PyTorchのDataLoaderとTensorDatasetを導入
音楽データから波形データを抽出する内容は第12.5回を参照してください。
1. 演習用のデータセット作成(準備)
GTZANのデータをダウンロードしてZIPを解凍すると、「blues, classical, country,...」と音楽ジャンルのディレクトリが10種類できるはずです。
事前に壊れているファイルのjazz.00054.wavを除いておきます。特に意味はないのですが、各ディレクトリ90個で演習用のデータセットを作ることにしました![]() コードの中核はファイルをlibrosaで読み込み、10秒ずつの長さに重複なしで分割するだけです。音楽ジャンルの分類になるのでラベルはジャンル名をID化しておきます。
コードの中核はファイルをlibrosaで読み込み、10秒ずつの長さに重複なしで分割するだけです。音楽ジャンルの分類になるのでラベルはジャンル名をID化しておきます。
データサイズについて
- 5秒で分割するタイプタイプ:1.4G
- 10秒で分割するタイプ: 1.4G
- 20秒で分割するタイプ: 1G
各ファイル30秒前後の長さなので20秒で分割するタイプだとファイル数個の学習用データとなります。10秒だと1ファイルにたいして、2〜3個作成されるはずです。5秒間隔はちょっと短い感じもします。もちろん、データの数が一番多いのは5秒間隔です。5秒間隔だとカーネルサイズを小さくしても問題ないので学習をやや高速にすることができます![]() 演習にはおすすめ?好みに応じて演習していきましょう
演習にはおすすめ?好みに応じて演習していきましょう![]() 1
1
import librosa
import numpy as np
import glob
from pathlib import Path
file_list = glob.glob("./audio/*/*.wav") # wavファイルを読み込むディレクトリ適宜変更してください
# ['./audio/classical/classical.00000.wav', ...,'./audio/jazz/jazz.00089.wav']
# 音楽ジャンルの辞書
genre_dic = {"blues":0, "country":1,"hiphop":2,"metal":3,"reggae":4,
"classical":5,"disco":6,"jazz":7,"pop":8,"rock":9}
labels = [genre_dic[Path(path).parent.name] for path in file_list]
#------------------------------------------------------------------------------
# サンプリングレート: 22050 # この値を変更しても精度が変わります
# 分割する時間:10秒
target_sr = 22050
sequence_sec = 10 # 列の長さ(秒)
sequence_length = target_sr * sequence_sec # 実際の系列長
data_list = [] # 等長音声データのリスト
label_list = [] # 対応するラベルのリスト
for num, filename in enumerate(file_list):
audio, sr = librosa.load(filename, sr=target_sr) # ファイル読み込み
divided_number = len(audio)//sequence_length # 何個に分割できるか?分割数
segments = [audio[i*sequence_length:(i+1)*sequence_length] for i in range(0,divided_number)]
data_list.extend(segments)
label_list.extend([labels[num] for _ in range(len(segments))])
x = np.array(data_list)
t = np.array(label_list)
# x.shape, (2691, 220500)
# t.shape, (2691,)
np.savez_compressed("train_data_10.npz", x=x, t=t)
コードのポイント
- audioディレクトリに10ジャンルの音源をそれぞれ90個ずつ用意しておきます
- 実際の系列長はサンプリングレート×秒数なので 22,050x10=220,500となります
- librosaで読み込んだ波形データを先頭から220,500個でスライスする部分が、
segments = [audio[i*sequence_length:(i+1)*sequence_length] for i in range(0,divided_number)]となります - 入力データと教師データ(ラベル)のnumpy配列を
train_data_10.npzとして保存しました
2.  音楽ジャンル分類のコードと解説♪
音楽ジャンル分類のコードと解説♪
ミニバッチの利用部分を除いては前回(第13回)とほぼ同一です。
PyTorchによるプログラムの流れを確認します。基本的に下記の5つの流れとなります。Juypyter Labなどで実際に入力しながら進めるのがオススメ
- データの読み込みとtorchテンソルへの変換 (2.1)
- ネットワークモデルの定義と作成 (2.2)
- 誤差関数と誤差最小化の手法の選択 (2.3)
- ミニバッチと変数更新のループ (2.4)
- 検証 (2.5)
2.1 データの読み込みとtorchテンソルへの変換
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset # ミニバッチの利用
from sklearn.model_selection import train_test_split
data = np.load("./train_data_10.npz")
x = data["x"]
t = data["t"]
# x.shape, (2691, 220500)
# t.shape, (2691,)
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"device: {device}")
# 入力データは FloatTensor
# 入力データの形状を(バッチサイズ、チャンネル、系列長)
# 教師データはラベルなので LongTensor
X = torch.FloatTensor(x).to(device).view(x.shape[0], 1, x.shape[1])
T = torch.LongTensor(t).to(device)
x_train, x_test, t_train, t_test = train_test_split(X, T, test_size=0.2, stratify=t, random_state=55)
コードのポイント
- conv1dを利用するので、入力データの形状を(バッチサイズ、1チャンネル、系列長)に変換します
- train_test_splitで分割するオプションの
stratify=tを利用して「データセットにおけるラベルの割合を、分割後の学習データとテストデータでも反映させる」ようにします
2.2 ネットワークモデルの定義と作成
ネットワークを定義する部分です。PyTorchのネットワークの記述方法の一つnn.Sequentialを使い、音声データから特徴量を抽出するネットワーク構造と、特徴量からジャンル分類するネットワーク構造に分けて記述します。10秒間隔だとカーネルサイズをもう少し大きくするとか、ブロックをもう一つ追加するほうが良いと思います。精度よりも動作と構造ということで前回と同じ3ブロックにしました。ただ、カーネルサイズだけ500から1000にと変更しました。効果の程は![]()
![]()
![]()
class DNN(nn.Module):
def __init__(self):
super().__init__()
self.features = nn.Sequential(
# 第1ブロック
nn.Conv1d(1, 64, kernel_size=1000, stride=16),
nn.BatchNorm1d(64),
nn.ReLU(),
nn.MaxPool1d(kernel_size=4, stride=2),
# 第2ブロック
nn.Conv1d(64, 128, kernel_size=500, stride=8),
nn.BatchNorm1d(128),
nn.ReLU(),
nn.MaxPool1d(kernel_size=4, stride=2),
# 第3ブロック
nn.Conv1d(128, 256, kernel_size=16, stride=4),
nn.BatchNorm1d(256),
nn.ReLU(),
nn.AdaptiveAvgPool1d(8) # 固定サイズの出力
)
self.classifier = nn.Sequential(
nn.Flatten(),
nn.Linear(in_features=256 * 8, out_features=512),
nn.BatchNorm1d(num_features=512),
nn.ReLU(),
nn.Dropout(p=0.3),
nn.Linear(in_features=512, out_features=128),
nn.BatchNorm1d(num_features=128),
nn.ReLU(),
nn.Dropout(p=0.3),
nn.Linear(in_features=128, out_features=10)
)
def forward(self, x):
h = self.features(x)
y = self.classifier(h)
return y
model = DNN()
model.to(device)
コードのポイント
-
nn.Sequentialを利用してネットワーク層を波形データから特徴量を抽出するfeaturesと、特徴量から分類に落とし込むclassifierの2種類に分けて記述します - forward部分は、まとめたネットワークをそのまま記述します
- 第1ブロックConv1dの入力チャンネルは、波形データそのものなのでin_channels=1となります
- カーネルサイズは、1000、500、16と徐々に小さくしています。この数値を変更すると精度や学習速度も変わってきます。500の次が16で極端に小さくなっているので、このあたりにもうひとブロック追加したほうがいいのかな?
- 第3ブロックのAdaptiveAvgPool1dは、出力サイズを固定できる便利なプーリング層です。
nn.AdaptiveAvgPool1d(output_size=8)で出力サイズは、(バッチサイズ、チャンネル数、8)に固定されます - classifierブロックは、Linearと活性化関数を利用して最終的に10分類にすればOKです
今回はmodelの構造表示についても凝ってみました![]()
torchinfo ライブラリの summary() 利用することで、モデル構造と入出力の形状などの情報を取得することができます。使い方はsummaryの引数に入力するデータの形状(バッチサイズ、チャンネル数、系列長)を指定します。バッチサイズの部分は1で問題ありません。必要に応じてtorchinfoライブラリをインストールしてください。
from torchinfo import summary
summary(model, (1,1,220500)) # (バッチサイズ, チャンネル数, 系列長)
summary(model, (1,1,220500)) の出力結果
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
DNN [1, 10] --
├─Sequential: 1-1 [1, 256, 8] --
│ └─Conv1d: 2-1 [1, 64, 13719] 64,064
│ └─BatchNorm1d: 2-2 [1, 64, 13719] 128
│ └─ReLU: 2-3 [1, 64, 13719] --
│ └─MaxPool1d: 2-4 [1, 64, 6858] --
│ └─Conv1d: 2-5 [1, 128, 795] 4,096,128
│ └─BatchNorm1d: 2-6 [1, 128, 795] 256
│ └─ReLU: 2-7 [1, 128, 795] --
│ └─MaxPool1d: 2-8 [1, 128, 396] --
│ └─Conv1d: 2-9 [1, 256, 96] 524,544
│ └─BatchNorm1d: 2-10 [1, 256, 96] 512
│ └─ReLU: 2-11 [1, 256, 96] --
│ └─AdaptiveAvgPool1d: 2-12 [1, 256, 8] --
├─Sequential: 1-2 [1, 10] --
│ └─Flatten: 2-13 [1, 2048] --
│ └─Linear: 2-14 [1, 512] 1,049,088
│ └─BatchNorm1d: 2-15 [1, 512] 1,024
│ └─ReLU: 2-16 [1, 512] --
│ └─Dropout: 2-17 [1, 512] --
│ └─Linear: 2-18 [1, 128] 65,664
│ └─BatchNorm1d: 2-19 [1, 128] 256
│ └─ReLU: 2-20 [1, 128] --
│ └─Dropout: 2-21 [1, 128] --
│ └─Linear: 2-22 [1, 10] 1,290
==========================================================================================
Total params: 5,802,954
Trainable params: 5,802,954
Non-trainable params: 0
Total mult-adds (G): 4.19
==========================================================================================
Input size (MB): 0.88
Forward/backward pass size (MB): 16.08
Params size (MB): 23.21
Estimated Total Size (MB): 40.17
==========================================================================================~~~
output shapeや Params sizeなども表示されるので事前に保存されるモデルサイズもわかるのが便利?
## 2.3 誤差関数と誤差最小化の手法の選択
分類問題なので、損失関数は、クロスエントロピー損失となります。
~~~python: 損失関数と手法
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=0.0005)
2.4 ミニバッチと変数更新のループ(変更箇所)
これまでの学習ループは、for文の中でy=model(x_train)という形で入力データx_trainを一度に学習させてから、変数の更新を行っていました。この方法はフルバッチ学習と呼ばれますが、x_trainのデータ量が多いと、y=model(x_train)を計算するときに、メモリーエラーになることがあります。この問題を回避する一つの方法がミニバッチ (minibatch) 学習です。
for epoch in range(LOOP):
model.train()
optimizer.zero_grad()
y = model(x_train)
loss = criterion(y, t_train)
acc = accuracy(y, t_train)
loss.backward()
optimizer.step()
print(f"{epoch}: loss: {loss.item()},\tacc:{acc}")
ミニバッチ学習は、学習データを小さな塊(ミニバッチ)に分割して順次処理する手法です。これにより、メモリ使用量を削減できます。
具体例での理解
例えば、100個のデータを持つx_trainを50個で2つに分割すると、例えば次のようなミニバッチになります2。
- ミニバッチ1:x_train[0:49]
- ミニバッチ2:x_train[50:99]
各ミニバッチごとに以下の処理(1〜4)を実行します。
- 順伝播: y_batch = model(x_batch)
- 損失計算:loss = criterion(y_batch, y_true_batch)
- 逆伝播:loss.backward()
- パラメータ更新:optimizer.step()
全てのミニバッチの処理が完了すると、1エポックが終了となります。x_train[0:49]〜x_train[50:99]までのすべてのミニバッチ学習が終わって、学習ループが1回終了することになります。
PyTorchでの実装ではDataLoaderとTensorDatasetを利用すると簡単です。ミニバッチ作成の手順は2行です。train_loaderの要素がミニバッチごとのデータと教師データとなります。
train_data = TensorDataset(x_train, t_train)
train_loader = DataLoader(train_data, batch_size=100, shuffle=True)
for epoch in range(LOOP)の中に、for x, t in train_loaderというミニバッチ毎の学習ループを記述することになります。
from torch.utils.data import DataLoader, TensorDataset # ミニバッチの利用
︙ # train_test_splitの部分から
x_train, x_test, t_train, t_test = train_test_split(X, T, test_size=0.2, stratify=t, random_state=55)
# ミニバッチに区分けする
# DataLoaderで自動的にミニバッチに分割できる
train_data = TensorDataset(x_train, t_train)
train_loader = DataLoader(train_data, batch_size=100, shuffle=True)
for epoch in range(LOOP):
for x, t in train_loader:
# 各ミニバッチで学習処理
y = model(x)
loss = criterion(y, t)
acc = accuracy(y, t)
optimizer.zero_grad()
loss.backward()
optimizer.step()
ミニバッチ学習の最後に、損失や精度の計算についてです。train_loaderのループで求まるlossとaccはミニバッチでの損失と精度になります。
- ミニバッチ毎の損失と精度
- データ全体での損失と精度
データ全体の損失や精度を求めるには、ミニバッチごとの損失と精度を足し合わせて、割り算すれば良さそうです。
要注意
単純に損失や精度を足し合わせて、分割された数で割り算して平均を求める方法は若干注意が必要で、不正確になる恐れがあります。数値例で確認してみます。
数値例
- データ数: 1050個
- ミニバッチサイズ: 各100個
データをミニバッチに分割すると...
10個のミニバッチ(100個)+ 1個のミニバッチ(50個) の11個に分割される
仮にバッチ1から10の精度が90%(100個)、バッチ11の精度が80% (50個)とします。
- 不正確な平均: (90×10 + 80×1) ÷ 11 = 89.09%
- 正確な平均: (90×100×10 + 80×50) ÷ 1050 = 89.52%
正しい平均は?みたいな数学クイズにありそうな問題ですが![]() 分割されたミニバッチのデータ数がすべて等しい場合は、単純な計算方法でOKです。正確に平均値を計算する場合は、若干面倒ですがしっかりと掛け算、その後全体で割り算して正しい平均値を求めてください。torchmetricsライブラリを使う方法もあります。
分割されたミニバッチのデータ数がすべて等しい場合は、単純な計算方法でOKです。正確に平均値を計算する場合は、若干面倒ですがしっかりと掛け算、その後全体で割り算して正しい平均値を求めてください。torchmetricsライブラリを使う方法もあります。
ちょっとした手抜き技です。DataLoaderのオプションでdrop_last=Trueを指定しておけば、ミニバッチのサイズが異なる最後の部分を学習から削除することが可能です。shuffle=Trueなので、毎回シャッフルされるので特定のデータが永続的に除外されるということもありません!この2種類のオプションを指定しておけば単純な平均計算でも正確に計算できますね![]() できるだけ簡単にということで、sample_14.ipynbではこの方法を使っています
できるだけ簡単にということで、sample_14.ipynbではこの方法を使っています![]()
DataLoaderのオプション
- shuffle: エポック毎にミニバッチの中身をシャッフルする(デフォルト値:False)
- drop_last: 均等分割になっていない場合ミニバッチの最後を削除(デフォルト値:False)
注意点なども踏まえた学習ループの部分の最終的なコードは次のようになります。
︙ # train_test_splitの部分から
x_train, x_test, t_train, t_test = train_test_split(X, T, test_size=0.2, stratify=t, random_state=55)
# ミニバッチに分割
# drop_last=True : 最後のミニバッチを削除
train_data = TensorDataset(x_train, t_train)
train_loader = DataLoader(train_data, batch_size=100, shuffle=True, drop_last=True)
# 精度計算の関数
def accuracy(y, t):
_,argmax_list = torch.max(y, dim=1)
accuracy = sum(argmax_list == t).item()/len(t)
return accuracy
LOOP = 100
model.train()
for epoch in range(LOOP):
# ミニバッチの処理
total_loss = 0 # 損失の累計を計算
total_acc = 0 # 精度の累計を計算
cnt = 0 # ミニバッチでの繰り返し回数 cntで割れば平均になる?(注意)
for x, t in train_loader:
y = model(x)
loss = criterion(y, t)
acc = accuracy(y, t)
# 損失と精度を素朴に足し算 あとで割り算
total_loss += loss.item()
total_acc += acc
cnt += 1
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 平均損失と平均精度(簡便な方法)
if (epoch+1)%20 == 0:
print(f"{epoch}: loss: {total_loss/cnt},\tacc:{total_acc/cnt}")
2.5 検証
テスト用データを使って検証してみます。学習結果ごとに検証の精度は、集めてくるデータや学習回数などで毎回異なりますが、概ね0.75前後。
model.eval()
with torch.inference_mode():
y_test = model(x_test)
test_acc = accuracy(y_test, t_test)
# test_acc 0.75
ついでに個別の精度も確認してみました。流石に7割台だとまんべんなく間違えているよね![]()
![]()
![]()
図:個別の分類精度(10秒間隔・75%)
3. 次回
1次元畳み込みは、時系列的な意味でいうと過去・現在・未来の情報から特徴量を抽出しています。未来の情報を利用せずに畳み込む技(?)が因果畳み込みです。次回は因果畳み込み (Causal Convolution Network) を簡単にまとめておきたいと思います。
目次ページ