SRGAN
SRGANとは画像の解像度を上げるニューラルネットワークを使ったアルゴリズムであり、今回はそれを実装してみました。
参考
https://qiita.com/pacifinapacific/items/ec338a500015ae8c33fe
https://buildersbox.corp-sansan.com/entry/2019/04/29/110000
とりあえず実装
github https://github.com/AokiMasataka/Super-resolution
データセットはかなり前に作ったSRResNetと同じものを使用します。
SResNetの記事
https://qiita.com/AokiMasataka/items/3d382310d8a78f711c71
ネットワークはPyTorchの練習を兼ねてPyTorchでの実装となります。
SRGANのGeneratorのネットワークはResNet+Pixcelshufferで構成されます.
コードで書くとこうなります。
class ResidualBlock(nn.Module):
def __init__(self, nf=64):
super(ResidualBlock, self).__init__()
self.Block = nn.Sequential(
nn.Conv2d(nf, nf, kernel_size=3, padding=1),
nn.BatchNorm2d(nf),
nn.PReLU(),
nn.Conv2d(nf, nf, kernel_size=3, padding=1),
nn.BatchNorm2d(nf),
)
def forward(self, x):
out = self.Block(x)
return x + out
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=9, padding=4)
self.relu = nn.PReLU()
self.residualLayer = nn.Sequential(
ResidualBlock(),
ResidualBlock(),
ResidualBlock(),
ResidualBlock(),
ResidualBlock()
)
self.pixelShuffle = nn.Sequential(
nn.Conv2d(64, 64*4, kernel_size=3, padding=1),
nn.PReLU(),
nn.PixelShuffle(2),
nn.Conv2d(64, 3, kernel_size=9, padding=4),
nn.Tanh()
)
def forward(self, x):
x = self.conv1(x)
skip = self.relu(x)
x = self.residualLayer(skip)
x = self.pixelShuffle(x + skip)
return x
Discriminatorは何の変哲もない畳み込みネットワークを使用します。
引数のsizeは画像の縦横のサイズです、今回は入力画像のサイズは64x64にしています。
class Discriminator(nn.Module):
def __init__(self, size=64):
super(Discriminator, self).__init__()
size = int(size / 8) ** 2
self.net = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, padding=1),
nn.LeakyReLU(0.2),
nn.Conv2d(32, 32, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(32),
nn.LeakyReLU(0.2),
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2),
nn.Conv2d(64, 64, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2),
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2),
nn.Conv2d(128, 128, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2),
Flatten(),
nn.Linear(128 * size, 1024),
nn.LeakyReLU(0.2),
nn.Linear(1024, 1)
)
def forward(self, x):
return self.net(x)
class Flatten(nn.Module):
def forward(self, x):
return x.view(x.shape[0], -1)
Generator loss
GeneratorのlossにはVgglossを使います、vgglossはmselossが画像のピクセルの平均をlossとするのに対し、学習済みのvggモデルのレイヤーを通して、その特徴量の平均をlossとすることでより鮮明な画像を生成させます。
class VGGLoss(nn.Module):
def __init__(self):
super(VGGLoss, self).__init__()
vgg = models.vgg16(pretrained=True)
self.contentLayers = nn.Sequential(*list(vgg.features)[:31]).cuda().eval()
for param in self.contentLayers.parameters():
param.requires_grad = False
def forward(self, fakeFrame, frameY):
MSELoss = nn.MSELoss()
content_loss = MSELoss(self.contentLayers(fakeFrame), self.contentLayers(frameY))
return content_loss
このcontent_lossにDiscriminatorの出力によるBCELossを足したものをGeneratorのlossとしています。
これらを踏まえtrain関数を作っていきます
def train(loader):
tensor_x, tensor_y = torch.tensor(x, dtype=torch.float), torch.tensor(y, dtype=torch.float)
DS = TensorDataset(tensor_x, tensor_y)
loader = DataLoader(DS, batch_size=BATCH_SIZE, shuffle=True)
D.train()
G.train()
D_optimizer = torch.optim.Adam(D.parameters(), lr=DiscriminatorLR, betas=(0.9, 0.999))
G_optimizer = torch.optim.Adam(G.parameters(), lr=GeneratorLR, betas=(0.9, 0.999))
realLabel = torch.ones(BATCH_SIZE, 1).cuda()
fakeLabel = torch.zeros(BATCH_SIZE, 1).cuda()
BCE = torch.nn.BCELoss()
VggLoss = VGGLoss()
for batch_idx, (X, Y) in enumerate(loader):
if X.shape[0] < BATCH_SIZE:
break
X = X.cuda()
Y = Y.cuda()
fakeFrame = G(X)
D.zero_grad()
DReal = D(Y)
DFake = D(fakeFrame)
D_loss = (BCE(DFake, fakeLabel) + BCE(DReal, realLabel)) / 2
D_loss.backward(retain_graph=True)
D_optimizer.step()
G.zero_grad()
G_label_loss= BCE(DFake, realLabel)
G_loss = VggLoss(fakeFrame, Y) + 1e-3 * G_label_loss
G_loss.backward()
G_optimizer.step()
print("G_loss :", G_loss, " D_loss :", D_loss)
32epoch学習させた結果が下の画像です。上が縮小した画像で、真ん中がSRGANでの出力、一番下がオリジナルの画像です。
精度としては悪くない感じ、

ESRGAN
SRGANとの違い
RRDN(Residual in Residual Dense Network)
・バッチ正規化を取り除くことによって生成能力が上がるらしい
・DenseBlockはレイヤーの出力を全てのレイヤの入力に加える
・さらにDenseBlockをResNetの要領で三つ連結させる
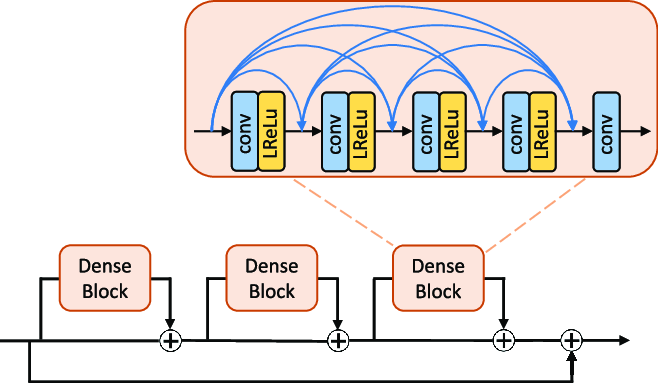
実装するとこんな感じ
class ResidualDenseBlock(nn.Module):
def __init__(self, nf=64, gc=32, bias=True):
super(ResidualDenseBlock, self).__init__()
self.conv1 = nn.Conv2d(nf, gc, 3, padding=1, bias=bias)
self.conv2 = nn.Conv2d(nf + gc, gc, 3, padding=1, bias=bias)
self.conv3 = nn.Conv2d(nf + 2 * gc, gc, 3, padding=1, bias=bias)
self.conv4 = nn.Conv2d(nf + 3 * gc, gc, 3, padding=1, bias=bias)
self.conv5 = nn.Conv2d(nf + 4 * gc, nf, 3, padding=1, bias=bias)
self.lrelu = nn.LeakyReLU(negative_slope=0.2, inplace=True)
def forward(self, x):
x1 = self.lrelu(self.conv1(x))
x2 = self.lrelu(self.conv2(torch.cat((x, x1), dim=1)))
x3 = self.lrelu(self.conv3(torch.cat((x, x1, x2), dim=1)))
x4 = self.lrelu(self.conv4(torch.cat((x, x1, x2, x3), dim=1)))
x5 = self.conv5(torch.cat((x, x1, x2, x3, x4), dim=1))
return x5 * 0.2 + x
class Generator(nn.Module):
def __init__(self, nf=64):
super(Generator, self).__init__()
self.conv1 = nn.Conv2d(3, nf, kernel_size=3, padding=1)
self.relu = nn.LeakyReLU(negative_slope=0.2, inplace=True)
self.blockLayer = nn.Sequential(
ResidualDenseBlock(),
ResidualDenseBlock(),
ResidualDenseBlock(),
)
self.pixelShuffle = nn.Sequential(
nn.Conv2d(nf, nf * 4, kernel_size=3, padding=1),
nn.LeakyReLU(negative_slope=0.2, inplace=True),
nn.PixelShuffle(2),
nn.Conv2d(nf, nf, kernel_size=3, padding=1),
nn.Conv2d(nf, 3, kernel_size=3, padding=1),
nn.Tanh()
)
Relativistic GAN
SRGANの識別機では本物を1偽物を0と出力するように学習させるが、Relativistic GANでは本物の画像と偽物の画像を比較し、その差とラベルをBCElossとしています。
参考
https://github.com/Yagami360/MachineLearning-Papers_Survey/issues/51
VGG Perceptual Loss
SRGANではVGG16を使い特徴量を抽出していましたが、PerceptualLossではVGG16のpoolingレイヤーごとのL1_lossを足し合わせる構造になっています。
ざっと書くとこんな感じ
class VGGPerceptualLoss(torch.nn.Module):
def __init__(self):
super(VGGPerceptualLoss, self).__init__()
blocks = []
blocks.append(models.vgg16(pretrained=True).features[:4].eval())
blocks.append(models.vgg16(pretrained=True).features[4:9].eval())
blocks.append(models.vgg16(pretrained=True).features[9:16].eval())
blocks.append(models.vgg16(pretrained=True).features[16:23].eval())
blocks.append(models.vgg16(pretrained=True).features[23:30].eval())
for bl in blocks:
for p in bl:
p.requires_grad = False
self.blocks = torch.nn.ModuleList(blocks).cuda()
self.mean = torch.nn.Parameter(torch.tensor([0.485, 0.456, 0.406]).view(1, 3, 1, 1), requires_grad=False).cuda()
self.std = torch.nn.Parameter(torch.tensor([0.229, 0.224, 0.225]).view(1, 3, 1, 1), requires_grad=False).cuda()
def forward(self, fakeFrame, frameY):
fakeFrame = (fakeFrame - self.mean) / self.std
frameY = (frameY - self.mean) / self.std
loss = 0.0
x = fakeFrame
y = frameY
for block in self.blocks:
x = block(x)
y = block(y)
loss += torch.nn.functional.l1_loss(x, y)
return loss
学習結果
上が縮小した画像で、真ん中がESRGANでの出力、一番下がオリジナルの画像
SRGANと同じく32epochで32pxを64pxにアップスケールしてあります。

生成画像を上下に並べて比較してみます、上がSRGANで下がESRGANです。SRGANではノイズが目立ちますがESRGANではノイズは少なく、全体のの輪郭がSRGANに比べはっきりしています。

