SRGANをpytorchで実装してみました。上段が元画像、中段がbilinear補完したもの、下段が生成結果です。

ipynbのコードをgithubにあげました
SRGANとは
SRGANはDeepLearningを用いた超解像のアルゴリズムです。
超解像とはその名の通り、低解像度画像を高解像度の画像に変換する技術です。
元論文では下図のようにoriginal画像と見分けがつかないレベルの生成を行なっています(論文Fig2)。それまで一般的に使われていたbicubic補完と比べても一目瞭然ですね。
より引用")
SRGANのネットワーク
SRGANのネットワークは下のようになっています。(論文Fig4)
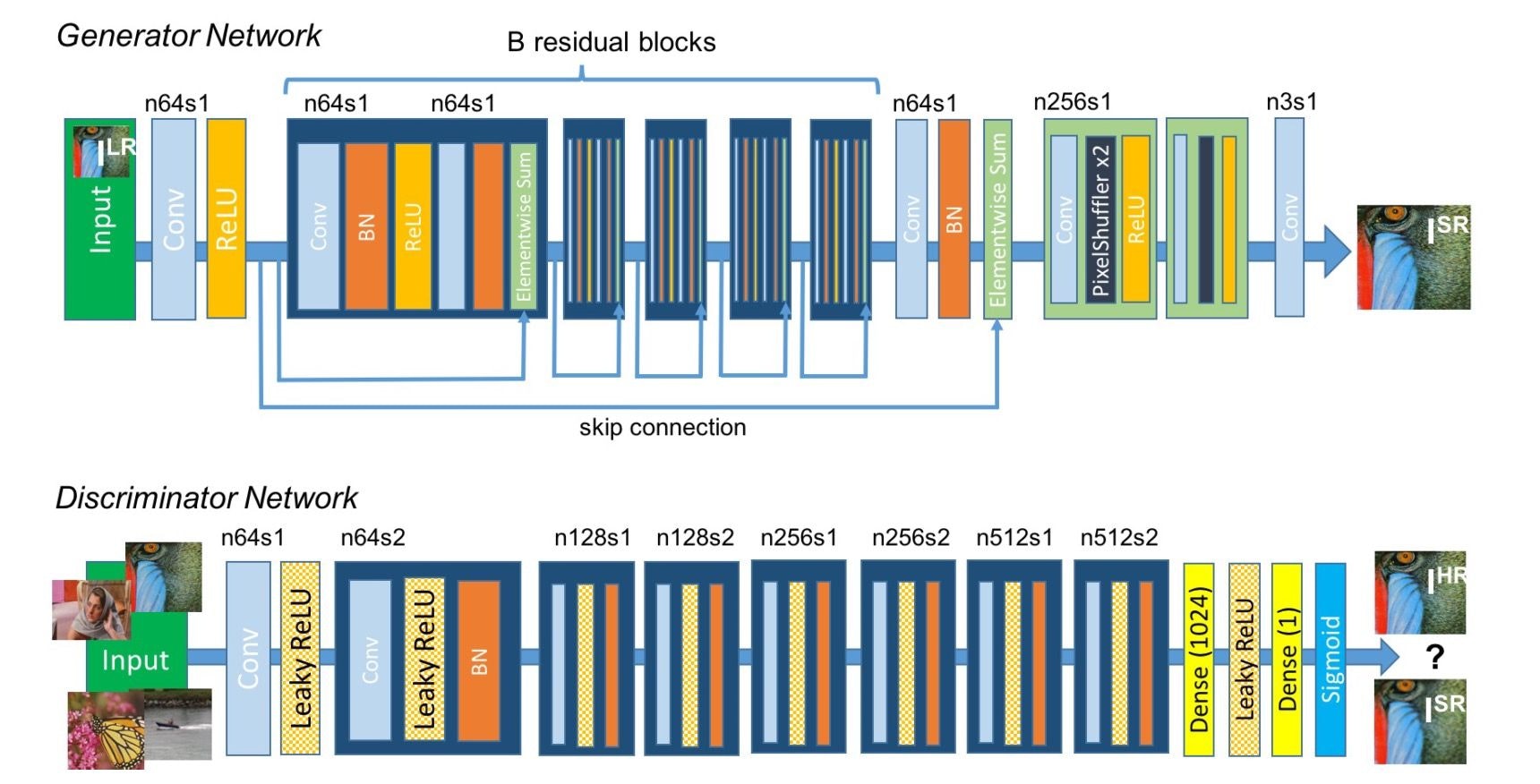
特徴としてはGANを用いて敵対的な学習を可能にしていることと、GeneratorにResNetを用いていることです。ResNetのスキップが細かい特徴を維持しやすくしているということでしょうか?ここらへんは難しいですね。
SRGANの学習
今回、SRGANは2ステップに分けて学習させます。1つめはSRResNet(Generator)のみを用いて、損失関数にMSEを用いて学習。2つ目はG,Dを両方用いて敵対的に学習させます。
それぞれ見ていきます。
pytorch実装
ネットワークの前に、まずデータの読み込みを準備しておきましょう。
超解像の学習は用意した高解像のデータ(今回は256×256)と、そのデータをダウンサンプリングした画像(64×64)をペアにして学習させます。これはpytorchのImageFolderを拡張させることで作れます。
class DownSizePairImageFolder(ImageFolder):
def __init__(self, root, transform=None, large_size=256, small_size=64, **kwds):
super().__init__(root, transform=transform, **kwds)
self.large_resizer = transforms.Scale(large_size)
self.small_resizer = transforms.Scale(small_size)
def __getitem__(self, index):
path, _ = self.imgs[index]
img = self.loader(path)
large_img = self.large_resizer(img)
small_img = self.small_resizer(img)
if self.transform is not None:
large_img = self.transform(large_img)
small_img = self.transform(small_img)
return small_img, large_img
このようにしてあげることで低解像度画像と高解像度画像をペアにして読み込むことができるようになります。
あとはこれをおなじみのDataLoaderで読み込みます.
今回はlfwの顔画像を学習に使用させていただきました
train_data = DownSizePairImageFolder('./lfw-deepfunneled/train', transform=transforms.ToTensor())
test_data = DownSizePairImageFolder('./lfw-deepfunneled/test', transform=transforms.ToTensor())
batch_size = 8
train_loader = DataLoader(train_data, batch_size, shuffle=True)
test_loader = DataLoader(test_data, batch_size, shuffle=False)
これで
images_lr, images_hr =iter(train_loader).next()
のようにtrain_loadeを1度読み込むことで[batch_size,3,64,64]の低解像度画像と[batch_size,3,256,256]の高解像度画像を取得できます。
それではGeneratorのモデルを書いていきます。
ResNetのためのResidualBlockとPixcelshufferのクラスをあらかじめ準備しておきます。
Pixcelshufferに関してはこれが詳しい
pytorchではnn.PixelShuffle(r),のように使えます。rは倍率でr=2とすると画像は2倍の大きさになります。
class ResidualBlock(nn.Module):
def __init__(self,input_channel):
super(ResidualBlock,self).__init__()
self.residualblock=nn.Sequential(
nn.Conv2d(input_channel,input_channel,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(input_channel),
nn.PReLU(),
nn.Conv2d(input_channel,input_channel,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(input_channel))
def forward(self,x):
residual=self.residualblock(x)
return x+residual
class Pixcelshuffer(nn.Module):
def __init__(self,input_channel,r): #r=upscale_factor
super(Pixcelshuffer,self).__init__()
self.layer=nn.Sequential(
nn.Conv2d(input_channel,256,kernel_size=3,stride=1,padding=1),
nn.PixelShuffle(r),
nn.PReLU())
def forward(self,x):
return self.layer(x)
そしてGのモデル
class Generator(nn.Module):
def __init__(self,image_size):
super(Generator,self).__init__()
self.image_size=image_size
self.pre_layer=nn.Sequential(
nn.Conv2d(3,64,kernel_size=9,stride=1,padding=4),
nn.PReLU())
self.residual_layer=nn.Sequential(
ResidualBlock(64),
ResidualBlock(64),
ResidualBlock(64),
ResidualBlock(64),
ResidualBlock(64))
self.middle_layer=nn.Sequential(
nn.Conv2d(64,64,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(64))
self.pixcelshuffer_layer=nn.Sequential(
Pixcelshuffer(64,2),
Pixcelshuffer(64,2),
nn.Conv2d(64,3,kernel_size=9,stride=1,padding=4))
def forward(self,input_image):
pre=self.pre_layer(input_image)
res=self.residual_layer(pre)
middle=self.middle_layer(res)
middle=middle+pre
output=self.pixcelshuffer_layer(middle)
return output
準備したResidualBlockとPixcelshufferをforwardで繋げていきます。
最終的な出力は
test_input=torch.ones(1,3,64,64)
g=Generator(64)
if cuda:
test_input=test_input.cuda()
g=g.cuda()
out=g(test_input)
print(out.size())
# torch.Size([1, 3, 256, 256])
で確認できます。ちゃんと256×256になっているのがわかりますね。これができるのがpytorchの良いところ。
1ステップ目はDを使わないので1ステップ目の学習コードも書いてしまいます。
def MSE_Loss(generated_image,hr_image):
mse_loss=nn.MSELoss()
image_loss=mse_loss(generated_image,hr_image)
return image_loss
LossはMSEを使います。Gの生成した画像と高解像度画像を比較して計算。
G=Generator(64)
# D=Discriminator()
if cuda:
G=G.cuda()
#D=D.cuda()
#g_param=torch.load("asset/G.pth")
#G.load_state_dict(g_param)
G_optimizer=optim.Adam(G.parameters(),lr=0.0001,betas=(0.9,0.999))
# D_optimizer=optim.Adam(D.parameters(),lr=0.0001,betas=(0.9,0.999))
# d_loss=nn.BCELoss()
optimizerなどを定義します。コメントアウトしている箇所は後ほど使うところです。
そして学習用のコード
def first_train(epoch):
G.train()
G_loss=0
for batch_idx,(data_lr,data_hr)in enumerate(train_loader):
if data_lr.size()[0]!=batch_size:
break
if cuda:
data_lr=data_lr.cuda()
data_hr=data_hr.cuda()
fake_image=G(data_lr)
G.zero_grad()
G_loss=MSE_Loss(fake_image,data_hr)
G_loss.backward()
G_optimizer.step()
G_loss+=G_loss.data[0]
G_loss/=len(train_loader)
g_image=fake_image.data.cpu()
hr_image=data_hr.data.cpu()
HR_image=torch.cat((hr_image,g_image),0)
save_image(HR_image,"save_image/epoch_{}.png".format(epoch))
print("save_image")
return G_loss
num_epoch=100
for epoch in range(1,num_epoch+1):
if epoch==1:
print("trainning start!!")
g_loss_=first_train(epoch)
if epoch%1==0:
torch.save(G.state_dict(),"asset/G_first_epoch{}.pth".format(epoch))
低解像度画像(data_lr)をGに通し高解像度画像(data_hr)とのMSEを計算してGを学習させます。これが1つ目のステップでepoch200回ほど回しました。
最終的な画像がこちら

上段が高解像度画像、下段がGの出力した画像です。まだぼやけた画像になっていますね。このぼやけをDを使ったGANによる学習で取り除いていきます。
Dの実装
いよいよSRGANのGANの部分を実装していきます。しかしD自体はそこまでむずかしくはありません。おなじみのGANのように入力を[batch_size,3,256,256],最終的な出力が[batch_size,1]となるようにするだけです。
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator,self).__init__()
self.conv_layers=nn.Sequential(
nn.Conv2d(3,64,kernel_size=3,stride=1,padding=1),
nn.LeakyReLU(0.2),
nn.Conv2d(64,64,kernel_size=3,stride=2,padding=1),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2),
nn.Conv2d(64,128,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2),
nn.Conv2d(128,128,kernel_size=3,stride=2,padding=1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2),
nn.Conv2d(128,256,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
nn.Conv2d(256,256,kernel_size=3,stride=2,padding=1),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
nn.Conv2d(256,512,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.2),
nn.Conv2d(512,512,kernel_size=3,stride=2,padding=1),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.2))#(512,16,16)
self.dense_layer=nn.Sequential(
nn.Linear(16*16*512,1024),
nn.LeakyReLU(0.2),
nn.Linear(1024,1),
nn.Sigmoid())
def forward(self,input_image):
batch_size=input_image.size()[0]
conv=self.conv_layers(input_image)
reshape=conv.view(batch_size,-1)
output=self.dense_layer(reshape)
return output
これも同様に出力の次元を確認しておきましょう
test_input=torch.ones(1,3,256,256)
d=Discriminator()
if cuda:
test_input=test_input.cuda()
d=d.cuda()
out=d(test_input)
print(out.size())
# torch.Size([1, 1])
次に損失関数です。Dの損失関数はいつものGANのCross Entropyですが、
Gの損失関数は少し特殊で、VGGにそれぞれの画像を通した時の中間層の値をMSEで計算します。こうすることで普通のMSEで平均した(ぼやけた)出力をするのを防ぐそうです。
さらにGANのlossとしてadversarial_lossを加えます。
これはGで生成した画像がDを騙すほど損失は小さくなるのでGがDを騙すようにぼやけた画像ではなく、くっきりとした画像をつくるのに寄与します。比は1:0.001
実装はこんな感じ。
def generator_loss(generated_image,hr_image,d_label,t_label):
vgg=vgg16(pretrained=True)
content_layers=nn.Sequential(*list(vgg.features)[:31]).cuda().eval()
for param in content_layers.parameters():
param.requires_grad=False
mse_loss=nn.MSELoss()
content_loss=mse_loss(content_layers(generated_image),content_layers(hr_image))
BCE_loss=nn.BCELoss()
adversarial_loss=BCE_loss(d_label,t_label)
return content_loss+0.001*adversarial_loss
Dを定義したのでさきほどコメントアウトしていた箇所のコメントを外しましょう。Gは1ステップ目に学習させた重みを読みこんでおきます。(重みファイルの名前は適時変更)
G=Generator(64)
D=Discriminator()
if cuda:
G=G.cuda()
D=D.cuda()
g_param=torch.load("asset/G.pth")
G.load_state_dict(g_param)
G_optimizer=optim.Adam(G.parameters(),lr=0.0001,betas=(0.9,0.999))
D_optimizer=optim.Adam(D.parameters(),lr=0.0001,betas=(0.9,0.999))
d_loss=nn.BCELoss()
そしていよいよ最後の学習コード
def train(epoch):
D.train()
G.train()
y_real=torch.ones(batch_size,1)
y_fake=torch.zeros(batch_size,1)
if cuda:
y_real=y_real.cuda()
y_fake=y_fake.cuda()
D_loss=0
G_loss=0
for batch_idx,(data_lr,data_hr)in enumerate(train_loader):
if data_lr.size()[0]!=batch_size:
break
if cuda:
data_lr=data_lr.cuda()
data_hr=data_hr.cuda()
print(batch_idx)
D.zero_grad()
D_real=D(data_hr)
D_real_loss=d_loss(D_real,y_real)
fake_image=G(data_lr)
D_fake=D(fake_image)
D_fake_loss=d_loss(D_fake,y_fake)
D_loss=D_real_loss+D_fake_loss
D_loss.backward(retain_graph=True)
D_optimizer.step()
D_loss+=D_loss.data[0]
G.zero_grad()
G_loss=generator_loss(fake_image,data_hr,D_fake,y_real)
print(G_loss,D_loss)
G_loss.backward()
G_optimizer.step()
G_loss+=G_loss.data[0]
D_loss/=len(train_loader)
G_loss/=len(train_loader)
if batch_idx%10==0:
g_image=fake_image.data.cpu()
hr_image=data_hr.data.cpu()
HR_image=torch.cat((hr_image,g_image),0)
save_image(HR_image,"save_image/epoch_cont_{}.png".format(epoch))
print("save_image")
return D_loss,G_loss
num_epoch=10000
for epoch in range(1,num_epoch+1):
if epoch==1:
print("trainning start!!")
d_loss_,g_loss_=train(epoch)
if epoch%40==0:
#generate_image(epoch)
torch.save(G.state_dict(),"asset/G_2nd_epoch{}.pth".format(epoch))
torch.save(D.state_dict(),"asset/D_2nd_epoch{}.pth".format(epoch))
500epochほど回したのが冒頭の画像になります。
学習時間はGoogle Collaboratory上で6時間ほどだったかと思います。
長かったですが以上です。個人的にGANは面白いアルゴリズムですし、結構驚きの結果もでるので大好きです。もっといろんなGANを実装したいとおもいました。
最後に
つたないコードに加え、駆け足で記事を書いたので間違いがあるかもしれません。そのときはコメントなどで指摘してくださると幸いです。