概要
映画のレビューや評価値をPythonのBeautifulSoupライブラリを利用して取得する方法を紹介します.推薦システムを練習するためのデータ収集やレビューと評価値の分析の練習に利用できると思います.最終的に,下図のような表形式のデータセットの取得が目的となります.

【紹介項目】
- 映画.comを利用して対象となる映画のユーザーレビューや評価値を取得する方法
利用するライブラリのインストール
pip install beautifulsoup4
pip install requests
pip install lxml
BeautifuSoupの基本的な使い方は解説しません.公式のサイトや様々な解説ページ,スクレイピングの書籍を参考にしてください.
1. Webページのデータを取得
オードリーの永遠の名作である「ローマの休日」を具体例としてユーザーレビューや評価値を抽出していきます.
最初に,スクレイピングしたいWebページの情報を取得してみます.html解析に,lxmlを利用しました.User-AgentとURLを適切に設定して,requestsとBeautifulSoupを使いURLの情報を読みこみます.
import requests
from bs4 import BeautifulSoup
url = "https://eiga.com/movie/50969/review/" # ローマの休日
headers = {"User-Agent": "Mozilla/5.0"}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, "lxml")
soupを表示すると,Webブラウザーでページのソースを表示させたときと同様,1行の長いテキストになります.
<!DOCTYPE html> <html lang="ja"> <head> <meta http-equiv="x-ua-compatible" content="ie=edge"/>
わかりにくいので,コードを整形してくれるエディターか,オンラインのHTML Formatterを利用して見た目を綺麗にしてみます.
<!DOCTYPE html>
<html lang="ja">
<head>
<meta content="ie=edge" http-equiv="x-ua-compatible" />
<meta content="width=1060" name="viewport" />
<meta charset="utf-8" />
<title>ローマの休日のレビュー・感想・評価 - 映画.com</title>
<meta content="ローマの休日の映画レビュー・感想・評価一覧。映画レビュー全191件。評価4.4。みんなの映画を見た感想・評価を投稿。" name="description" />
<meta content="ローマの休日,レビュー,感想,評価,映画" name="keywords" />
<meta content="summary" name="twitter:card" />
<meta content="@eigacom" name="twitter:site" />
<meta content="ja_JP" property="og:locale" />
<meta content="ローマの休日のレビュー・感想・評価 - 映画.com" property="og:title" />
~~~ 中略 ~~~
<script src="//www.googleadservices.com/pagead/conversion.js"></script> <noscript> <div style="display:inline;"> <img alt="" src="//googleads.g.doubleclick.net/pagead/viewthroughconversion/833009905/?guid=ON&script=0" style="width:1px;height:1px;border:0 none;"/>
</div></noscript>
</body>
</html>
この長いテキストファイルを眺めて,必要な情報の特徴や抽出の条件を見つけ出します.
2. 必要な部分を抽出
2.1 情報の確認
Webページから,分析に利用したい情報を探します.

四角で囲われている部分が基本的な情報です.リンクなども含めて9種類に注目しました.
【基本情報】
- ユーザー名
- ユーザーID:アイコンや名前に紐付いている番号で画像では非表示
- 評価値
- 日付
- 投稿手段
- レビューのタイトル
- レビューのURL:レビュータイトルに紐づくURLで画像では非表示
- レビュー
- 鑑賞方法
この記事では,次の4種類を取得してみたいと思います.ユーザー名は同一なのですが,ユーザーIDが異なる状況があったので,ユーザーIDを使います.
【抽出情報】
- ユーザーID:アイコンや名前に紐付いている番号
- 評価値
- レビューのタイトル
- レビュー
2.2 HTMLの確認
取得したHTMLのテキストを眺めて,必要な情報がどのような形で配置されているのかを判断します.少し長めですが,2人分を掲載しました.
...前略...
<div class="user-review pro" data-review-user="498613">
<div class="user-review-inner">
<h2 class="review-title"> <span class="rating-star val45">4.5</span><a href="/movie/50969/review/02316391/">最後に語られる"フレンドシップ(友情)"の深い意味</a> </h2>
<div class="review-data">
<div class="user"> <a class="user-name" href="/user/498613/" rel="nofollow">清藤秀人</a><span class="user-name-title">さん</span> <a class="follow-btn hidden" data-google-interstitial="false" data-method="post" data-remote="true" href="/user/498613/follow/" rel="nofollow">フォロー</a> </div>
<div class="time">2020年4月26日</div>
<div class="post-device">PCから投稿</div>
<div class="watch-methods">鑑賞方法:CS/BS/ケーブル</div>
<div class="edit"> <a href="/movie/50969/review/form/" rel="nofollow">編集</a> </div>
</div>
<div class="pulldown violation-report margin-top24" data-review-user="498613"> <label class="icon more"> <input type="checkbox"/> <ul> <li><span class="icon flag"></span><a href="/help/contact/?report_target=2316391&report_type=eiga_review">このレビューを報告する</a></li> </ul> </label> </div>
<div class="txt-block">
<p class="short">ヨーロッパ歴訪の過密スケジュールに辟易した某国王女アンが、...</p>
</div>
<div class="review-reaction">
<div class="comment"> <a class="icon fukidashi" data-google-interstitial="false" data-remote="true" href="/movie/50969/review/02316391/comment/" rel="nofollow">コメントする</a> <span>(<strong>1</strong>件)</span> </div>
<div class="empathy"> <a class="icon heart" data-google-interstitial="false" data-method="post" data-remote="true" href="/movie/50969/review/02316391/vote/" id="review_2316391_vote" rel="nofollow">共感した!</a> <span>(<strong id="review_2316391_votecnt">19</strong>件)</span> </div>
</div>
<div class="review-bookmarks">
<ul class="bookmarks">
<li> <a class="twitter-share-button twitter-share-button-rendered twitter-tweet-button" data-count="horizontal" data-counturl="https://eiga.com/movie/50969/review/02316391/" data-lang="ja" data-text="清藤秀人さんの映画「ローマの休日」レビュー(感想・評価)をシェア ☆4.5 #映画" data-url="https://eiga.com/movie/50969/review/02316391/" href="https://twitter.com/share" rel="nofollow">Xでつぶやく</a> </li>
<li class="facebook"><a href="http://www.facebook.com/share.php?u=https%3A%2F%2Feiga.com%2Fmovie%2F50969%2Freview%2F02316391%2F" rel="nofollow" target="_blank">シェア</a></li>
</ul>
</div>
</div>
<div class="review-user">
<a href="/user/498613/" rel="nofollow"><img alt="清藤秀人" class="img-circle" height="68" loading="lazy" src="https://eiga.k-img.com/dbimages/profile/498613/photo_1475737154.jpg" width="68" /></a>
</div>
</div>
<div class="user-review" data-review-user="927905">
<div class="user-review-inner">
<h2 class="review-title"> <span class="rating-star val45">4.5</span><a href="/movie/50969/review/03736125/">名作と呼ばれるに相応しい!!</a> </h2>
<div class="review-data">
<div class="user"> <a class="user-name" href="/user/927905/" rel="nofollow">とも</a><span class="user-name-title">さん</span> <a class="follow-btn hidden" data-google-interstitial="false" data-method="post" data-remote="true" href="/user/927905/follow/" rel="nofollow">フォロー</a> </div>
<div class="time">2024年4月20日</div>
<div class="post-device">iPhoneアプリから投稿</div>
<div class="watch-methods">鑑賞方法:VOD</div>
<div class="edit"> <a href="/movie/50969/review/form/" rel="nofollow">編集</a> </div>
</div>
<div class="pulldown violation-report margin-top24" data-review-user="927905"> <label class="icon more"> <input type="checkbox"/> <ul> <li><span class="icon flag"></span><a href="/help/contact/?report_target=3736125&report_type=eiga_review">このレビューを報告する</a></li> </ul> </label> </div>
<div class="txt-block">
<p class="short">初っ端の、「thank you♡」と一人一人にご挨拶をするシーンで...</p>
</div>
<div class="review-reaction">
<div class="comment"> <a class="icon fukidashi" data-google-interstitial="false" data-remote="true" href="/movie/50969/review/03736125/comment/" rel="nofollow">コメントする</a> <span>(0件)</span> </div>
<div class="empathy"> <a class="icon heart" data-google-interstitial="false" data-method="post" data-remote="true" href="/movie/50969/review/03736125/vote/" id="review_3736125_vote" rel="nofollow">共感した!</a> <span>(<strong id="review_3736125_votecnt">2</strong>件)</span> </div>
</div>
<div class="review-bookmarks">
<ul class="bookmarks">
<li> <a class="twitter-share-button twitter-share-button-rendered twitter-tweet-button" data-count="horizontal" data-counturl="https://eiga.com/movie/50969/review/03736125/" data-lang="ja" data-text="ともさんの映画「ローマの休日」レビュー(感想・評価)をシェア ☆4.5 #映画" data-url="https://eiga.com/movie/50969/review/03736125/" href="https://twitter.com/share" rel="nofollow">Xでつぶやく</a> </li>
<li class="facebook"><a href="http://www.facebook.com/share.php?u=https%3A%2F%2Feiga.com%2Fmovie%2F50969%2Freview%2F03736125%2F" rel="nofollow" target="_blank">シェア</a></li>
</ul>
</div>
</div>
<div class="review-user">
<a href="/user/927905/" rel="nofollow"><img alt="とも" class="img-circle" height="68" loading="lazy" src="https://eiga.k-img.com/gid/img/user/22609/798fde25131b05d7/160.jpg?1665368911" width="68" /></a>
</div>
</div>
<div class="user-review" data-review-user="927905">
<div class="user-review-inner">
...後略...
<div class="user-review"...>がレビューの分割点になっていることがわかります.classには,user-reviewとuser-review proがあるようです.proはプロのレビューワーという意味なのでしょうか?user-review proには,空白があるので,user-reviewでうまく特徴を捕まえられそうです.
おおまかな方針は次の2点になります.
- <div class="user-review"...>で始まるまとまりを,順番に取得する.
- それぞれについて,ユーザーID,評価値などの部分を探す.
1番目については,divタグ,class属性の値がuser-reviewで探して,リストにすれば良いので,
review_elements = soup.find_all('div', class_='user-review')
と記述できます.
2番目については,取得したリストの要素各々について,タグや属性を利用して抽出対象を探していきます.以下では,review_elementsリストの代表的要素をreview_elementと表記します.
ユーザーID
ユーザーIDの部分は,HTMLの確認で見てわかるように,
<div class="user-review" data-review-user="111などのユーザーID">
という形をしています.ユーザーIDは,data-review-userの値であることがわかります.review_elementのdata-review-userの値なので,
user_id = review_element['data-review-user']
によって値を取得できます.[ ]を利用して値を知ることができます.
評価値
評価値を表す部分は,
<span class="rating-star val45">4.5</span>
となっています.評価値は,spanタグ,class属性の値がrating-starのテキスト部分に相当することがわかります.review_elementの中身をspan, rating-starで探して,テキスト部分を抽出すれば良いので,
rating_element = review_element.find('span', class_='rating-star')
rating = rating_element.text
と書くことができます.1行目のfindで検索,2行目の.textでテキスト部分の抽出を表しています.
レビューのタイトル
レビュータイトルを表す部分は,若干面倒になります.
<h2 class="review-title">
<span class="rating-star val45">4.5</span>
<a href="/movie/50969/review/03736125/">名作と呼ばれるに相応しい!!</a>
</h2>
レビューのタイトルは,h2タグ,class属性の値がreview-titleとなるテキスト部分に相当することがわかります.しかし,テキスト部分をすべて抽出すると,評価値も合わせて抽出されるので,数値部分を取り除く作業が必要となります.他の方法としては,h2タグ,review-titleの部分を探した後に,<a href="/movie/50969/review/03736125/">名作と呼ばれるに相応しい!!</a> を利用して,テキスト部分のみを抽出しても良さそうです.評価値をすでに,ratingとして抽出してあるので,これを利用して,数値部分を削除する方法で試したものが下記となります.
title_element = review_element.find('h2', class_='review-title')
title = title_element.text.replace(rating, '').strip()
レビュー
いよいよ本題?で重要な部分です.レビュー本体は,
<p class="short">ヨーロッパ歴訪の過密スケジュールに辟易した某国王女アンが、...</p>
という形をしています.レビューは,pタグ,class属性の値がshortのテキスト部分に相当することがわかります.
pタグ,short属性でテキスト部分を抽出すれば良いので,
review_text_element = review_element.find('p', class_='short')
review = review_text_element.text.strip()
と書くことができます.
レビュー(ネタバレレビューの扱い)
レビュー本文について,ネタバレの扱いだとWebページ上表示されないようになっています.ネタバレ内容を含むレビューは,pタグ,class属性の値がhiddenとして表記されています.
hidden_review_text_element = review_element.find('p', class_='hidden')
review = hidden_review_text_element.text.strip()
としてレビューを取得することができます.
2.3 プログラム
これまでの一連の流れをまとめると,次のようなコードとなります.評価値やレビュー,レビュータイトルが存在しないこともあるので,その場合は,Noneとなるように調整しています.time.sleepで小休止も追加しました.appendの部分をprintに変更すれば,取得しているデータを表示させることができます.
import requests
from bs4 import BeautifulSoup
import time
url = "https://eiga.com/movie/50969/review/" # ローマの休日
headers = {"User-Agent": "Mozilla/5.0"}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, "lxml")
# 全てのレビュー要素を取得する
# review_elementsはリストになる
review_elements = soup.find_all('div', class_='user-review')
# 空のリストを用意
# このリストに取得した値を追加していきます
user_ids = [] # ユーザーID
ratings = [] # 評価値
titles = [] # レビューのタイトル
reviews = [] # レビュー
# 各レビューの情報を取得する
for review_element in review_elements:
# ユーザーID
user_id = review_element['data-review-user']
# 評価の数値を取得する
rating_element = review_element.find('span', class_='rating-star')
rating = rating_element.text if rating_element else None
# レビュータイトルを取得する
title_element = review_element.find('h2', class_='review-title')
title = title_element.text.replace(rating, '').strip() if title_element else None
# レビュー本文を取得する
review_text_element = review_element.find('p', class_='short')
# ネタバレを含むレビューを入れる場合
hidden_review_text_element = review_element.find('p', class_='hidden')
if review_text_element:
review = review_text_element.text.strip()
elif hidden_review_text_element:
review = hidden_review_text_element.text.strip()
else:
review = None
# 取得した情報をリストに追加
user_ids.append(user_id)
ratings.append(rating)
titles.append(title)
reviews.append(review)
time.sleep(1)
3. 次のページへ
レビューの件数が多いと,下図のように1ページには収まりきらず次のページが発生します.
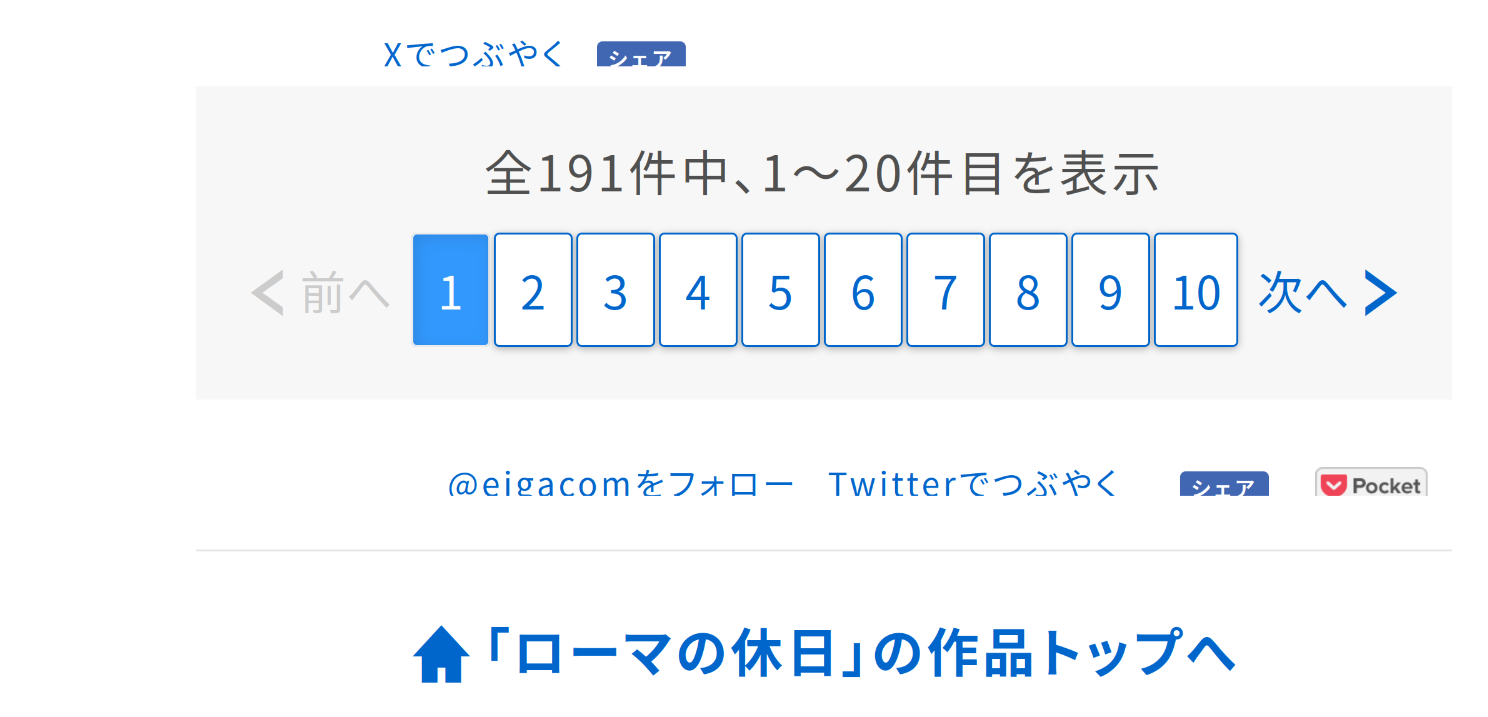
力技で次のページのURLを探し出して,スクレイピングしてもよいのですが,今回は実際に次のページをクリックしてURLの特徴に注目して手動でしのぎます1.
2ページ目以降は,/all/ページ番号/という形を追加するという規則になっていることがわかります2.全てのページについて,2.3のプログラムを動かすことで評価値やレビューの一覧を取得できることがわかります.1ページ最大20件のレビューが掲載されているので,全レビュー件数を20で割り算してページ数を求め,URLのリストを事前に作成してしまいます.全レビュー数が191件で各ページ20件のレビューなので,10ページまでレビューのページが作られます.本質的な内容からそれるので,今回は手動でリストを作成しましょう![]()
base_url = "https://eiga.com/movie/50969/review/" # ローマの休日"
url_list = [base_url]
# /all/2 から/all/10 までを追記
for i in range(2, 11):
url_list.append(base_url+"all/"+str(i))
このような形で,url_listに取得したいレビューのページのリストを作成しておきます.
4. CSVファイルで保存
pandasのデータフレームに変換後,CSVファイルとして保存します.一旦,2.3のプログラムに戻ります.取得した情報をリストへ追加していく作業まで終わりました.リストをpandasのデータフレームに変換して,CSVファイルとして保存すれば作業は終わりとなります.
# 取得した情報をリストに追加
user_ids.append(user_id)
ratings.append(rating)
titles.append(title)
reviews.append(review)
time.sleep(1)
#----ここから新しい内容----
# リストをPandasのDataFrameに変換
df = pd.DataFrame({
'user_id' : user_ids,
'rating': ratings,
'title': titles,
'review': reviews
})
# csvファイルとして保存
df.to_csv("RomanHoliday.csv", index=False)
保存したCSVファイルを表示させたものが次の図となります.次の図はjupyter labでCSVファイルを開いた状態です.
5. プログラム全体
最後に2.3のプログラムに,次のページ,CSVファイル保存を追加したプログラムを掲載して終わりにします.
import requests
from bs4 import BeautifulSoup
import time
import pandas as pd
filename = "./RomanHoliday.csv" # 保存するCSVファイル名
base_url = "https://eiga.com/movie/50969/review/" # ローマの休日
url_list = [base_url]
headers = {"User-Agent": "Mozilla/5.0"}
# 次のページのURL
# /all/2 から/all/10 までを追記
for i in range(2, 11):
url_list.append(base_url+"all/"+str(i))
# 空のリストを用意
user_ids = [] # ユーザーID
ratings = [] # 評価値
titles = [] # レビューのタイトル
reviews = [] # レビュー
# 各URLについてレビューなどを取得
for url in url_list:
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, "lxml")
# 全てのレビュー要素を取得する
review_elements = soup.find_all('div', class_='user-review')
# 各レビューの情報を取得する
for review_element in review_elements:
# ユーザーID
user_id = review_element['data-review-user']
# 評価の数値を取得する
rating_element = review_element.find('span', class_='rating-star')
rating = rating_element.text if rating_element else None
# レビュータイトルを取得する
title_element = review_element.find('h2', class_='review-title')
title = title_element.text.replace(rating, '').strip() if title_element else None
# レビュー本文を取得する
review_text_element = review_element.find('p', class_='short')
hidden_review_text_element = review_element.find('p', class_='hidden') # ネタバレを含むレビューを入れる場合
if review_text_element:
review = review_text_element.text.strip()
elif hidden_review_text_element:
review = hidden_review_text_element.text.strip()
else:
review = None
# 取得した情報をリストに追加
user_ids.append(user_id)
ratings.append(rating)
titles.append(title)
reviews.append(review)
print(f"{url}まで終了")
time.sleep(2)
#---------------------------------------------------------------------
# csvファイルとして保存
# リストをPandasのDataFrameに変換
df = pd.DataFrame({
'user_id' : user_ids,
'rating': ratings,
'title': titles,
'review': reviews,
})
df.to_csv(filename, index=False)
その他
スマートフォンのアプリレビューを取得する記事を紹介したことがあるので,拙稿ですが参考にしていていただけると幸いです(硬すぎ).