1. はじめに|「削る」前に「判断する」という選択
クラウドコスト最適化というと、「ログを減らす」「メトリクス保持期間を短くする」といった New Relic 自体のコスト削減 に目が向きがちだ。
もちろんそれも重要だが、アーキテクトの視点で見れば、真に削減すべきコスト(本丸) は別にある。
それは、「拡張すべきでないタイミングで拡張してしまう」クラウドリソースの費用だ。
システムが遅いと感じた時、アラートが鳴った時、「念のため」という言葉が出た瞬間。
その判断が積み重なることで、AWS / GCP の請求額は 静かに、しかし確実に 膨れ上がっていく。
本記事では、New Relic を単なる「監視ツール」ではなく、
「投資判断を支える意思決定基盤」 として再定義し、
「根拠をもって拡張を断るための判断体系」 を提示する。
2. 背景|なぜコストは「合理的に」増え続けるのか
EC サイトや業務システムの運用現場では、次のような光景が日常的に発生する。
- アクセス増に備えて、事前にスケールアウトする
- 遅延が疑わしいので、とりあえずインスタンスタイプを上げる
- 障害が怖いので、繁忙期が過ぎても設定を戻さない
これらは 「可用性を守る」という意味では合理的(正義) だ。
しかし、「因果関係の検証」 が欠落している点において、コスト戦略としては致命的である。
「見えない無駄」の正体
クラウドコストの高騰は、劇的な障害やトラフィック爆増だけで起きるのではない。
「判断のたびに積み上げられた過剰な安全マージン」 が、いつの間にか標準構成として定着することで発生する。
特に Magento のような複雑な構成(App + DB + Redis + Search)では、
直感だけで真のボトルネックを特定することはほぼ不可能 だ。
「重い」と感じる → 「サーバーを増やす」 → 「(なんとなく)直った気がする」
この 負の成功体験 を断ち切るには、
経験や勘ではなく、データに基づいた冷徹な判断プロセス が不可欠となる。
3. 中心思想|New Relic を「判断体系」として使う
New Relic の真価は、単体の CPU 使用率を見ることではない。
「アプリケーション(APM)」と「インフラ(Infrastructure)」を、同一時間軸で重ねて観測できる点 にある。
本記事では、以下の 3 層チェック を「判断体系」として定義する。
拡張可否の判断ステップ
-
APM(事実確認)
- スループットは増えているか? レスポンスは本当に悪化しているか?
-
インフラ(リソース確認)
- CPU / メモリ / I/O は本当に枯渇しているか?
-
相関確認(因果の特定)
- 性能劣化とリソース使用率は「連動」しているか?
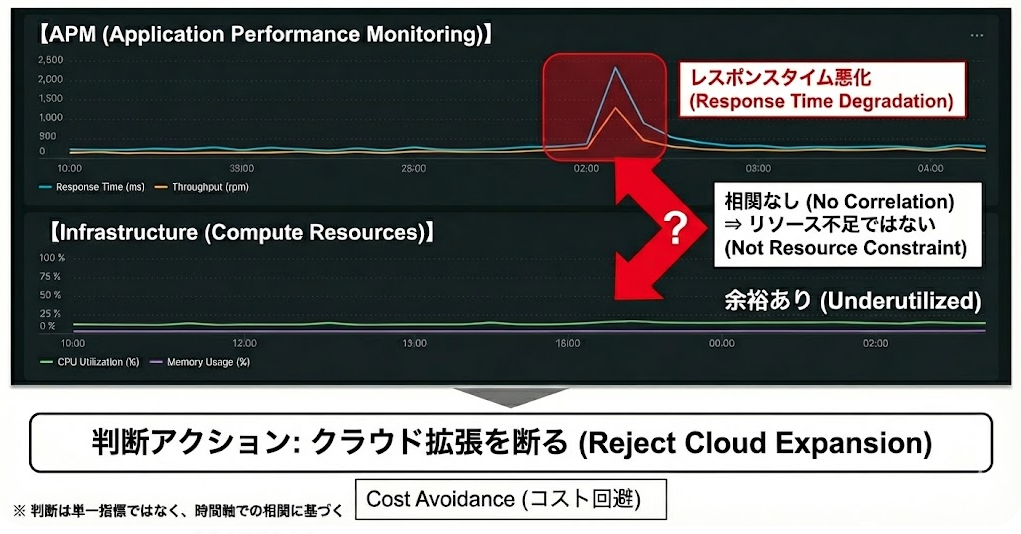
ここが重要
CPU 使用率が低いこと自体は問題ではない。
「APM が悪化しているのにインフラが余裕な状態」を見逃し、無意味な拡張を行うこと が最大の問題である。
この体系を用いれば、
「今、拡張すべきか」「それは無意味か」を、Yes / No で即答 できる。
4. 実践|Magento on AWS 構成での判断フロー適用例
ここからは、前章で定義した 判断体系 を、
AWS 上に構築された Magento 推奨構成ベースの EC サイト に適用する。
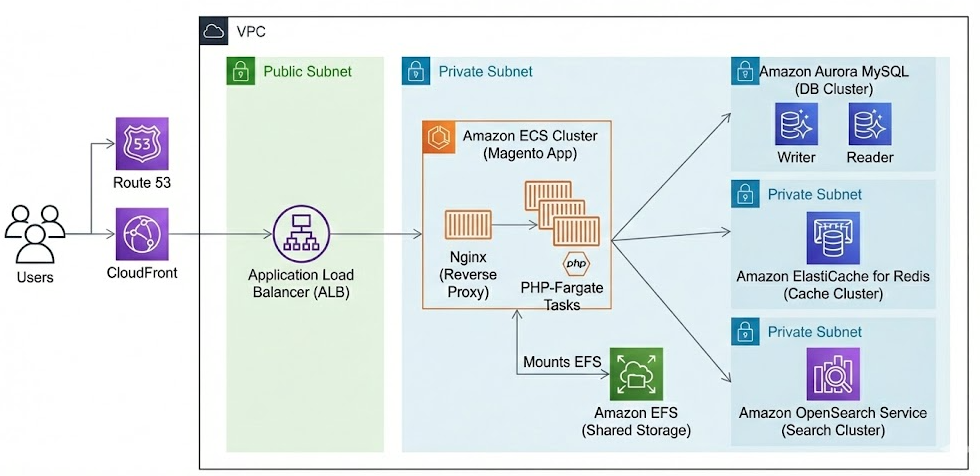
対象システム構成(AWS × Magento)
本記事で想定する構成は、エンタープライズ領域で一般的な以下の構成であり、
特定の企業や環境に依存しない汎用モデル である。
- Application: Amazon ECS(Fargate)上の PHP(Magento)コンテナ
- Database: Amazon Aurora MySQL
- Cache: Amazon ElastiCache for Redis
- Search: Amazon OpenSearch Service
本構成は、Adobe Commerce(Magento)の公式システム要件に準拠している。
想定シナリオ|正体不明の「重い」
- 特定時間帯に「ページ表示が遅い」という報告が上がる
- New Relic APM 上でもレスポンスタイムのスパイク(急増)が確認される
- 現場では「とりあえずスケールアウトしよう」という声が上がる
この瞬間こそ、判断体系の出番である。
Step 1|APM で「負荷の実在」を確認する
最初に確認すべきはインフラではない。
「ユーザー体験が本当に悪化しているか」 という事実だ。

解説: 左のグラフ(Throughput)を見ると、午前7時から9時にかけてリクエスト数が約6倍に急増している。
一方、右のグラフ(Response Time)を確認すると、レスポンスタイムの悪化(スパイク)は確認できるものの、スループットの激増と比較すれば、システム全体の破綻には至っていない。
この段階で、「負荷増に伴うレスポンス変動が発生している(が、ダウンはしていない)」 という事実を確定させる。
Step 2|ECS のリソース枯渇を確認する
次に、Step 1 と 同一時間帯 の ECS リソースを確認する。
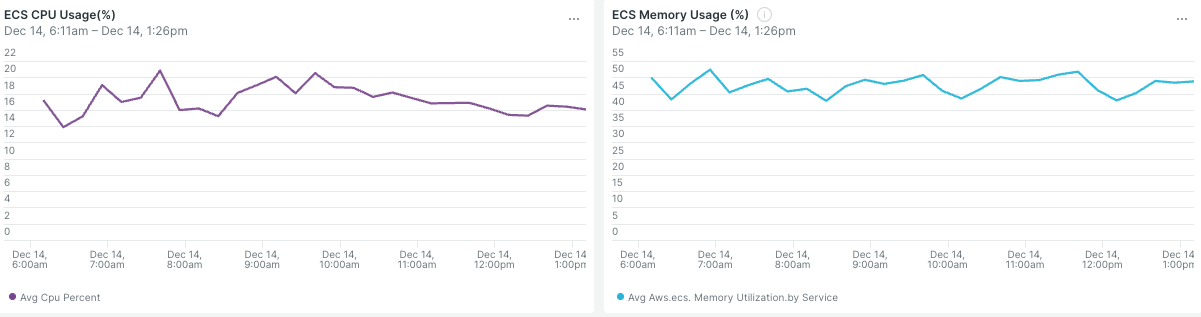
解説: APM上ではトラフィックが急増していたが、CPU使用率は 20% 以下 で推移している。
ここから導かれる事実は一つだ。
「アプリケーションは悲鳴を上げているが、サーバーは暇を持て余している」
この時点で、Compute(ECS)の拡張は無意味 であることが確定する。
Step 3|Aurora / Redis / OpenSearch の横断確認
「Webサーバーでないならバックエンドか?」を検証する。

解説:
- Redis (左上): CPU使用率は数%。Eviction(メモリ不足)も皆無。
- RDS (左下): トラフィック増に追従しているが、CPU 50% 以下と健全。
- OpenSearch (右下): CPU 1桁%台。検索負荷も問題ない。
いずれのレイヤーにも、拡張が必要なボトルネック(飽和)は存在しない。
Step 4|判断|クラウド拡張を「断る」
以上のファクトを整理し、結論を出す。
- APM: 性能変動あり(事実)
- インフラ: 全レイヤーでリソース余裕あり(事実)
- 相関: なし(No Correlation)
この性能問題は、クラウド拡張(金)では解決しない。
したがって、SRE として下すべき正しい判断は、
「クラウド拡張を行わない(Reject)」 である。
Next Action
拡張を断ることは、放置することではない。
問題は「インフラ容量」ではないため、次のアクションは APM の Transaction Trace を用いた 「アプリケーション内部(コード・クエリ・ロック)」の分析 へと舵を切る。
5. 判断の核心|時間軸で見る「相関」の有無
最終的な意思決定を支えるのは、単一のグラフではない。
同一時間軸での相関(Correlation) である。
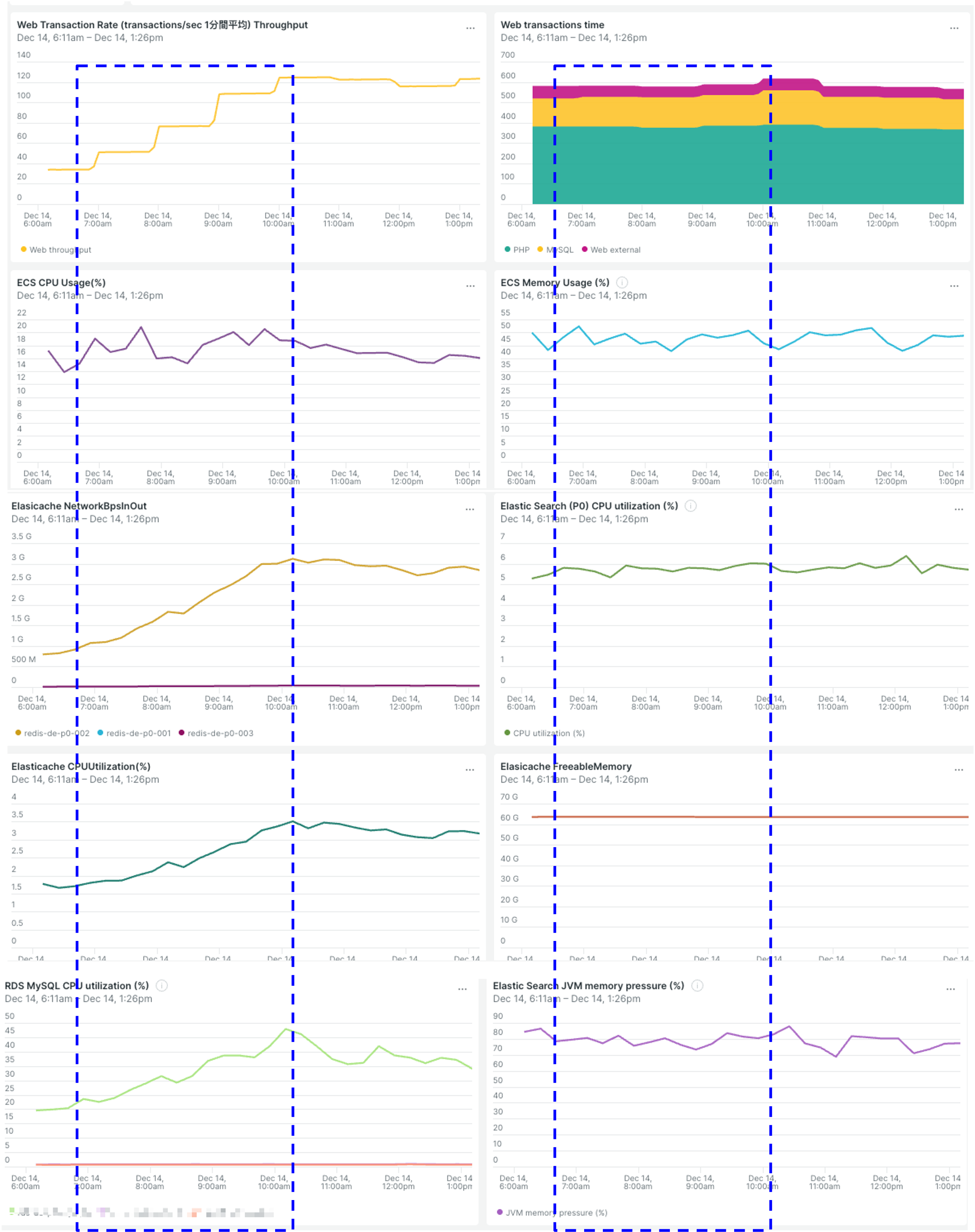
この図の 青い点線枠 に注目してほしい。
- 上段(APM): トラフィック(黄色)は階段状に急増している。
- 中・下段(Infra): しかし、その直下の CPU やメモリは 驚くほど無反応(フラット) だ。
相関が存在しない以上、拡張は「対症療法」にすらならない。
この可視化こそが、ステークホルダーに対して「拡張しない」と説明するための最強の根拠となる。
補足|「拡張すべき」ケースも、この判断体系は見逃さない
本記事では「拡張を断る」判断を中心に解説してきたが、
本判断体系は 拡張を否定するものではない。
例えば、APM の性能劣化とインフラリソースの枯渇が
同一時間軸で明確に相関する場合 は、話が別だ。
- ECS: CPU / Memory が上限(Limit)に張り付いている
- Database: CPU / I/O Wait がトラフィック増と同時に急増している
- Middleware: Redis Eviction や OpenSearch JVM Pressure が発生している
この相関が確認できた場合、クラウド拡張は
「対症療法」ではなく、「合理的な解決策(正当な投資)」となる。
重要なのは、「拡張するか/しないか」という結果ではない。
「相関を根拠に、その判断を説明できるか」 である。
6. 高負荷イベントにおける判断モデル(Scenario)
本章で示すのは、新たな判断軸ではない。
これまで解説してきた 「判断体系」 を、
最も失敗しやすい高負荷イベント(大規模セール・キャンペーン) に適用した場合の、実践的な運用モデルである。
本判断体系が真価を発揮するのは、平常時だけではない。
エンジニアが最もプレッシャーを感じる「負荷急増時」こそ、この判断の羅針盤が必要となる。
ここでは、イベント運用における 「安定性」と「コスト」のバランス を崩さないための考え方を整理する。
事前|「恐怖」ではなく「実績」で積むマージン
イベント前のサイジングにおいて、最もコストを跳ね上げる要因は 「恐怖(Fear)」 である。
「落ちたらどうしよう」という不安が、根拠のない「念のための10倍構成」を生む。
- Bad: 不安だから、とりあえず過去最大構成のさらに倍を用意する(根拠なし)
- Good: New Relic の過去データ(Baseline)に基づき、過去のピークトラフィックに対して「一定の安全係数」を加味したサイジングを行う。(例:直近ピーク実績に対し 1.x 倍 程度のマージン)
過剰な保険は、利益を食いつぶす。
APM の実績データがあれば、必要なマージンは数学的に算出できる。
事中|迷いを断ち切る「即断即決」
アクセスが集中し、レスポンスが悪化したその瞬間。
現場がパニックになりかける時こそ、判断体系(3層チェック)を回す。
- APM: 本当にユーザー体験が悪化しているか?(Fact)
- Infra: リソースは枯渇しているか?(Fact)
- 相関: 両者は連動しているか?(Fact)
このフローを徹底することで、
「今は拡張すべきか/すべきでないか」を、会議なしで即断 できる。
迷っている間にログを漁るのではなく、ダッシュボードの「形」を見て 1分で判断する。
これが SRE の仕事である。
事後|「様子見」という名の浪費を排除する
イベント終了後、多くの現場で起きるのが 「コストの垂れ流し」 だ。
「念のため明日の朝までこのままにしておこう」という判断は、一見安全に見えて、実は最もコスト効率が悪い。
- レスポンスが平常値に戻った
- リソース使用率が低下した
この 2 点が確認できた時点で、即座にスケールイン(縮退) を行う。
「一晩の様子見」のコスト
m5.24xlarge クラスのクラスタを一晩(12時間)余分に放置するコストは、決して安くない。
「安全確認」ではなく「即時回収」こそが、利益を守る最後のアクションである。
7. 価値の本質|削減額ではなく「回避額(Cost Avoidance)」
本判断体系がもたらす価値は、Cost Reduction(削減) ではなく、
Cost Avoidance(回避) にある。
負荷が予測可能で、システムが安定している前提においては、
潜在的なクラウドコスト増加の 20〜30% を回避できる可能性がある。
※ 本数値は、以下のシナリオを前提とした経験則に基づく試算である:
- ピーク維持: ピーク対応の ECS タスク数やインスタンスサイズが、通常時にも維持されるケース
- 安全マージン: 平均利用率とピーク利用率の乖離(過剰なバッファの積み上がり)
- 期間要因: 不要なスケールアウトやスペック変更が、一定期間継続した場合
つまり、「拡張してしまった後、設定を戻さない(戻せない)」時間が長いほど、この回避効果は大きくなる。
これは、New Relic の利用コストを十分に上回る価値だ。
8. まとめ|「拡張する勇気」より「断る根拠」
本記事で紹介したのは、テクニック集ではない。
クラウドコストと向き合うための判断体系 である。
- 感覚ではなく、事実で判断する
- 単体指標ではなく、相関で判断する
- 拡張する前に、「断る理由」を探す
New Relic の本当の価値は、
「お金を使わない判断」を、技術的に正当化できる点 にある。
クラウドコスト最適化とは、削ることではない。
正しく判断すること である。