概要
個人的な備忘録を兼ねたPyTorchの基本的な解説とまとめです。1次元畳み込みで利用できる音楽データの作成方法について簡単にまとめておきます。データの前処理編になります。
PyTorchのConv1Dは時系列データの解析にも利用されており、気温データ(20.5°C, 21.2°C, 19.8°C...)や売上データ(1000円, 1200円, 950円...)といった数値データであれば、そのまま入力として使用できることは直観的にわかります。一方、音声・音楽データも時系列データの一種ではあるのですが、音声ファイル(WAV、MP3等)から具体的にどのような数値を抽出し、Conv1Dの入力形式に変換するかについては、なかなか、難しそうな印象があります。
この記事では、librosaライブラリを用いて音楽ファイルから時系列の振幅データを読み込み、PyTorchのConv1Dで処理可能な数値配列にするまでの簡単な方法を紹介します。
演習用のファイル
- データ:「私、暮井慧 よろしくね」:kei_01.wavとして利用
- データ:「ちょ、ちょっと あわてない、あわてない 落ちついて見直して」:kei_02.wavとして利用
- コード:sample_12_5.ipynb
演習の音声データはプロ生のキャラクター「 プロ生ちゃん(暮井 慧)(CV: 上坂すみれ様)」の音声を利用させていただきました ![]() m(_ _)m
m(_ _)m ![]()
基本ライブラリ
Pythonを利用して音声処理を行います。
利用するライブラリ
pip install librosa
librosaは音楽ファイルを読み込んで、様々なことができる素晴らしいライブラリなのですが、今回は本当に音楽ファイルを読み込むことしか利用していません![]()
詳しい内容は、公式サイトのドキュメントを参照してください。
1. 基本用語
デジタル音楽・音声処理の分野は用語が難しくてなかなか馴染みにくい?!自分だけかもしれませんが![]() とりあえず、次の3種類があれば大丈夫かな?
とりあえず、次の3種類があれば大丈夫かな?
- Hz
- サンプリングレート
- 振幅
Hz(ヘルツ)
Hzは周波数の単位で、1秒間に何回振動するかを表現します。音声処理では主に「1秒間に何回音のデータを記録するか」を示すために使用されます。例えば、10Hzは1秒間に10回、音のデータを取得することを意味します📡
サンプリングレート
アナログ音声信号をデジタルデータに変換する際の、1秒間あたりのサンプル数(データの記録回数)を示します。単位はHzです。CDの音質の44100Hzが代表的な値です。サンプリングレートが高いほど、1秒間によりたくさんの音のデータを集めているという意味で、より細かい音の変化を捉えていることになります。
振幅
音声波形の振動の大きさを表す値です。音は空気の振動で、押される方向(プラス)と引かれる方向(マイナス)があるため、振幅もプラスとマイナスの値を取ります。振幅の絶対値が大きいほど音が大きく、0に近いほど音が小さくなります。
2. wavファイルからデータセットへ
wavファイルを読み込んで、ニューラルネットワークの学習に利用できるデータへ加工していきます。生の音データそのものを利用する予定なので、フーリエ変換などは登場しません。音の仕組みやスペクトル分解については、この記事(スペクトル、スペクトログラムって何だろう?)が図解入りでとても丁寧です。
2.1 ファイルの読み込み
wavファイルを読み込むにはlibrosaライブラリのlibrosa.loadを使います。
基本パターン
audio, sr = librosa.load(ファイル名, サンプリングレート)
- audio : 音声データ(振幅値をサンプリングレート個並べたもの)
- sr : 読み込んだ音声ファイルのサンプリングレート
サンプリングレート (sr) が1秒間での音データの記録回数で、audioの長さが実際に取得した(サンプルした)値です。len(audio)/srが再生時間になります。引数のサンプリングレートを指定しない場合、読み込んだ音声ファイルのサンプリングレートが適用され、サンプリングレートを指定すると、指定値でファイルが読み込まれます。
import librosa # 音楽ファイルを読み込むときに利用
import numpy as np
import matplotlib.pyplot as plt # 音楽ファイルの出力値をグラフ化するときに利用
import japanize_matplotlib # matplotlibの日本語対応化
filename = "kei_data/kei_01.wav"
audio, sr = librosa.load(filename, sr=None)
print(f"音声データの形状: {audio.shape}")
print(f"サンプリングレート: {sr} Hz")
print(f"再生時間: {len(audio)/sr:.2f} 秒")
print(f"データ型: {audio.dtype}")
print(f"値の範囲: {audio.min():.3f} ~ {audio.max():.3f}")
# 音声データの形状: (130065,)
# サンプリングレート: 44100 Hz
# 再生時間: 2.95 秒
# データ型: float32
# 値の範囲: -0.966 ~ 0.966
コードのポイント
- audio: 音声データ(numpy配列)。librosaだと −1〜1 で正規化されているぞ

- sr: サンプリングレート(Hz)
- librosa.load( ): 指定したサンプリングレートでファイルを読み込む
- sr=None: ファイル名の音源データのサンプリングレートとなる
2.2 グラフで描画
librosaの出力値 audio は、正規化されているけど振幅の値を並べたものです。これらの値を順番に線で結んでグラフにしてみたいと思います。いわゆる、音声波形です。基本的に、matplotlibで、audioをplotすればOKです。
plt.figure(figsize=(12, 2))
time = np.linspace(0, len(audio)/sr, len(audio))
plt.plot(time, audio)
plt.xlabel('時間 (秒)')
plt.ylabel('振幅')
plt.title('音声波形')
plt.show()
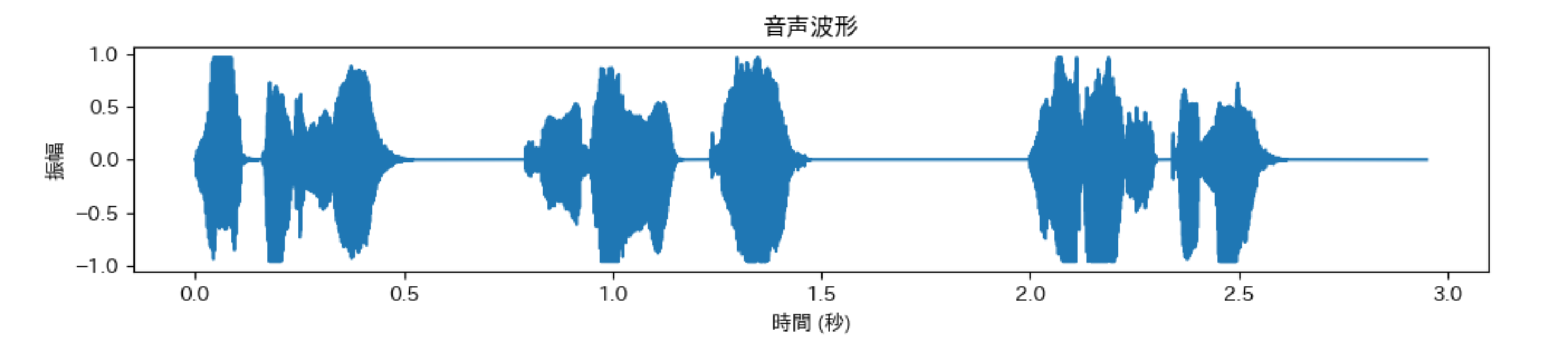
音楽や動画編集するアプリで見るような波形のグラフ(音声波形)になります。librosa.loadの出力値のaudioを音声波形データと呼んでおきます。ちなみに、縦軸の表示名については、色々議論?があるっぽい。奥村先生のブログで紹介されていました。
2.3 サンプリングレート
librosa.loadのサンプリングレートを指定するオプション sr を変更して、取得されるデータを観察してみましょう。
サンプリングレートが10:sr=10の場合
filename = "kei_data/kei_01.wav"
test_audio, test_sr = librosa.load(filename, sr=10)
print(f"音声データの形状: {test_audio.shape}")
print(f"サンプリングレート: {test_sr} Hz")
print(f"再生時間: {len(test_audio)/test_sr:.2f} 秒")
# 音声データの形状: (30,)
# サンプリングレート: 10 Hz
# 再生時間: 3.00 秒
サンプリングレートが10なので「1秒間に10回」音データを取得してます。音声ファイルの再生時間は3秒なので、サンプルされるデータ数は30個になります。
plt.figure(figsize=(12, 2))
time = np.linspace(0, len(test_audio)/test_sr, len(test_audio))
plt.plot(time, test_audio,linestyle="dotted" ,marker=".")
plt.axhline(y=0, color='gray', linestyle='-')
plt.xlabel('時間 (秒)')
plt.ylabel('振幅')
plt.title('音声波形')
plt.show()
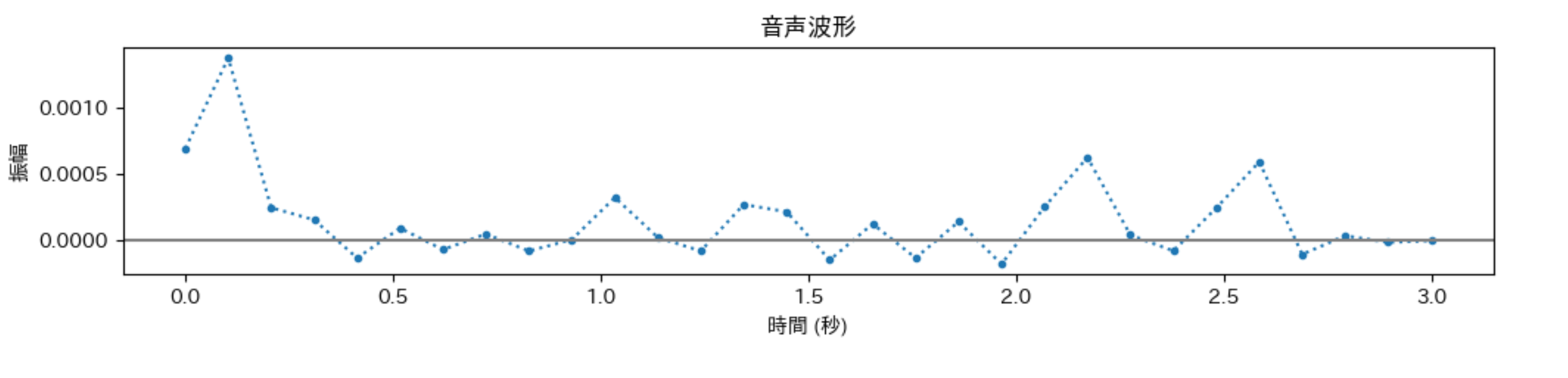
音声波形というよりも、気温や株価、販売数量などの時系列データの動きのように見えます。この音声波形のデータそのものを入力データとして使う予定です。
2.4 音声波形の再生
音声波形ということは、再生できるはず!Jupyter Notebook形式だと次のようなコードでlibrosaで読み込んだ振幅データ(音声波形)を再生することができます。
from IPython.display import Audio
Audio(audio, rate=sr)
Audioの引数にあるaudioやsrは、librosa.load()の出力値を使ってください。
先程サンプリングレートを10で読み込んだtest_audio, test_sr = librosa.load(filename, sr=10)ですが、サンプリングレートの値を大きくしていくと、声になっていくと思います。sr=2000くらいだと声として聞こえました。
3. 学習用データの準備
音声波形データは、音声ファイルごとに長さ(サイズ)が異なります。機械学習で利用でしやすいように、同じ長さで分割して学習用のデータを作成していきます。ちょうど株価データを窓サイズで分割していくイメージに近いです。
filename = "kei_data/kei_02.wav"
audio, sr = librosa.load(filename, sr=22050)
audio.shape
# (130759,)
audio (kei_02.wav) の再生時間は約6秒で、130,759個の数値から構成されています。10,000個ずつに分けるというアイディアでもよいのですが、今回は、秒単位で分割してみたいと思います。サンプリングレートは1秒間に記録するデータの回数だったので、サンプリングレートに取得したい秒数を掛け算すれば、実際に必要なデータの数がわかります。サンプリングレート22050Hzで3秒の長さだと
$$
22,050\times 3 = 66,150個
$$
となります。audioは130,759個の長さなので、3秒だと2分割にはわずかに足りない![]() 2秒で順番に分割していきます。
2秒で順番に分割していきます。
import numpy as np
import librosa
target_sr = 22050 # サンプリングレート(Hz)
sequence_sec = 2 # 系列長(秒)
sequence_length = target_sr*sequence_sec # 実際の系列長 44100(個)
# ファイル読み込み
audio, sr = librosa.load("kei_data/kei_02.wav", sr=target_sr)
divided_number = len(audio)//sequence_length # 分割できる個数・分割数
data_list = [audio[i*sequence_length:(i+1)*sequence_length] for i in range(0,divided_number)]
x = np.array(data_list)
x.shape
#
# (2, 44100)
コードのポイント
サンプリングレートが22050Hzで2秒なので、実際の系列長はsequence_length = target_sr*sequence_secとなります。sequence_length個(44,100個)でlen(audio)個(130,759個)を先頭から区分けすることになります。44,100個のデータが2種類作成されていることがわかります。3個目は44,100個未満なので今回は利用しない方針です。
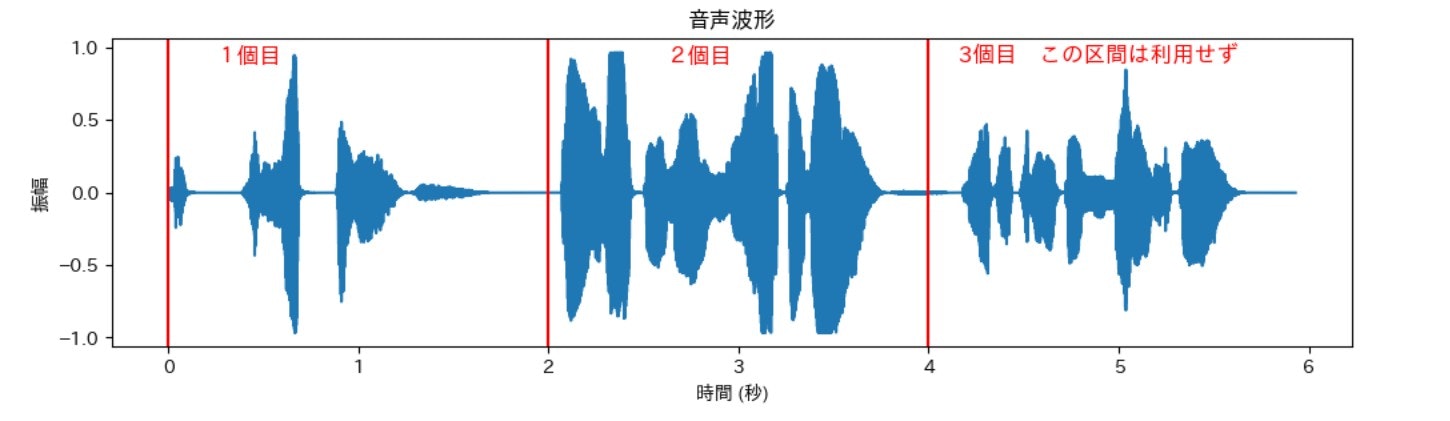
3個目の部分ですが、「不足分を0でパディングする」、「最後尾から前に向かって44,100個あつめる」、「不足分は最後尾から音を反転させる」...などいくつか方法があるようです。一長一短あるみたいです。
重複がない方法で、44,100個のデータが2種類作成されました。この時系列に並んだ44,100個をニューラルネットワークの入力データとして使っていく予定です。
重複のある分割
最後に、重複を許すタイプの分割を簡単に紹介しておきます。図とコードは1秒間重複しつつ3秒毎に分割するタイプとなります。分割される数については前回の内容・第12回を参照してください。
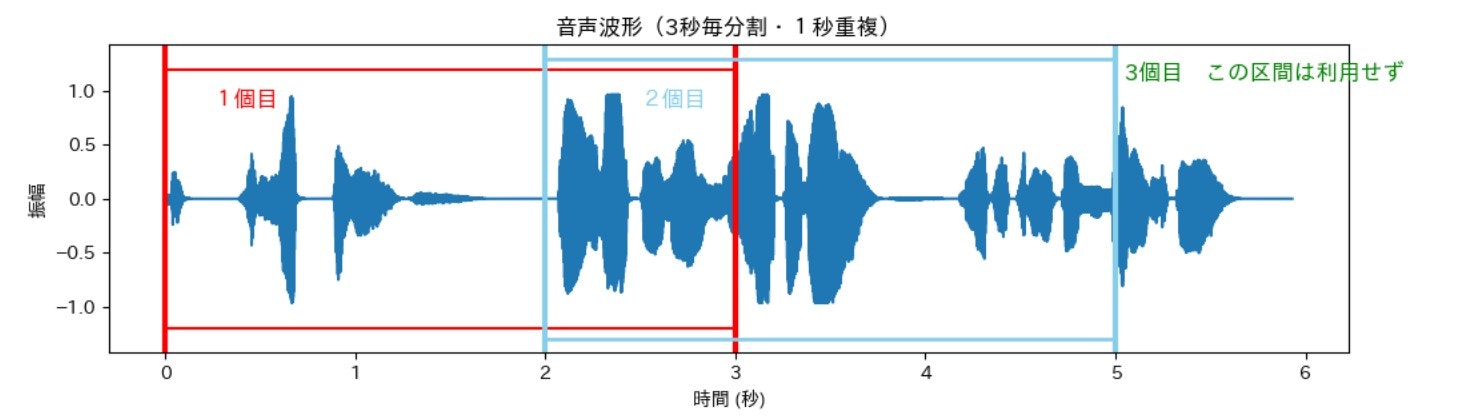
コードは、窓サイズ66,150個を右へ2秒移動させる形となります。図の赤い枠から水色の枠へ変わる形です。
target_sr = 22050
sequence_sec = 3 # 列の長さ(秒)
window_size = target_sr * sequence_sec # 実際の系列長(窓サイズ)
overlap_sec = 1 # 重複の秒数
overlap = target_sr * overlap_sec # 実際に重複する長さ
stride = window_size - overlap
audio, sr = librosa.load("kei_data/kei_02.wav", sr=target_sr)
divided_number = ((len(audio)-window_size)//stride) +1 # 分割数
data_list = [audio[i*stride:i*stride+window_size] for i in range(divided_number)]
x = np.array(data_list)
print(f"系列長:{window_size}")
print(f"再生時間:{sequence_sec}秒")
print(f"xの形状:{x.shape}")
#
# 系列長:66150
# 再生時間:3秒
# xの形状:(2, 66150)
コードのポイント
-
分割される数:
((len(audio)-window_size)//stride) +1 -
len(audio)-window_size:1個目のデータを除いた残りの部分のサイズ (64,609個) -
((len(audio)-window_size)//stride):残りのサイズをstride=44,100個(2秒)で何個埋められるか?
最後に、((len(audio)-window_size)//stride)+1のように、1個目を足し算すれば分割される数になります。
重複を利用する方法で、時系列に並んだ66,150個のデータが2種類作成されました。重複させることでデータを若干増やすことが可能となります![]()
次回
- GTZANの音楽ジャンル分類用のデータセットを利用して、音楽ジャンル分類を行ってみたいと思います

目次ページ